







selenium定位方式
# 元素属性定位(3种)
driver.find_element_by_id(‘id’)
driver.find_element_by_name('name')
driver.find_element_by_class_name('class_name')
# 超链接定位(2种)
driver.find_element_by_link_text('link_text')
driver.find_element_by_partial_link_text('partial_link_text')
# 元素标签,元素路径,CSS选择器
driver.find_element_by_tag_name('tag_name')
driver.find_element_by_xpath('xpath')
driver.find_element_by_css_selector('css_selector')
但我们看下源码:
D:\Program Files\Python27\Lib\site-packages\selenium\webdriver\remote\webdriver.py
可以看到,上面那些定位方式,实际上都是调用的driver.find_element(by, value)
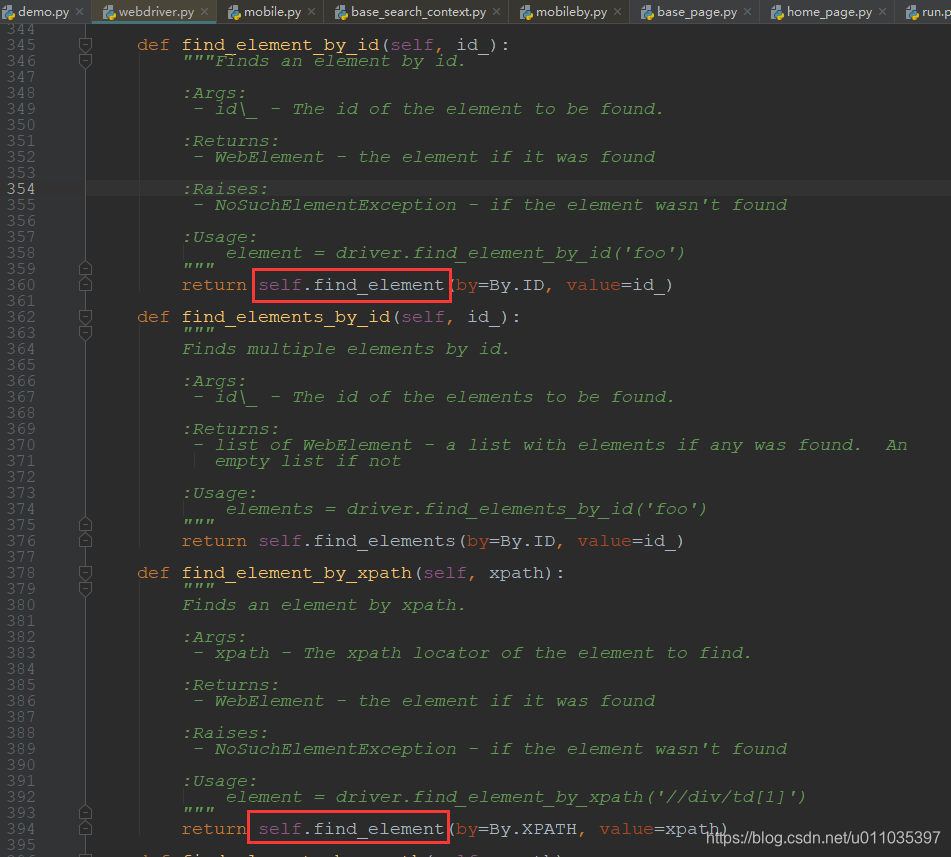
我们继续看下find_element()的源码,大部分方法最终全是通过By.CSS_SELECTOR来实现的查找
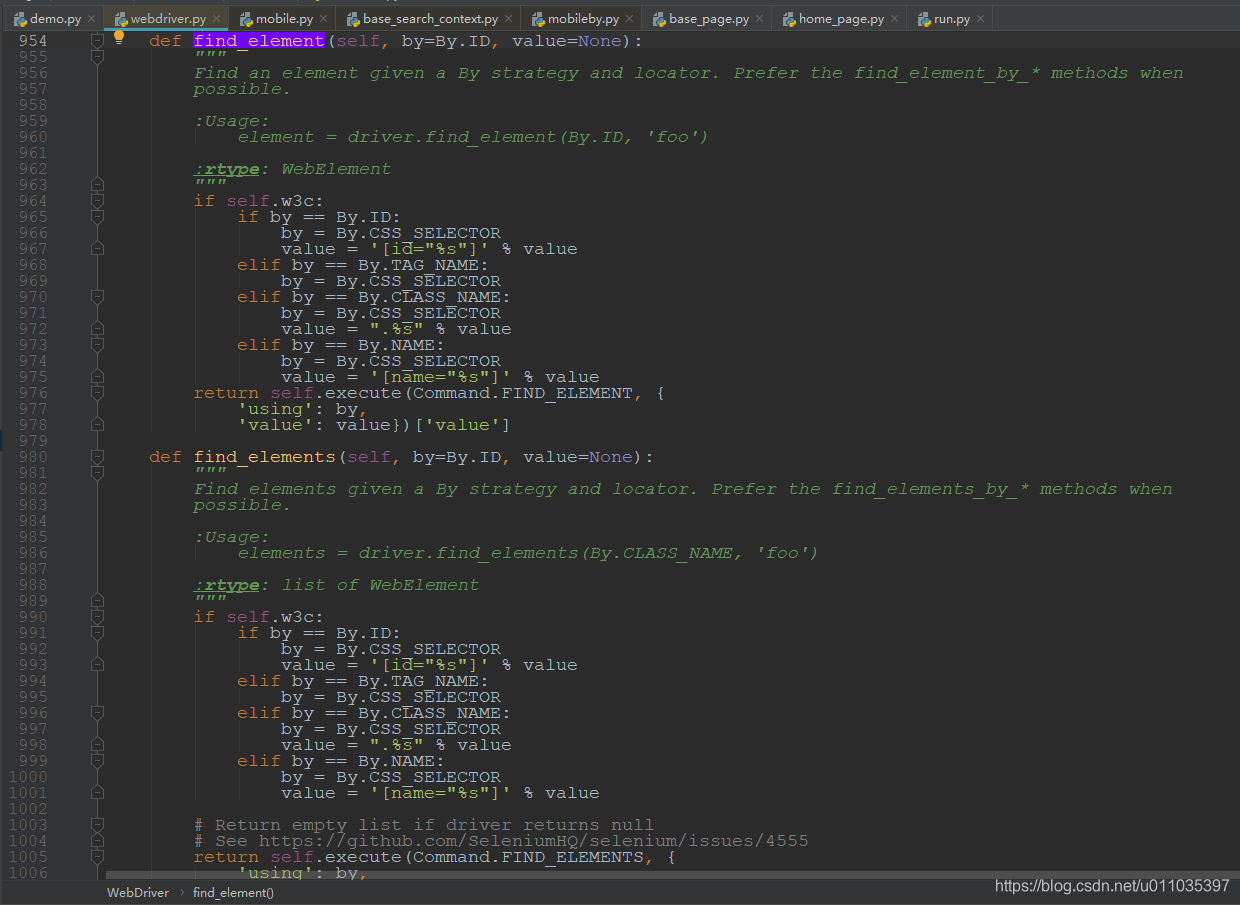
那By又都有哪些条件呢?
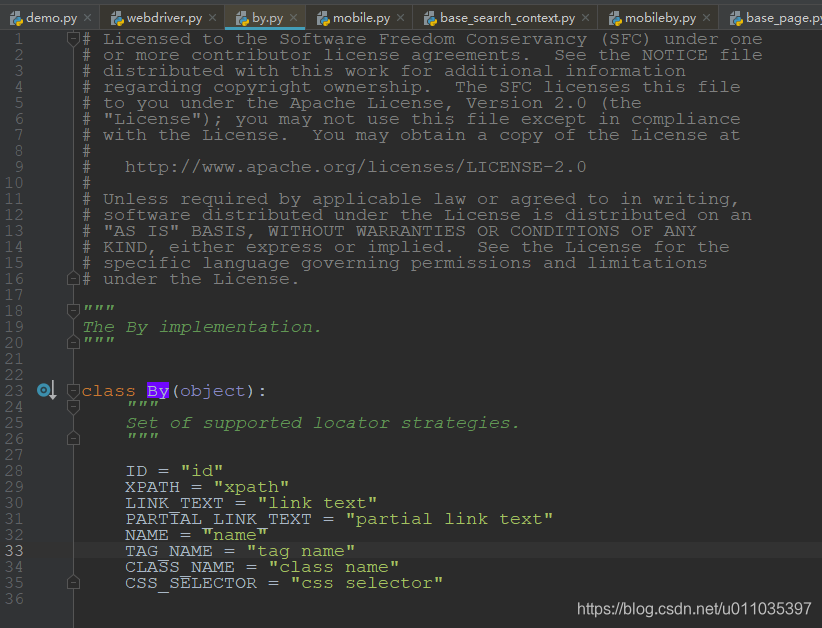
D:\Program Files\Python27\Lib\site-packages\selenium\webdriver\common\by.py
继续看源码,可以看到下面8种
ID = “id”
XPATH = “xpath”
LINK_TEXT = “link text”
PARTIAL_LINK_TEXT = “partial link text”
NAME = “name”
TAG_NAME = “tag name”
CLASS_NAME = “class name”
CSS_SELECTOR = “css selector”
所以我们以后就都只用find_element()就好了,因为最终实际上也都是调用的这个方法。
简单封装一下,以后就记住find_element()一个方法即可。
from selenium.common.exceptions import TimeoutException
from selenium.webdriver.support.ui import WebDriverWait
from appium import webdriver
class BasePage(object):
def split_locator(self, locator):
"""
分解定位表达式,如'css,.username',拆分后返回'css selector'和定位表达式'.username'(class为username的元素)
:param locator: 定位方法+定位表达式组合字符串,如'css,.username'
:return: locator_dict[by], value:返回定位方式和定位表达式
"""
by = locator.split(',')[0]
value = locator.split(',')[1]
locator_dict = {
'id': 'id',
'name': 'name',
'class': 'class name',
'tag': 'tag name',
'link': 'link text',
'plink': 'partial link text',
'xpath': 'xpath',
'css': 'css selector',
}
if by not in locator_dict.keys():
raise NameError("wrong locator!'id','name','class','tag','link','plink','xpath','css',exp:'id,username'")
return locator_dict[by], value
def wait_element(self, locator, sec=30):
"""
等待元素出现
:param locator: 定位方法+定位表达式组合字符串,用逗号分隔,如'css,.username'
:param sec:等待秒数
"""
by, value = self.split_locator(locator)
try:
WebDriverWait(self.driver, sec, 1).until(lambda x: x.find_element(by=by, value=value),message='element not found!!!')
log.info(u'等待元素:%s' % locator)
return True
except TimeoutException:
return False
except Exception, e:
raise e
def get_element(self, locator, sec=60):
"""
获取一个元素
:param locator: 定位方法+定位表达式组合字符串,用逗号分隔,如'css,.username'
:param sec:等待秒数
:return: 元素可找到返回element对象,否则返回False
"""
if self.wait_element(locator, sec):
by, value = self.split_locator(locator)
try:
element = self.driver.find_element(by=by, value=value)
log.info(u'获取元素:%s' % locator)
return element
except Exception, e:
raise e
else:
return False
def get_elements(self, locator):
"""
获取一组元素
:param locator: 定位方法+定位表达式组合字符串,用逗号分隔,如'css,.username'
:return: elements
"""
by, value = self.split_locator(locator)
try:
elements = WebDriverWait(self.driver, 60, 1).until(lambda x: x.find_elements(by=by, value=value))
log.info(u'获取元素列表:%s' % locator)
return elements
except Exception, e:
raise e
以后调用,先定义元素botton,在用例中查找时,调用方法即可
botton="id,su"
get_element(botton) # 页面上id为su的元素
整体框架源码:
https://github.com/songzhenhua/selenium_ui_auto/blob/master/page_object/base_page.py
参考链接:
https://www.cnblogs.com/songzhenhua/p/12902288.html
















 1103
1103











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











