 深入理解二分类与多分类的交叉熵损失函数
深入理解二分类与多分类的交叉熵损失函数







概述
在分类的任务中,往往会使用交叉熵损失函数。对于二分类,使用的是binary_crossentropy,在多分类的任务中,使用的时sparse_categorical_crossentropy和categorical_crossentropy,本文将详细的介绍这三种损失函数
binary_crossentropy
数学公式
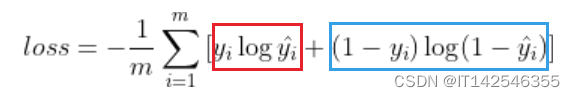
在二分类的任务中,标签值为[0, 1]。从公式中我们可以看出当的标签值为0时,只有蓝色的部分起作用,
的标签值为1时,只有红色的部分起作用。binary_crossentropy通常结合sigmoid激活函数使用,作为二分类的损失函数。同时也可以用于多分类的损失函数,其原理就是将多分类拆成多个二分类,每个类别都相互独立预测,categorical_crossentropy则限制各个类别的概率值相加和为1
代码示例
在此将使用tensorflow的api和公式计算两种方式来说明
- tensorflow api
from tensorflow.keras.losses import binary_crossentropy
y_true = [0, 1]
y_predict = [0.2, 0.9]
print(binary_crossentropy(y_true, y_predict))
# -----------------------------------------------------
输出:tf.Tensor(0.1642519, shape=(), dtype=float32)
- 公式计算
loss = -1/2. * (
0 * tf.math.log(0.2) + (1 - 0) * tf.math.log(1 - 0.2) +
1 * tf.math.log(0.9) + (1 - 1) * tf.math.log(1 - 0.9)
)
print(loss)
# ------------------------------------------------------------
输出:tf.Tensor(0.16425204, shape=(), dtype=float32)
总结:从结果可以看出都是一样的(有些许精度问题)
categorical_crossentropy
数学公式
公式中的m为样本数,k为类别数,对于多分类问题,有多少个类别,模型的输出就有多少个各个类别之间具有排他性。通常与softmax激活函数一起使用。使用categorical_crossentropy需要对y_true进行one_hot编码
代码示例
在此将使用tensorflow的api和公式计算两种方式来说明
- tensorflow api
from tensorflow.keras.losses import categorical_crossentropy
y_true = [[0, 1, 0], [1, 0, 0]]
y_predict = [[0.1, 0.6, 0.3],[0.8, 0.1, 0.1]]
loss = tf.reduce_mean(categorical_crossentropy(y_true, y_predict))
print(loss)
# -------------------------------------------------------
输出:tf.Tensor(0.36698455, shape=(), dtype=float32)
- 公式计算
loss = - 1/2. * (
(0 * tf.math.log(0.1) + 1 * tf.math.log(0.6) + 0 * tf.math.log(0.3)) +
(1 * tf.math.log(0.8) + 0 * tf.math.log(0.1) + 0 * tf.math.log(0.1))
)
print(loss)
# -------------------------------------------------------
输出:tf.Tensor(0.36698455, shape=(), dtype=float32)
总结:tensorflow的categorical_crossentropy api只会计算每个样本的交叉熵损失,所以需要而且加起来再求平均。如上所述,两种计算方式所求结果一致
sparse_categorical_crossentropy
公式和categorical_crossentropy是一样的,sparse_categorical_crossentropy和categorical_crossentropy的区别就是前者不需要转化为one_hot编码,使用整数编码(0,1,2,...,k),后者需要转化为one_hot编码,这个在前面也有所介绍。
代码示例
在此仅用tensorflow api来说明
from tensorflow.keras.losses import sparse_categorical_crossentropy
y_true = [1, 0]
y_predict = [[0.1, 0.6, 0.3], [0.8, 0.1, 0.1]]
loss = tf.reduce_mean(sparse_categorical_crossentropy(y_true, y_predict))
print(loss)
# ----------------------------------------------------------
输出:tf.Tensor(0.3669846, shape=(), dtype=float32)
总结:sparse_categorical_crossentropy也只是计算每个样本的交叉熵,所以需要而且加起来再求平均
最后
- binary_crossentropy通常与sigmoid激活函数一起使用,可用于二分类,也可用于多分类,在多分类时,每个类别的预测时相互独立的
- categorical_crossentropy和sparse_categorical_crossentropy都只会计算每个样本的交叉熵,最后需要将所有样本的交叉熵相加求平均。不同的是前者需要将y_true转化为one_hot编码,后者不需要,可以使用整数编码

















 1299
1299

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









