






由于收到后台很多小伙伴私信Ctrip_hotel网络数据采集,花了一点时间从新研究Ctrip_hotel:必须强调一下Ctrip_hotel是会识别selenium的必须绕过去不然就会出现找不到酒店信息。常见的绕过都会识别我这里使用本地js绕过。
之前那一篇文章写过是使用QQ账户和密码登录,现在这里使用QQ快捷登录动作。直接上代码
import selenium
from selenium import webdriver
from selenium.webdriver import ActionChains
from selenium.webdriver.common.by import By
import time
options = webdriver.ChromeOptions()
options.add_argument("start-maximized")
options.add_experimental_option("excludeSwitches", ["enable-automation"])
options.add_experimental_option("useAutomationExtension", False)
path='C:\Program Files\Google\Chrome\Application\chromedriver.exe'
driver=webdriver.Chrome(executable_path=path,options=options)
#读取本地写好的js文件
with open('./bypass.min.js') as f:
js = f.read()
driver.execute_cdp_cmd("Page.addScriptToEvaluateOnNewDocument", {"source": js})
#打开网页
url='https://hotels.ctrip.com/hotels/list?city=28&checkin=2023/07/18&checkout=2023/07/19&optionId=28&optionType=City&directSearch=0&display=%E6%88%90%E9%83%BD&crn=1&adult=1&children=0&searchBoxArg=t&travelPurpose=0&ctm_ref=ix_sb_dl&domestic=1&'
driver.get(url)
#通过xpath点击搜索
driver.maximize_window()
driver.implicitly_wait(10)
#先勾选阅读按钮
driver.find_element(By.XPATH,"/html/body/div[1]/div[2]/div[2]/div[2]/div/div[1]/div[1]/form/div[2]/div[2]/label").click()
#//*[@id="normalview"]/form/div[2]/div[2]/label
time.sleep(2)
#通过QQ授权登陆,# 自适应等待,点击密码登录选项
driver.implicitly_wait(5)
driver.find_element(By.XPATH,"//*[@id='loginbanner']/div[2]/a[2]").click()
# #跳转到QQ页面点击账号密码登陆,前提是绑定手机号
driver.implicitly_wait(5)
windows=driver.window_handles # 此行代码用来新窗口
driver.switch_to.window(windows[1])
driver.maximize_window()
driver.switch_to.frame('ptlogin_iframe')
time.sleep(1)
element=driver.find_element(By.XPATH,'//*[@id="switcher_plogin"]')
ActionChains(driver).move_to_element(element).perform()
#快捷登录头像
driver.find_element(By.XPATH,"/html/body/div[1]/div[4]/div[8]/div/a/span[4]").click()
driver.implicitly_wait(3)
#获取当前句柄并打开新窗口
windows_before = driver.current_window_handle
windows_after = driver.window_handles
#里面做判断校验
..........
#这里反复测试过一定要加等待时间不然后续会出现元素找不到报错
for j in range(5,50):
# 获取页面初始高度
js = "return action=document.body.scrollHeight"
height = driver.execute_script(js)
# get_attribute(‘textContent’)获取"标签里面内容"文字
name=driver.find_element(By.XPATH,"//*[@id='ibu_hotel_container']/div/section/div[2]/ul/li["+str(j)+"]/div/div/div/div[1]/div[2]/div[1]/div/span[1]").get_attribute("textContent").replace('\n', '').replace('\t', '')
shangquan=driver.find_element(By.XPATH,"//*[@id='ibu_hotel_container']/div/section/div[2]/ul/li["+str(j)+"]/div/div/div/div[1]/div[2]/div[2]/p/span[1]/span").get_attribute('textContent')
price=driver.find_element(By.XPATH,"//*[@id='ibu_hotel_container']/div/section/div[2]/ul/li["+str(j)+"]/div/div/div/div[2]/div[2]/div[1]/p/span[2]/span[2]").get_attribute("textContent")
if price == None:
price=driver.find_element(By.XPATH,"//*[@id='ibu_hotel_container']/div/section/div[2]/ul/li["+str(j)+"]/div/div/div/div[2]/div[2]/div[1]/p/span[2]/span[1]").get_attribute("textContent")
else:
price=driver.find_element(By.XPATH,"//*[@id='ibu_hotel_container']/div/section/div[2]/ul/li["+str(j)+"]/div/div/div/div[2]/div[2]/div[1]/p/span[2]/span[2]").get_attribute("textContent")
percent_elements = driver.find_elements(By.XPATH, "//*[@id='ibu_hotel_container']/div/section/div[2]/ul/li["+str(j)+"]/div/div/div/div[2]/div[1]/div/div[2]/span")
if len(percent_elements) == 0:
percent = "暂无评分"
else:
percent = percent_elements[0].get_attribute("textContent")
#//*[@id="ibu_hotel_container"]/div/section/div[2]/ul/li[6]/div/div/div/div[2]/div[1]/div/div[1]/p[2]/a
people=driver.find_element(By.XPATH,"//*[@id='ibu_hotel_container']/div/section/div[2]/ul/li["+str(j)+"]/div/div/div/div[2]/div[1]/div/div[1]/p[2]/a").get_attribute("textContent")
if people == None:
people='暂无点评'
else:
people = driver.find_element(By.XPATH, "//*[@id='ibu_hotel_container']/div/section/div[2]/ul/li[" + str(j) + "]/div/div/div/div[2]/div[1]/div/div[1]/p[2]/a").get_attribute("textContent")
addresses = "成都"
print(name, shangquan, price, percent, people, addresses)
time.sleep(0.5)
#每隔12个就翻页
if j % 12 == 4:
# 在每一页的开始执行滚动操作
driver.execute_script('window.scrollTo(0, document.body.scrollHeight)')
time.sleep(2)
# 查找"搜索更多"按钮
dianji_elements = driver.find_elements(By.XPATH,'//*[@id="ibu_hotel_container"]/div/section/div[2]/ul/div[2]/div/span')
if len(dianji_elements) == 0:
# 继续向下滚动页面
driver.execute_script('window.scrollTo(0, document.body.scrollHeight)')
time.sleep(2)
else:
# 点击"搜索更多"按钮
dianji_elements[0].click()
time.sleep(2)
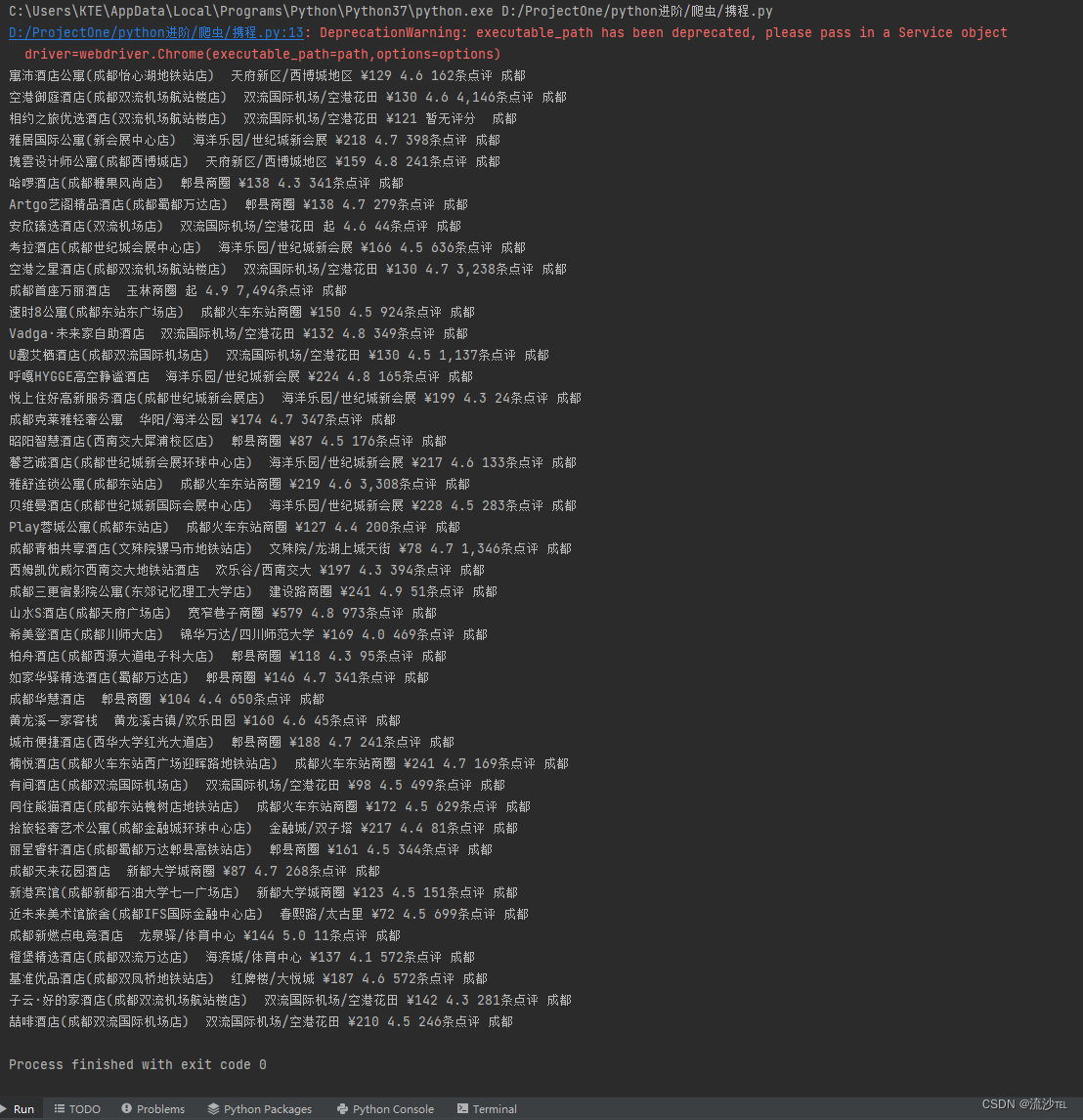
需要js文件和完整代码私信发。















 4020
4020











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









