







推荐系统技术演进趋势:从召回到排序再到重排
https://zhuanlan.zhihu.com/p/100019681
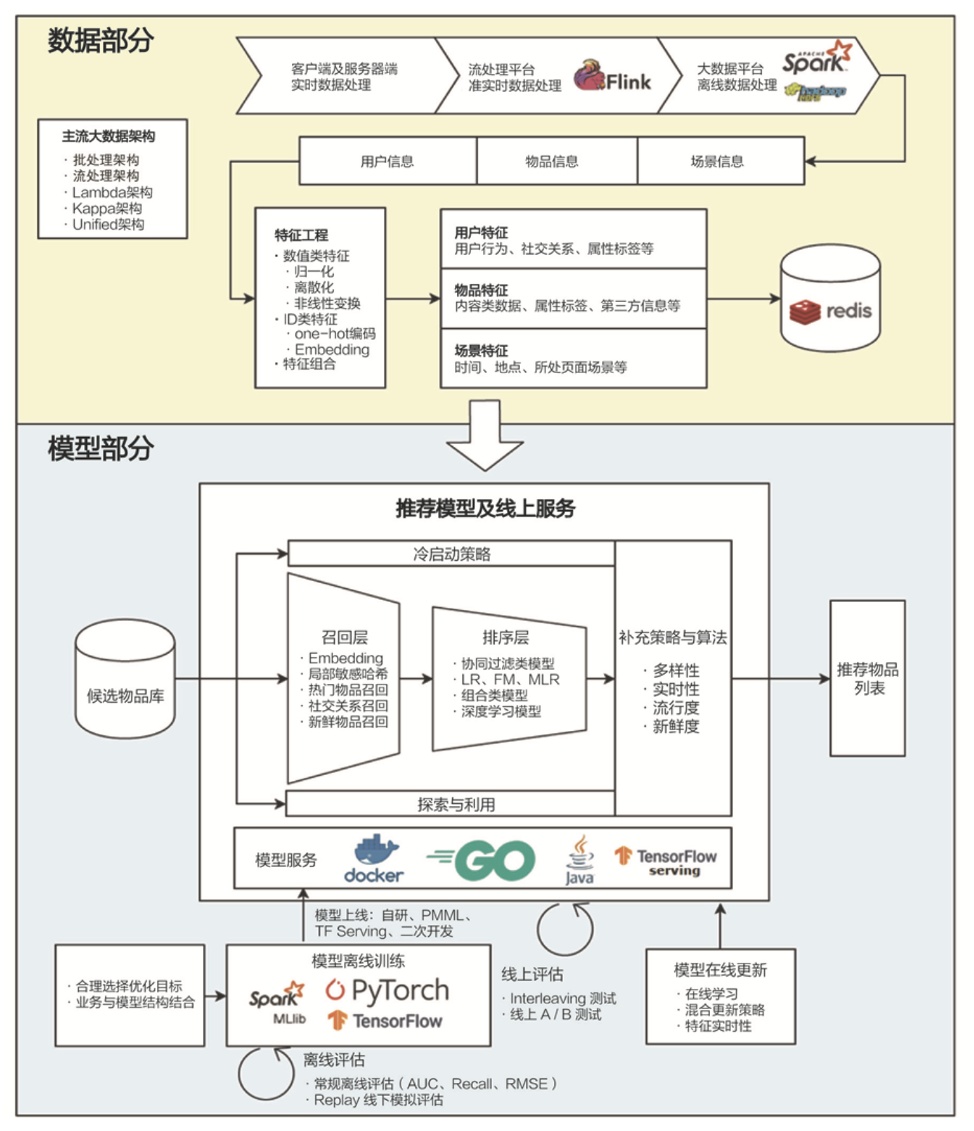
完整的信息流推荐系统
- 从偏后台的物料质量评估、用户兴趣建模、微博内容理解、图片视频理解以及多模态融合,
- 到业务前台的推荐系统的召回、粗排以及精排等推荐环节,
- 以及离线及在线的大规模机器学习模型训练及服务等。
召回层面,目前已实现大规模FM统一召回模型,正逐步替代传统的多路召回模型,并在各项指标取得了非常明显的业务效果。召回阶段,采用模型统一召回代替传统的多路召回是个比较明显的趋势。
排序层面,经过了LR、大规模FM、FM+FTRL在线模型等不断的模型升级,每次大的模型升级都取得了收益,目前也小流量了以DeepFM为基础的深度学习排序模型。在物料比如微博的理解方面,目前也在尝试多模态的技术路线,并取得了一定进展。
四个环节分别是:召回、粗排、精排和重排。
- 可以在召回和精排之间加入一个粗排环节,通过少量用户和物品特征,简单模型,来对召回的结果进行个粗略的排序,在保证一定精准的前提下,进一步减少往后传送的物品数量,粗排往往是可选的,可用可不同,跟场景有关。
- 之后,是精排环节,使用你能想到的任何特征,可以上你能承受速度极限的复杂模型,尽量精准地对物品进行个性化排序。
- 排序完成后,传给重排环节,传统地看,这里往往会上各种技术及业务策略,比如去已读、去重、打散、多样性保证、固定类型物品插入等等,主要是技术产品策略主导或者为了改进用户体验的。
召回(大规模FM统一召回模型)
①模型召回
- FM模型召回
- DNN双塔召回

传统的标准召回结构一般是多路召回。

模型召回的通用架构
核心思想是:将用户特征和物品特征分离,各自通过某个具体的模型,分别打出用户Embedding以及物品Embedding。
在线上,可以根据用户兴趣Embedding,采用类似Faiss等高效Embedding检索工具,快速找出和用户兴趣匹配的物品,这样就等于做出了利用多特征融合的召回模型了。理论上来说,任何你能见到的有监督模型,都可以用来做这个召回模型,比如FM/FFM/DNN等,常说的所谓“双塔”模型,指的其实是用户侧和物品侧特征分离分别打Embedding的结构而已,并非具体的模型。
②用户行为序列召回
GRU、CNN、Transformer

③用户多兴趣拆分
在召回阶段,把用户兴趣拆分成多个embedding是有直接价值和意义的。这种兴趣拆分,在召回阶段是很合适的,可以定向解决它面临的一些实际问题。对于排序环节,是否有必要把用户兴趣拆分成多个,倒觉得必要性不是太大。
④知识图谱融合召回⑤图神经网络模型召回
FM模型

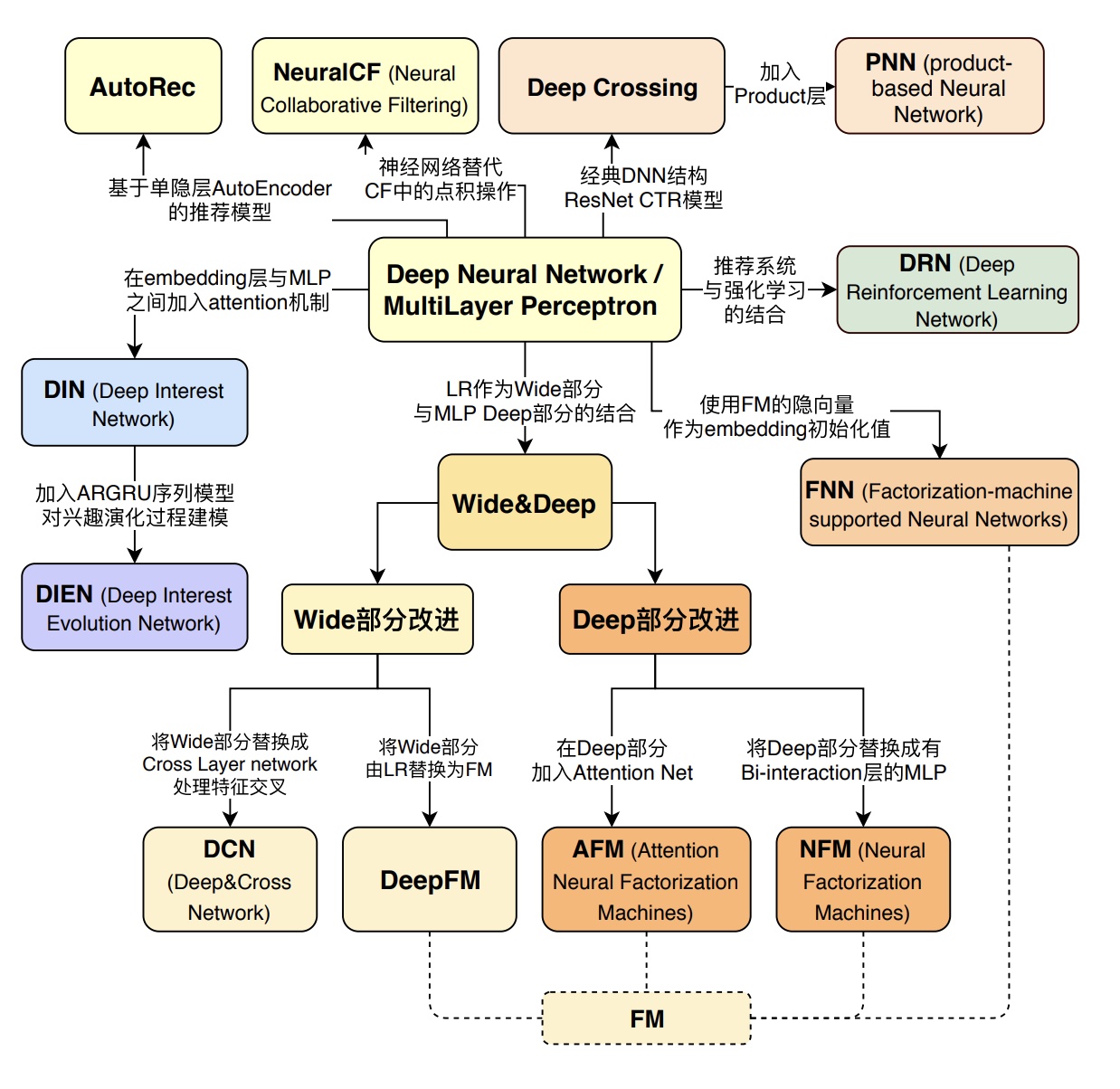
排序(LR、大规模FM、DeepFM)


- 最早的LR模型,基本是人工特征工程及人工进行特征组合的,简单有效但是费时费力;
- 再发展到LR+GBDT的高阶特征组合自动化,
- 以及FM模型的二阶特征组合自动化;
- 再往后就是DNN模型的引入,纯粹的简单DNN模型本质上其实是在FM模型的特征Embedding化基础上,添加几层MLP隐层来进行隐式的特征非线性自动组合而已。所谓隐式,意思是并没有明确的网络结构对特征的二阶组合、三阶组合进行直接建模,只是通过MLP,让不同特征发生交互,至于怎么发生交互的,怎么进行特征组合的,谁也说不清楚,这是MLP结构隐式特征组合的作用,当然由于MLP的引入,也会在特征组合时候考虑进入了特征间的非线性关系。
重排序(RNN或者Transformer)
在重排环节,常规的做法,这里是个策略出没之地,就是集中了各种业务和技术策略。比如为了更好的推荐体验,这里会加入去除重复、结果打散增加推荐结果的多样性、强插某种类型的推荐结果等等不同类型的策略。
从技术发展趋势角度看,重排阶段上模型,来代替各种花样的业务策略,是个总体的大趋势。
关于List Wise排序,可以从两个角度来说,一个是优化目标或损失函数;一个是推荐模块的模型结构。
推荐系统里Learning to Rank做排序,我们知道常见的有三种优化目标:Point Wise、Pair Wise和List Wise。
所以我们首先应该明确的一点是:List Wise它不是指的具体的某个或者某类模型,而是指的模型的优化目标或者损失函数定义方式,理论上各种不用的模型都可以使用List Wise损失来进行模型训练。
- 最简单的损失函数定义是Point Wise,就是输入用户特征和单个物品特征,对这个物品进行打分,物品之间的排序,就是谁应该在谁前面,不用考虑。明显这种方式无论是训练还是在线推理,都非常简单直接效率高,但是它的缺点是没有考虑物品直接的关联,而这在排序中其实是有用的。
- Pair Wise损失在训练模型时,直接用两个物品的顺序关系来训练模型,就是说优化目标是物品A排序要高于物品B,类似这种优化目标。其实Pair Wise的Loss在推荐领域已经被非常广泛得使用,比如BPR损失,就是典型且非常有效的Pair Wise的Loss Function,经常被使用,尤其在隐式反馈中,是非常有效的优化目标。
- List Wise的Loss更关注整个列表中物品顺序关系,会从列表整体中物品顺序的角度考虑,来优化模型。在推荐中,List Wise损失函数因为训练数据的制作难,训练速度慢,在线推理速度慢等多种原因,尽管用的还比较少,但是因为更注重排序结果整体的最优性,所以也是目前很多推荐系统正在做的事情。
从模型结构上来看。因为重排序模块往往是放在精排模块之后,而精排已经对推荐物品做了比较准确的打分,所以往往重排模块的输入是精排模块的Top得分输出结果,也就是说,是有序的。
而精排模块的打分或者排序对于重排模块来说,是非常重要的参考信息。于是,这个排序模块的输出顺序就比较重要,而能够考虑到输入的序列性的模型,自然就是重排模型的首选。我们知道,最常见的考虑时序性的模型是RNN和Transformer,所以经常把这两类模型用在重排模块,这是很自然的事情。
一般的做法是:排序Top结果的物品有序,作为RNN或者Transformer的输入,RNN或者Transformer明显可以考虑在特征级别,融合当前物品上下文,也就是排序列表中其它物品的特征,来从列表整体评估效果。RNN或者Transformer每个输入对应位置经过特征融合,再次输出预测得分,按照新预测的得分重新对物品排序,就完成了融合上下文信息,进行重新排序的目的。















 3508
3508











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









