







目录
1.简要介绍

在这项工作中,论文系统地回顾了在代码处理方面的最新进展,包括50个+模型,30个+评估任务和500个相关工作。论文将代码处理模型分解为由GPT家族表示的通用语言模型和专门预训练的代码模型,通常具有定制的目标。论文讨论了这些模型之间的关系和差异,并强调了代码建模从统计模型和rnn到预训练的transformer和LLM的历史转变,这与NLP所采取的过程完全相同。还讨论了特定于代码的特性,如AST、CFG和单元测试,以及它们在训练代码语言模型中的应用,并确定了该领域的关键挑战和潜在的未来方向。
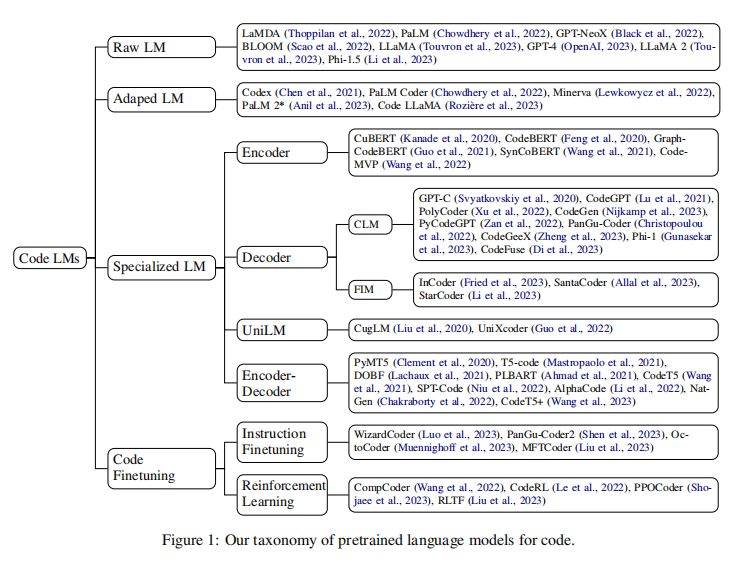
2.代码处理的语言模型的评估
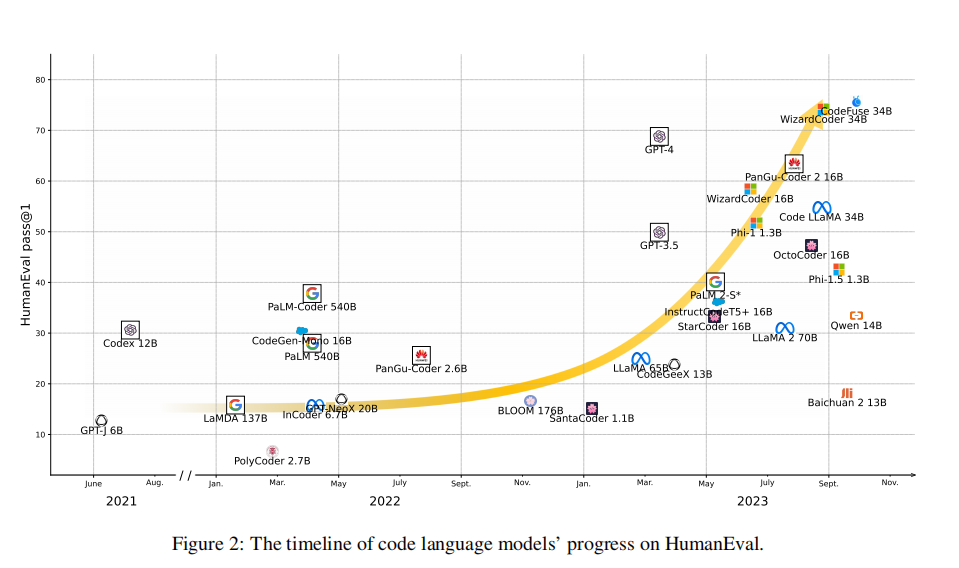
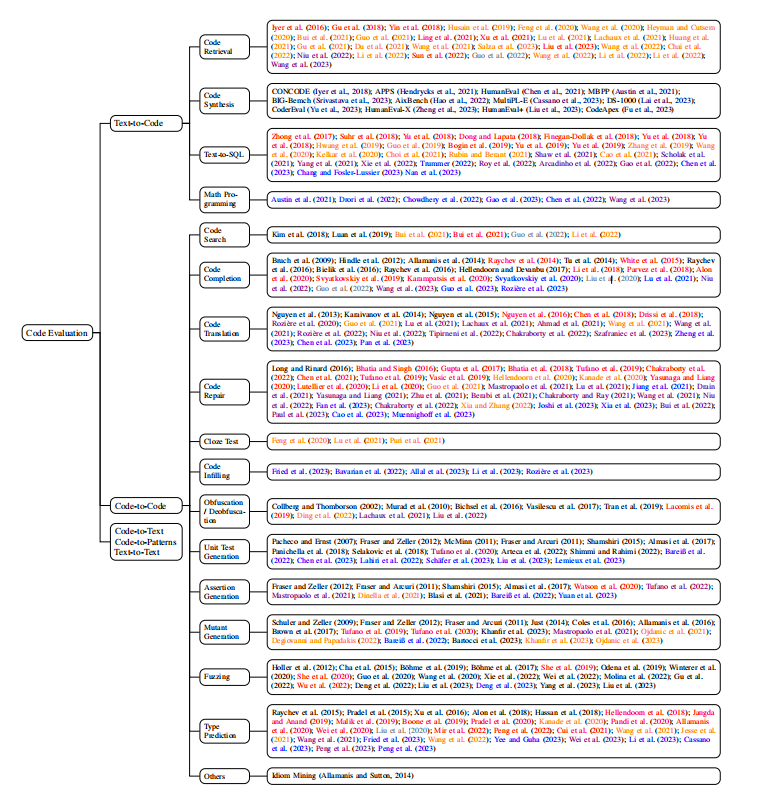
在过去的十年里,软件工程界提出了各种评估任务来评估代码模型。CodeXGLUE将大多数此类任务合并整合为一个单一的基准测试,包括代码理解任务,如克隆检测、缺陷检测和序列到序列的生成任务,如代码修复、代码翻译、程序合成和代码摘要。然而,在Chen等人(2021)引入HumanEval和Codex之后,text-to-code的合成成为NLP社区关注的焦点,并已成为评估LLM的标准任务(图2)。因此,论文首先简要介绍了每一个传统任务以及预训练语言模型的应用,并在图3、4中提供了每个任务的相关工作的全面列表。然后,回顾了评估指标,并更详细地研究了程序合成。最后,论文还讨论了存储库级评估的最新趋势。在附录A中,列出了每个下游任务的基准测试。

2.1 代码处理的下游任务
根据软件工程中的自定义,论文根据代码的输入/输出方式对代码的评估任务进行分类,并将这些任务分为五类:text-to-code, code-to-code, code-to-text, code-to-patterns和text-to-text。这种分类法与NLP中的理解-生成二分法交织在一起,因为每个类别可能同时包含理解和生成任务。
2.1.1 text-to-code
Text-to-code 任务以文本作为输入,并输出代码。 - Code retrieval旨在检索给定的自然语言查询的相关代码,或从未注释的语料库中挖掘并行文本代码对。这个任务通常是通过计算查询代码和候选代码的嵌入之间的相似性度量来完成的,而由双向语言模型产生的上下文嵌入——如BERT——已经被证明是非常有用的。 - Code synthesis 旨在生成给定一个自然语言描述的代码(通常是一个函数或一个方法)。这个任务可以看作是使用生成模型而不是检索模型的代码检索的更新版本。统计机器翻译(SMT)和神经机器翻译(NMT)模型通常使用增强的解码器,利用编程语言独特的语法规则,且已被广泛应用于这项任务。然而,基于transformer架构的预训练语言模型通过即使没有特定任务的微调直接生成自回归语言建模风格的源代码,改变了游戏规则。论文将在3.3中更详细地讨论这个任务。 - Text-to-SQL是代码合成的一种特殊情况(也可以说是更容易的),其中模型的任务是从自然语言查询中生成SQL命令。由于SQL的结构化特性(与Python和C等通用语言相比)以及在数据管理中的广泛应用,它一直是一个特别感兴趣的话题。 - Math programming这也是代码合成的一种特殊情况,其中需要一个语言模型,通过生成将由外部解释器执行的代码来解决数学推理问题。该任务从数值计算中抽象出了推理过程,因此对评估LLM具有特别的意义。
2.1.2 Code-to-Code
Code-to-Code的任务以代码作为输入,并输出代码。 - Code search是一个类似于代码检索的任务,与后者的不同之处仅在于,输入是一个现有的代码片段,通常使用与目标不同的编程语言。 - Code completion旨在完成一个带有其前缀的代码片段。这本质上是应用于代码的语言建模,相关技术已经逐步引入: n-gram、RNN和transformer。然而,由于编程语言的结构化性质,许多早期研究发现语法辅助统计模型表现更好,神经模型直到2018年之后才成为主导地位(直观概述见图3)。 - Code translation 旨在将一段代码(通常是一个函数或方法)翻译成另一种编程语言。代码翻译和跨语言代码搜索之间的关系类似于代码合成和text-to-code检索之间的关系,SMT/MNT模型也被广泛应用于这项任务。代码合成在帮助程序员编写代码片段方面很有用,而代码翻译是迁移用过时语言编写的旧项目的一种重要技术。然而,作者还没有看到这样的应用程序,因为即使是最强大的语言模型的上下文窗口也是相当有限的。 - Code repair 也被称为bug修复,旨在修复一个有问题的代码。与代码翻译一样,它也是一项传统的序列到序列的生成任务,关于这个主题目前已有大量的研究。 - Cloze test是在bert式预训练兴起之后,最近提出的代码处理任务。由于编程语言的独特语义,这个测试经常选择几个关键字,如min和max。 - Code infilling是另一项最近提出的任务,在fill-in-the-middle预训练开始流行之后。它是代码完成的泛化,空白不仅给出了左边的上下文,还给出了右边的上下文。但是,它与填空测试的不同之处在于,填空测试的目标只是一个标记,而代码填充的目标可以是整行甚至多行,这需要一个解码器来自动回归生成。 - Obfuscation指重命名标识符(例如变量、方法和类)的过程,例如为通用名称,如var_1、var_2或x、y。它是病毒检测、知识产权保护和代码缩放方面的重要技术。去混淆是指反向过程,即从混淆的程序中恢复有意义的标识符名称。混淆对语言模型的应用很少,因为它可以很容易地静态地实现,但去混淆近年来已经成为人们更感兴趣的话题,并被用作代码语言模型的预训练目标 - Unit test generation旨在为一个给定的程序生成单元测试。在Codex和其他代码LLM出现之前,该领域中几乎所有的工作都采用了非神经方法(见图3)。然而,在LLM的时代,这项任务越来越重要,因为研究表明,目前评估LLM的程序综合能力的单元测试可能不够充分 - Assertion generation是一个与单元测试密切相关的任务。给定一个程序和一组单元测试,这个任务的旨在生成断言(在软件工程中也称为预言),以使用单元测试来评估程序。这个任务通常没有被NLP社区注意到,因为用于评估LLM的程序综合任务通常涉及独立的、竞争风格的方法,这样简单地断言程序输出和预期答案之间相似就足够了。 - Mutant generation旨在为突变测试生成给定程序的变体,与单元测试生成和断言生成密切相关。给定的一组单元测试和断言没有检测到的变体表明需要额外的测试用例或更好的断言。最近,屏蔽源代码中的标记并从屏蔽语言模型的输出中对它们进行采样已经成为这项任务的常用方法。Papadakis等人(2019年)就这一主题进行了调查。 - Fuzzing旨在改变一组给定的单元测试,以生成新的测试用例,这是另一个与测试软件相关的任务。虽然最近有许多关于模糊目标深度学习库的工作,但很少有人使用语言模型来进行这一过程(见图3)。 - Type prediction旨在预测动态编程语言的类型,如Python和JavaScript。它已被用作代码语言模型的预训练目标其中它通常被简化为一个二进制标记任务,以预测代码中的哪些标记是标识符。
2.1.3 Code-to-Text
Code-to-Text任务以代码作为输入,并输出文本。 - Code summarization 也被称为文档字符串生成,其旨在为一个给定的代码段(通常是一个函数或方法)生成一个自然语言描述。这与代码合成相反,SMT/NMT技术也有同样的应用。 - Code review旨在自动化同行代码评审的过程,并可能有多种形式。许多早期的工作将其定义为一个二进制分类任务,即在提交时接受或拒绝更改,而另一些工作则利用信息检索技术从现有的评论池中推荐评论。然而,随着生成模型变得越来越强大,研究人员还将直接生成评论作为一项序列到序列的学习任务进行了研究。 - Identifier prediction是预测代码中的标识符名称的任务。由于这些名称被认为包含重要的语义信息,该任务已被用于代码摘要,以及预训练代码模型。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 817
817

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









