







本文并非原创,只是个人的学习的笔记,作者只对一些步骤进行了简单的推导。具体内容请参考:
https://lilianweng.github.io/posts/2021-07-11-diffusion-models/
https://www.bilibili.com/video/BV1b541197HX?share_source=copy_web
参数重整化
若希望从高斯分布 N ( μ , σ 2 ) N(μ,σ^2) N(μ,σ2)中采样,可以先从标准分布 N ( 0 , 1 ) N(0,1) N(0,1)采样出 z z z,再得到 σ ∗ z + μ σ*z+μ σ∗z+μ。这样做的好处是将随机性转移到了 z z z这个常量上,而 σ σ σ和 μ μ μ则当做放射变换网络的一部分。
前向扩散过程
从真实数据中采样一个数据点
x
0
x_0
x0,满足分布
x
0
∼
q
(
x
)
x_0 \sim q(x)
x0∼q(x)。让我们定义一个前向传播过程,在该过程中我们通过T步不断地向样本点中添加小量的高斯噪声,生成了一个噪声样本序列
x
1
,
x
2
,
…
,
x
T
x_1,x_2,\dots,x_T
x1,x2,…,xT。步长的大小是通过一个方差集合
{
β
t
∈
(
0
,
1
)
}
t
=
1
t
\{\beta_t∈(0,1)\}^t_{t=1}
{βt∈(0,1)}t=1t控制。
该过程是一个马尔可夫链过程
q
(
x
t
∣
x
t
−
1
)
=
N
(
x
t
;
1
−
β
t
x
t
−
1
,
β
t
I
)
q
(
x
1
:
T
∣
x
0
)
=
∏
t
=
1
T
q
(
x
t
∣
x
t
−
1
)
q(x_t|x_{t-1})=\mathcal {N}(x_t;\sqrt {1-\beta_t} x_{t-1},\beta_t I)\\ q(x_{1:T}|x_0)=\prod^T_{t=1} q(x_t|x_{t-1})
q(xt∣xt−1)=N(xt;1−βtxt−1,βtI)q(x1:T∣x0)=t=1∏Tq(xt∣xt−1)
随着步长变大,数据样本
x
0
x_0
x0逐渐失去其可区分的特征。最终当
T
T
T趋于无穷时,
x
T
x_T
xT的值是一个各项独立的高斯分布。
我们可以使用参数重整化在任意时间步长
t
t
t来逼近样本
x
t
x_t
xt,假设
α
t
=
1
−
β
t
\alpha_t = 1 - \beta_t
αt=1−βt,且
α
‾
t
=
∏
i
=
1
T
α
i
\overline {\alpha}_t = \prod^T_{i=1} \alpha_i
αt=∏i=1Tαi
X
t
=
α
t
X
t
−
1
+
1
−
α
t
Z
t
−
1
X_t = \sqrt{\alpha_t}X_{t-1} + \sqrt{1 - \alpha_t}Z_{t-1}
Xt=αtXt−1+1−αtZt−1
上述过程是我们从
q
(
x
t
∣
x
t
−
1
)
=
N
(
x
t
;
1
−
β
t
x
t
−
1
,
β
t
I
)
q(x_t|x_{t-1})=\mathcal {N}(x_t;\sqrt {1-\beta_t} x_{t-1},\beta_t I)
q(xt∣xt−1)=N(xt;1−βtxt−1,βtI)使用参数重整化得到的,同理我们可以从
q
(
x
t
−
1
∣
x
t
−
2
)
=
N
(
x
t
−
1
;
1
−
β
t
−
1
x
t
−
2
,
β
t
−
1
I
)
q(x_{t-1}|x_{t-2})=\mathcal {N}(x_{t-1};\sqrt {1-\beta_{t-1}} x_{t-2},\beta_{t-1} I)
q(xt−1∣xt−2)=N(xt−1;1−βt−1xt−2,βt−1I)中得到
X
t
−
1
X_{t-1}
Xt−1的值。
X
t
−
1
=
α
t
−
1
X
t
−
2
+
1
−
α
t
−
1
Z
t
−
2
X_{t-1}=\sqrt{\alpha_{t-1}}X_{t-2} + \sqrt{1-\alpha_{t-1}}Z_{t-2}
Xt−1=αt−1Xt−2+1−αt−1Zt−2
将
X
t
−
1
X_{t-1}
Xt−1的值带入到
X
t
X_t
Xt中,可得
X
t
=
α
t
(
α
t
−
1
X
t
−
2
+
1
−
α
t
−
1
Z
t
−
2
)
+
1
−
α
t
Z
t
−
1
=
α
t
α
t
−
1
X
t
−
2
+
α
t
−
α
t
α
t
−
1
Z
t
−
2
+
1
−
α
t
Z
t
−
1
X_t = \sqrt{\alpha_t}(\sqrt{\alpha_{t-1}}X_{t-2} + \sqrt{1-\alpha_{t-1}}Z_{t-2}) + \sqrt{1 - \alpha_t}Z_{t-1}\\ = \sqrt{\alpha_t \alpha_{t-1}}X_{t-2} + \sqrt{\alpha_t -\alpha_t \alpha_{t-1}}Z_{t-2} + \sqrt{1-\alpha_t}Z_{t-1}
Xt=αt(αt−1Xt−2+1−αt−1Zt−2)+1−αtZt−1=αtαt−1Xt−2+αt−αtαt−1Zt−2+1−αtZt−1
其中
Z
t
−
1
,
Z
t
−
2
,
⋯
∼
N
(
0
,
I
)
Z_{t-1},Z_{t-2},\dots \sim \mathcal{N}(0,I)
Zt−1,Zt−2,⋯∼N(0,I)。而且,需要注意两个正态分布
X
∼
N
(
μ
1
,
σ
1
)
X \sim N(μ_1,σ_1)
X∼N(μ1,σ1)和
Y
∼
N
(
μ
2
,
σ
2
)
Y \sim N(μ_2,σ_2)
Y∼N(μ2,σ2)的叠加后的分布
a
X
+
b
Y
aX+bY
aX+bY的均值为
a
μ
1
+
b
μ
2
aμ_1+bμ_2
aμ1+bμ2,方差为
a
2
σ
1
2
+
b
2
σ
2
2
a^2σ_1^2+b^2σ_2^2
a2σ12+b2σ22,所以
α
t
−
α
t
α
t
−
1
Z
t
−
2
+
1
−
α
t
Z
t
−
1
\sqrt{\alpha_t -\alpha_t \alpha_{t-1}}Z_{t-2} + \sqrt{1-\alpha_t}Z_{t-1}
αt−αtαt−1Zt−2+1−αtZt−1可以参数重整化成只含一个随机变量
Z
Z
Z构成的
1
−
α
t
α
t
−
1
Z
\sqrt{1-\alpha_t \alpha_{t-1}}Z
1−αtαt−1Z的形式。
则
X
t
X_t
Xt可以写为
X
t
=
α
t
α
t
−
1
X
t
−
2
+
1
−
α
t
α
t
−
1
Z
‾
t
−
1
X_t = \sqrt{\alpha_t \alpha_{t-1}}X_{t-2} + \sqrt{1-\alpha_t \alpha_{t-1}}\overline{Z}_{t-1}
Xt=αtαt−1Xt−2+1−αtαt−1Zt−1
因为
α
‾
t
=
∏
i
=
1
T
α
i
\overline {\alpha}_t = \prod^T_{i=1} \alpha_i
αt=∏i=1Tαi,
X
t
X_t
Xt最终可写为:
X
t
=
α
‾
t
X
0
+
1
−
α
‾
t
z
X_t = \sqrt{\overline{\alpha}_t}X_0 + \sqrt{1 - \overline{\alpha}_t}z
Xt=αtX0+1−αtz
这样就得到了
q
(
x
t
∣
x
0
)
=
N
(
x
t
;
α
‾
t
x
0
,
(
1
−
α
‾
t
)
I
)
q(x_t|x_0) = \mathcal{N}(x_t; \sqrt{\overline{\alpha}_t}x_0, (1 - \overline{\alpha}_t)I)
q(xt∣x0)=N(xt;αtx0,(1−αt)I)
通常情况下,在样本加噪时我们可以提供一个大的更新步长,即 β 1 < β 2 < ⋯ < β T \beta_1 \lt \beta_2 \lt \dots \lt \beta_T β1<β2<⋯<βT,那么则会有 α ‾ 1 > ⋯ > α ‾ T \overline{\alpha}_1 \gt \dots \gt \overline{\alpha}_T α1>⋯>αT
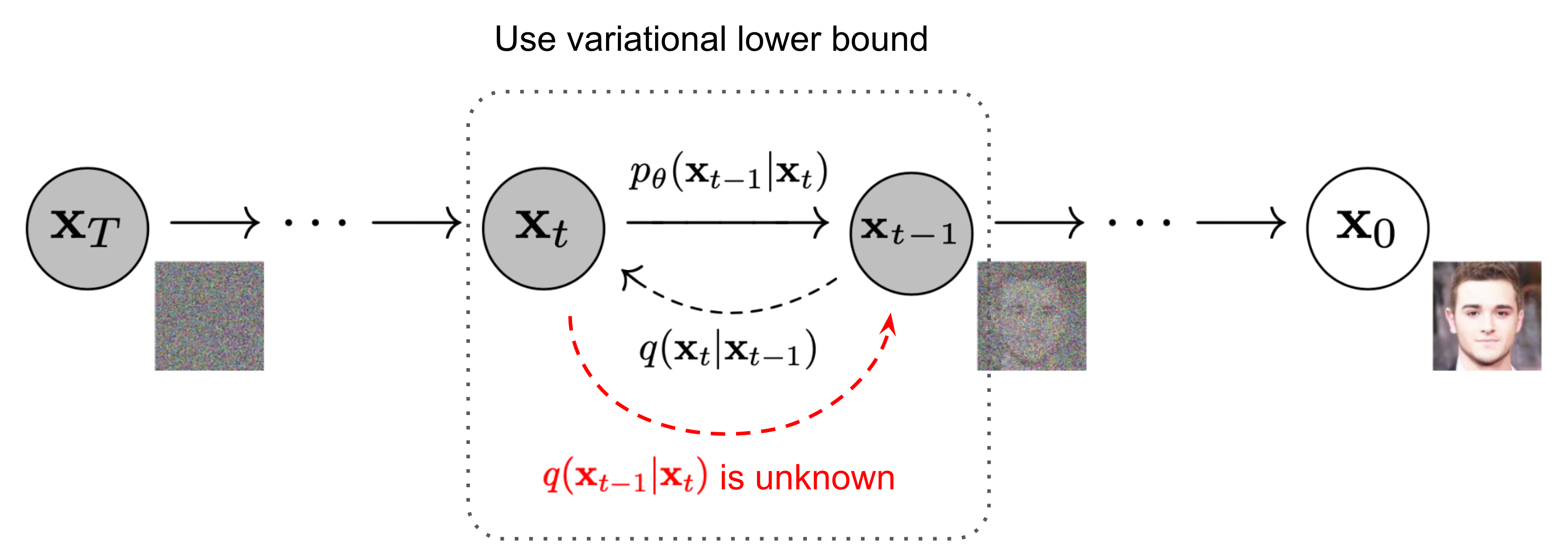
逆扩散过程
如果我们反转上述过程,尝试从 q ( X t − 1 ∣ X t ) q(X_{t-1}|X_t) q(Xt−1∣Xt)中采样,我们将能够从一个高斯噪声输入 X T ∼ N ( 0 , I ) X_T \sim \mathcal{N}(0,I) XT∼N(0,I)中重构出真实的样本。(逆过程是从高斯噪声中恢复原始数据)
逆扩散过程也是一个马尔科夫链过程。
需要注意的是,如果
β
t
\beta_t
βt的值足够小,那么
q
(
X
t
−
1
∣
X
t
)
q(X_{t-1}|X_t)
q(Xt−1∣Xt)也将是一个高斯分布。但不幸的是,我们无法简单的估计
q
(
X
t
−
1
∣
X
t
)
q(X_{t-1}|X_t)
q(Xt−1∣Xt),因为其估计需要使用到整个数据集。因此,我们需要学习一个模型
p
θ
p_θ
pθ去逼近这些条件概率以运行这个逆扩散过程。
p
θ
(
X
0
:
T
)
=
p
(
X
T
)
∏
t
=
1
T
p
θ
(
X
t
−
1
∣
X
t
)
p
θ
(
X
t
−
1
∣
X
t
)
=
N
(
X
t
−
1
;
μ
θ
(
X
t
,
t
)
,
∑
θ
(
X
t
,
t
)
)
p_θ(X_{0:T}) = p(X_T)\prod^T_{t=1}p_θ(X_{t-1}|X_t)\\ p_θ(X_{t-1}|X_t) = \mathcal{N}(X_{t-1};μ_θ(X_t,t),\sum_θ(X_t,t))
pθ(X0:T)=p(XT)t=1∏Tpθ(Xt−1∣Xt)pθ(Xt−1∣Xt)=N(Xt−1;μθ(Xt,t),θ∑(Xt,t))

值得注意的是,当给定
X
0
X_0
X0时,这个逆条件概率是易处理的
q
(
X
t
−
1
∣
X
t
,
X
0
)
=
N
(
X
t
−
1
;
μ
~
(
X
t
,
X
0
)
,
β
~
t
I
)
q(X_{t-1}|X_t,X_0)=\mathcal N(X_{t-1};\tilde μ(X_t,X_0),\tilde \beta_t I)
q(Xt−1∣Xt,X0)=N(Xt−1;μ~(Xt,X0),β~tI)
使用贝叶斯规则,我们可以得到
q
(
X
t
−
1
∣
X
t
,
X
0
)
=
q
(
X
t
,
X
t
−
1
,
X
0
)
q
(
X
t
,
X
0
)
=
q
(
X
t
,
X
t
−
1
,
X
0
)
q
(
X
t
−
1
,
X
0
)
∗
q
(
X
t
−
1
,
X
0
)
q
(
X
t
,
X
0
)
=
q
(
X
t
∣
X
t
−
1
,
X
0
)
∗
q
(
X
t
−
1
∣
X
0
)
q
(
X
t
∣
X
0
)
\begin{aligned} q(X_{t-1}|X_t,X_0) &= \frac{q(X_t,X_{t-1},X_0)}{q(X_t,X_0)}\\ &=\frac{q(X_t,X_{t-1},X_0)}{q(X_{t-1},X_0)}*\frac{q(X_{t-1},X_0)}{q(X_t,X_0)}\\ &=q(X_t|X_{t-1},X_0)*\frac{q(X_{t-1}|X_0)}{q(X_t|X_0)} \end{aligned}
q(Xt−1∣Xt,X0)=q(Xt,X0)q(Xt,Xt−1,X0)=q(Xt−1,X0)q(Xt,Xt−1,X0)∗q(Xt,X0)q(Xt−1,X0)=q(Xt∣Xt−1,X0)∗q(Xt∣X0)q(Xt−1∣X0)
由于扩散过程也是一个马尔科夫链过程,所以
q
(
X
t
∣
X
t
−
1
,
X
0
)
=
q
(
X
t
∣
X
t
−
1
)
∼
N
(
X
t
;
α
t
X
t
−
1
,
β
t
I
)
q(X_t|X_{t-1},X_0)=q(X_t|X_{t-1})\sim \mathcal N(X_t;\sqrt \alpha_tX_{t-1},\beta_tI)
q(Xt∣Xt−1,X0)=q(Xt∣Xt−1)∼N(Xt;αtXt−1,βtI),后面的分式可根据前向扩展过程中的结论得到答案。
q
(
X
t
−
1
∣
X
t
,
X
0
)
=
q
(
X
t
∣
X
t
−
1
,
X
0
)
∗
q
(
X
t
−
1
∣
X
0
)
q
(
X
t
∣
X
0
)
∝
e
x
p
(
−
1
2
(
(
X
t
−
α
t
X
t
−
1
)
2
β
t
+
(
X
t
−
1
−
α
‾
t
−
1
X
0
)
2
1
−
α
‾
t
−
1
−
(
X
t
−
α
‾
t
X
0
)
2
1
−
α
‾
t
)
=
e
x
p
(
−
1
2
(
(
α
t
β
t
+
1
1
−
α
‾
t
−
1
)
X
t
−
1
2
−
(
2
α
t
β
t
X
t
+
2
α
‾
t
1
−
α
‾
t
X
0
)
X
t
−
1
+
C
(
X
t
,
X
0
)
)
)
\begin{aligned} q(X_{t-1}|X_t,X_0) &= q(X_t|X_{t-1},X_0)*\frac{q(X_{t-1}|X_0)}{q(X_t|X_0)}\\ &∝exp(-\frac{1}{2}(\frac{(X_t-\sqrt{\alpha_t}X_{t-1})^2}{\beta_t}+\frac{(X_{t-1}-\sqrt{\overline{\alpha}_{t-1}}X_0)^2}{1-\overline{\alpha}_{t-1}}-\frac{(X_t-\sqrt{\overline{\alpha}_t}X_0)^2}{1-\overline{\alpha}_t})\\ &=exp(-\frac{1}{2}((\frac{\alpha_t}{\beta_t}+\frac{1}{1-\overline{\alpha}_{t-1}})X_{t-1}^2-(\frac{2\sqrt{\alpha_t}}{\beta_t}X_t+\frac{2\sqrt{\overline{\alpha}_t}}{1-\overline{\alpha}_t}X_0)X_{t-1}+C(X_t,X_0))) \end{aligned}
q(Xt−1∣Xt,X0)=q(Xt∣Xt−1,X0)∗q(Xt∣X0)q(Xt−1∣X0)∝exp(−21(βt(Xt−αtXt−1)2+1−αt−1(Xt−1−αt−1X0)2−1−αt(Xt−αtX0)2)=exp(−21((βtαt+1−αt−11)Xt−12−(βt2αtXt+1−αt2αtX0)Xt−1+C(Xt,X0)))
其中
(
α
t
β
t
+
1
1
−
α
‾
t
−
1
)
X
t
−
1
2
−
(
2
α
t
β
t
X
t
+
2
α
‾
t
1
−
α
‾
t
X
0
)
X
t
−
1
(\frac{\alpha_t}{\beta_t}+\frac{1}{1-\overline{\alpha}_{t-1}})X_{t-1}^2-(\frac{2\sqrt{\alpha_t}}{\beta_t}X_t+\frac{2\sqrt{\overline{\alpha}_t}}{1-\overline{\alpha}_t}X_0)X_{t-1}
(βtαt+1−αt−11)Xt−12−(βt2αtXt+1−αt2αtX0)Xt−1可以看作是
a
x
2
−
b
x
=
a
(
x
−
b
2
a
)
2
+
C
ax^2-bx=a(x-\frac{b}{2a})^2+C
ax2−bx=a(x−2ab)2+C。
高斯分布的概率密度函数是
f
(
x
)
=
1
2
π
σ
e
−
(
x
−
μ
)
2
2
σ
2
f(x)=\frac{1}{\sqrt{2\pi}\sigma}e^-\frac{(x-μ)^2}{2\sigma^2}
f(x)=2πσ1e−2σ2(x−μ)2
所以(分母没有2是因为已经提出去了)
a
(
x
−
b
2
a
)
2
=
(
x
−
b
2
a
)
2
1
a
=
(
x
−
μ
)
2
σ
2
a(x-\frac{b}{2a})^2=\frac{(x-\frac{b}{2a})^2}{\frac{1}{a}}=\frac{(x-μ)^2}{\sigma^2}
a(x−2ab)2=a1(x−2ab)2=σ2(x−μ)2
即
q
(
X
t
−
1
∣
X
t
,
X
0
)
=
N
(
X
t
−
1
;
μ
~
(
X
t
,
X
0
)
,
β
~
t
I
)
q(X_{t-1}|X_t,X_0)=\mathcal{N}(X_{t-1};\tilde{μ}(X_t,X_0),\tilde{\beta}_tI)
q(Xt−1∣Xt,X0)=N(Xt−1;μ~(Xt,X0),β~tI)中的
μ
~
(
X
t
,
X
0
)
\tilde{μ}(X_t,X_0)
μ~(Xt,X0)和
β
~
t
\tilde{\beta}_t
β~t可以分别写为
β
~
t
=
1
a
=
1
α
t
β
t
+
1
1
−
α
‾
t
−
1
=
1
−
α
‾
t
−
1
α
t
−
α
t
α
‾
t
−
1
+
1
−
α
t
β
t
=
1
−
α
‾
t
−
1
1
−
α
‾
t
β
t
\begin{aligned} \tilde{\beta}_t &= \frac{1}{a} \\ &=\frac{1}{\frac{\alpha_t}{\beta_t}+\frac{1}{1-\overline{\alpha}_{t-1}}}\\ &=\frac{1-\overline{\alpha}_{t-1}}{\alpha_t-\alpha_t\overline{\alpha}_{t-1}+1-\alpha_t}\beta_t\\ &=\frac{1-\overline{\alpha}_{t-1}}{1-\overline{\alpha}_t}\beta_t \end{aligned}
β~t=a1=βtαt+1−αt−111=αt−αtαt−1+1−αt1−αt−1βt=1−αt1−αt−1βt
μ ~ t ( X t , X 0 ) = b 2 a = 2 ( α t β t X t + α ‾ t 1 − α ‾ t X 0 ) 2 ( α t β t + 1 1 − α ‾ t − 1 ) = α t ( 1 − α ‾ t − 1 ) 1 − α ‾ t X t + α ‾ t − 1 β t 1 − α ‾ t X 0 \begin{aligned} \tilde{μ}_t(X_t,X_0) &= \frac{b}{2a} \\ &=\frac{2(\frac{\sqrt{\alpha_t}}{\beta_t}X_t+\frac{\sqrt{\overline{\alpha}_t}}{1-\overline{\alpha}_t}X_0)}{2(\frac{\alpha_t}{\beta_t}+\frac{1}{1-\overline{\alpha}_{t-1}})}\\ &=\frac{\sqrt{\alpha_t}(1-\overline{\alpha}_{t-1})}{1-\overline{\alpha}_t}X_t+\frac{\sqrt{\overline{\alpha}_{t-1}}\beta_t}{1-\overline{\alpha}_t}X_0 \end{aligned} μ~t(Xt,X0)=2ab=2(βtαt+1−αt−11)2(βtαtXt+1−αtαtX0)=1−αtαt(1−αt−1)Xt+1−αtαt−1βtX0
又因为在前向扩散过程中我们得到
X
t
=
α
‾
t
X
0
+
1
−
α
‾
t
z
X_t = \sqrt{\overline{\alpha}_t}X_0 + \sqrt{1 - \overline{\alpha}_t}z
Xt=αtX0+1−αtz,则
X
0
=
1
α
‾
t
(
X
t
−
1
−
α
‾
t
Z
t
)
X_0=\frac{1}{\sqrt{\overline{\alpha}_t}}(X_t-\sqrt{1-\overline{\alpha}_t}Z_t)
X0=αt1(Xt−1−αtZt)
将
X
0
X_0
X0代入到
μ
~
(
X
t
,
X
0
)
\tilde{μ}(X_t,X_0)
μ~(Xt,X0)中,可得
μ
~
t
(
X
t
,
X
0
)
=
α
t
(
1
−
α
‾
t
−
1
)
1
−
α
‾
t
X
t
+
α
‾
t
−
1
β
t
1
−
α
‾
t
1
α
‾
t
(
X
t
−
1
−
α
‾
t
Z
t
)
=
1
α
t
(
X
t
−
β
t
1
−
α
‾
t
Z
t
)
\begin{aligned} \tilde{μ}_t(X_t,X_0) &= \frac{\sqrt{\alpha_t}(1-\overline{\alpha}_{t-1})}{1-\overline{\alpha}_t}X_t+\frac{\sqrt{\overline{\alpha}_{t-1}}\beta_t}{1-\overline{\alpha}_t}\frac{1}{\sqrt{\overline{\alpha}_t}}(X_t-\sqrt{1-\overline{\alpha}_t}Z_t)\\ &=\frac{1}{\sqrt{\alpha_t}}(X_t-\frac{\beta_t}{\sqrt{1-\overline{\alpha}_t}}Z_t) \end{aligned}
μ~t(Xt,X0)=1−αtαt(1−αt−1)Xt+1−αtαt−1βtαt1(Xt−1−αtZt)=αt1(Xt−1−αtβtZt)
目标数据分布的似然函数
我们可以在负对数似然函数的基础上加上一个KL散度,于是就构成了负对数似然的上界了,上界越小,负对数似然自然也就越小,那么对数似然就越大了。
−
l
o
g
p
θ
(
X
0
)
≤
−
l
o
g
p
θ
(
X
0
)
+
D
K
L
(
q
(
X
1
:
T
∣
X
0
)
∣
∣
p
θ
(
X
1
:
T
∣
X
0
)
)
=
−
l
o
g
p
θ
(
X
0
)
+
E
X
1
:
T
∼
1
(
X
1
:
T
∣
X
0
)
[
l
o
g
q
(
X
1
:
T
∣
X
0
)
p
θ
(
X
0
:
T
)
/
p
θ
(
X
0
)
]
=
−
l
o
g
p
θ
(
X
0
)
+
E
q
[
l
o
g
q
(
X
1
:
T
∣
X
0
)
p
θ
(
X
0
:
T
)
+
l
o
g
p
θ
(
X
0
)
]
=
E
q
[
l
o
g
q
(
X
1
:
T
∣
X
0
)
p
θ
(
X
0
:
T
)
]
\begin{aligned} -logp_θ(X_0) &\le -logp_θ(X_0)+D_{KL}(q(X_{1:T}|X_0)||p_θ(X_{1:T}|X_0)) \\ &= -logp_θ(X_0)+E_{X_{1:T}\sim 1(X_{1:T}|X_0)}[log\frac{q(X_{1:T}|X_0)}{p_θ(X_{0:T})/p_θ(X_0)}] \\ &= -logp_θ(X_0)+E_q[log\frac{q(X_{1:T}|X_0)}{p_θ(X_{0:T})}+logp_θ(X_0)] \\ &= E_q[log\frac{q(X_{1:T}|X_0)}{p_θ(X_{0:T})}] \end{aligned}
−logpθ(X0)≤−logpθ(X0)+DKL(q(X1:T∣X0)∣∣pθ(X1:T∣X0))=−logpθ(X0)+EX1:T∼1(X1:T∣X0)[logpθ(X0:T)/pθ(X0)q(X1:T∣X0)]=−logpθ(X0)+Eq[logpθ(X0:T)q(X1:T∣X0)+logpθ(X0)]=Eq[logpθ(X0:T)q(X1:T∣X0)]
L e t L V L B = E q ( X 0 : T ) [ l o g q ( X 1 : T ∣ X 0 ) p θ ( X 0 : T ) ] ≥ − E q ( X 0 ) l o g p θ ( X 0 ) Let \ \ L_{VLB}=E_{q(X_{0:T})}[log\frac{q(X_{1:T}|X_0)}{p_θ(X_{0:T})}]\ge-E_{q(X_0)}logp_θ(X_0) Let LVLB=Eq(X0:T)[logpθ(X0:T)q(X1:T∣X0)]≥−Eq(X0)logpθ(X0)
进一步可以写出如上公式的交叉熵的上界,接下来,我们可以对交叉熵的上界进行化简。
tips:
q
(
X
t
−
1
∣
X
t
,
X
0
)
=
q
(
X
t
∣
X
t
−
1
,
X
0
)
q
(
X
t
−
1
∣
X
0
)
q
(
X
t
∣
X
0
)
=
q
(
X
t
∣
X
t
−
1
)
q
(
X
t
−
1
∣
X
0
)
q
(
X
t
∣
X
0
)
\begin{aligned} q(X_{t-1}|X_t,X_0)=q(X_t|X_{t-1},X_0)\frac{q(X_{t-1}|X_0)}{q(X_t|X_0)}\\=q(X_t|X_{t-1})\frac{q(X_{t-1}|X_0)}{q(X_t|X_0)} \end{aligned}
q(Xt−1∣Xt,X0)=q(Xt∣Xt−1,X0)q(Xt∣X0)q(Xt−1∣X0)=q(Xt∣Xt−1)q(Xt∣X0)q(Xt−1∣X0)
L
V
L
B
=
E
q
(
X
0
:
T
)
[
l
o
g
q
(
X
1
:
T
∣
X
0
)
p
θ
(
X
0
:
T
)
]
=
E
q
[
l
o
g
∏
t
=
1
T
q
(
X
t
∣
X
t
−
1
)
p
θ
(
X
T
)
∏
t
=
1
T
p
θ
(
X
t
−
1
∣
X
t
)
]
=
E
q
[
−
l
o
g
p
θ
(
X
T
)
+
∑
t
=
1
T
l
o
g
q
(
X
t
∣
X
t
−
1
)
p
θ
(
X
t
−
1
∣
X
t
)
]
=
E
q
[
−
l
o
g
p
θ
(
X
T
)
+
∑
t
=
2
T
l
o
g
q
(
X
t
∣
X
t
−
1
)
p
θ
(
X
t
−
1
∣
X
t
)
+
l
o
g
q
(
X
1
∣
X
0
)
p
θ
(
X
0
∣
X
1
)
]
=
E
q
[
−
l
o
g
p
θ
(
X
T
)
+
∑
t
=
2
T
l
o
g
(
q
(
X
t
−
1
∣
X
t
,
X
0
)
p
θ
(
X
t
−
1
∣
X
t
)
∗
q
(
X
t
∣
X
0
)
q
(
X
t
−
1
∣
X
0
)
)
+
l
o
g
q
(
X
1
∣
X
0
)
p
θ
(
X
0
∣
X
1
)
]
=
E
q
[
−
l
o
g
p
θ
(
X
T
)
+
∑
t
=
2
T
l
o
g
q
(
X
t
−
1
∣
X
t
,
X
0
)
p
θ
(
X
t
−
1
∣
X
t
)
+
∑
t
=
2
T
l
o
g
q
(
X
t
∣
X
0
)
q
(
X
t
−
1
∣
X
0
)
+
l
o
g
q
(
X
1
∣
X
0
)
p
θ
(
X
0
∣
X
1
)
]
=
E
q
[
−
l
o
g
p
θ
(
X
T
)
+
∑
t
=
2
T
l
o
g
q
(
X
t
−
1
∣
X
t
,
X
0
)
p
θ
(
X
t
−
1
∣
X
t
)
+
l
o
g
q
(
X
T
∣
X
0
)
q
(
X
1
∣
X
0
)
+
l
o
g
q
(
X
1
∣
X
0
)
p
θ
(
X
0
∣
X
1
)
]
=
E
q
[
l
o
g
q
(
X
T
∣
X
0
)
p
θ
(
X
T
)
+
∑
t
=
1
T
q
(
X
t
−
1
∣
X
t
,
X
0
)
p
θ
(
X
t
−
1
∣
X
t
)
−
l
o
g
p
θ
(
X
0
∣
X
1
)
]
=
E
q
[
D
K
L
(
q
(
X
T
∣
X
0
)
∣
∣
p
θ
(
X
T
)
)
+
∑
t
=
2
T
D
K
L
(
q
(
x
t
−
1
∣
X
t
,
X
0
)
∣
∣
p
θ
(
X
t
−
1
∣
X
t
)
)
−
l
o
g
p
θ
(
X
0
∣
X
1
)
]
\begin{aligned} L_{VLB} &= E_{q(X_{0:T})}[log\frac{q(X_{1:T}|X_0)}{p_θ(X_{0:T})}] \\ &= E_q[log\frac{\prod_{t=1}^Tq(X_t|X_{t-1})}{p_θ(X_T)\prod_{t=1}^Tp_θ(X_{t-1}|X_t)}] \\ &= E_q[-logp_θ(X_T)+\sum_{t=1}^Tlog\frac{q(X_t|X_{t-1})}{p_θ(X_{t-1}|X_t)}] \\ &= E_q[-logp_θ(X_T)+\sum_{t=2}^Tlog\frac{q(X_t|X_{t-1})}{p_θ(X_{t-1}|X_t)}+log\frac{q(X_1|X_0)}{p_θ(X_0|X_1)}] \\ &= E_q[-logp_θ(X_T)+\sum_{t=2}^Tlog(\frac{q(X_{t-1}|X_t,X_0)}{p_θ(X_{t-1}|X_t)}*\frac{q(X_t|X_0)}{q(X_{t-1}|X_0)})+log\frac{q(X_1|X_0)}{p_θ(X_0|X_1)}] \\ &= E_q[-logp_θ(X_T)+\sum_{t=2}^Tlog\frac{q(X_{t-1}|X_t,X_0)}{p_θ(X_{t-1}|X_t)}+\sum_{t=2}^Tlog\frac{q(X_t|X_0)}{q(X_{t-1}|X_0)}+log\frac{q(X_1|X_0)}{p_θ(X_0|X_1)}] \\ &= E_q[-logp_θ(X_T)+\sum_{t=2}^Tlog\frac{q(X_{t-1}|X_t,X_0)}{p_θ(X_{t-1}|X_t)}+log\frac{q(X_T|X_0)}{q(X_1|X_0)}+log\frac{q(X_1|X_0)}{p_θ(X_0|X_1)}] \\ &=E_q[log\frac{q(X_T|X_0)}{p_θ(X_T)}+\sum_{t=1}^T\frac{q(X_{t-1}|X_t,X_0)}{p_θ(X_{t-1}|X_t)}-logp_θ(X_0|X_1)] \\ &= E_q[D_{KL}(q(X_T|X_0)||p_θ(X_T))+\sum_{t=2}^TD_{KL}(q(x_{t-1}|X_t,X_0)||p_θ(X_{t-1}|X_t))- logp_θ(X_0|X_1)] \end{aligned}
LVLB=Eq(X0:T)[logpθ(X0:T)q(X1:T∣X0)]=Eq[logpθ(XT)∏t=1Tpθ(Xt−1∣Xt)∏t=1Tq(Xt∣Xt−1)]=Eq[−logpθ(XT)+t=1∑Tlogpθ(Xt−1∣Xt)q(Xt∣Xt−1)]=Eq[−logpθ(XT)+t=2∑Tlogpθ(Xt−1∣Xt)q(Xt∣Xt−1)+logpθ(X0∣X1)q(X1∣X0)]=Eq[−logpθ(XT)+t=2∑Tlog(pθ(Xt−1∣Xt)q(Xt−1∣Xt,X0)∗q(Xt−1∣X0)q(Xt∣X0))+logpθ(X0∣X1)q(X1∣X0)]=Eq[−logpθ(XT)+t=2∑Tlogpθ(Xt−1∣Xt)q(Xt−1∣Xt,X0)+t=2∑Tlogq(Xt−1∣X0)q(Xt∣X0)+logpθ(X0∣X1)q(X1∣X0)]=Eq[−logpθ(XT)+t=2∑Tlogpθ(Xt−1∣Xt)q(Xt−1∣Xt,X0)+logq(X1∣X0)q(XT∣X0)+logpθ(X0∣X1)q(X1∣X0)]=Eq[logpθ(XT)q(XT∣X0)+t=1∑Tpθ(Xt−1∣Xt)q(Xt−1∣Xt,X0)−logpθ(X0∣X1)]=Eq[DKL(q(XT∣X0)∣∣pθ(XT))+t=2∑TDKL(q(xt−1∣Xt,X0)∣∣pθ(Xt−1∣Xt))−logpθ(X0∣X1)]
那么就可以得到
L
V
L
B
=
L
T
+
L
T
−
1
+
⋯
+
L
0
w
h
e
r
e
L
T
=
D
K
L
(
q
(
X
T
∣
X
0
)
∣
∣
p
θ
(
X
T
)
)
L
t
=
D
K
L
(
q
(
X
t
∣
X
t
+
1
,
X
0
)
∣
∣
p
θ
(
X
t
∣
X
t
+
1
)
)
f
o
r
1
≤
t
≤
T
−
1
L
0
=
−
l
o
g
p
θ
(
X
0
∣
X
1
)
\begin{aligned} L_{VLB} &= L_T+L_{T-1}+\dots+L_0 \\ where L_T &= D_{KL}(q(X_T|X_0)||p_θ(X_T)) \\ L_t &= D_{KL}(q(X_{t}|X_{t+1},X_0)||p_θ(X_{t}|X_{t+1})) for\ 1 \le t \le T-1 \\ L_0 &= - logp_θ(X_0|X_1) \end{aligned}
LVLBwhereLTLtL0=LT+LT−1+⋯+L0=DKL(q(XT∣X0)∣∣pθ(XT))=DKL(q(Xt∣Xt+1,X0)∣∣pθ(Xt∣Xt+1))for 1≤t≤T−1=−logpθ(X0∣X1)
损失函数


代码后续给出















 4411
4411











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









