







线程IO模型
Redis 是个单线程程序!
Redis 单线程为什么还能这么快?
- 使用单线程减少了线程的竞争切换;
- 使用了多路复用的处理机制;
- 基于内存的运算;
需要注意谨慎操做时间复杂度为 O(n) 级别的指令操作,以防止Redis卡顿
Redis 单线程如何处理那么多的并发客户端连接?
多路复用(通过 select 系统调用同时处理多个通道描述符的读写事件)
相当于NIO
非阻塞 IO 有个处理时机问题
那就是线程要读数据,结果读了一部分就返回了,线程如何知道何时才应该继续读?也就是当数据到来时,线程如何得到通知? 写也是一样,如果缓冲区满了,写不完,剩下的数据何时才应该继续写,线程也应该得到通知。
select模式:
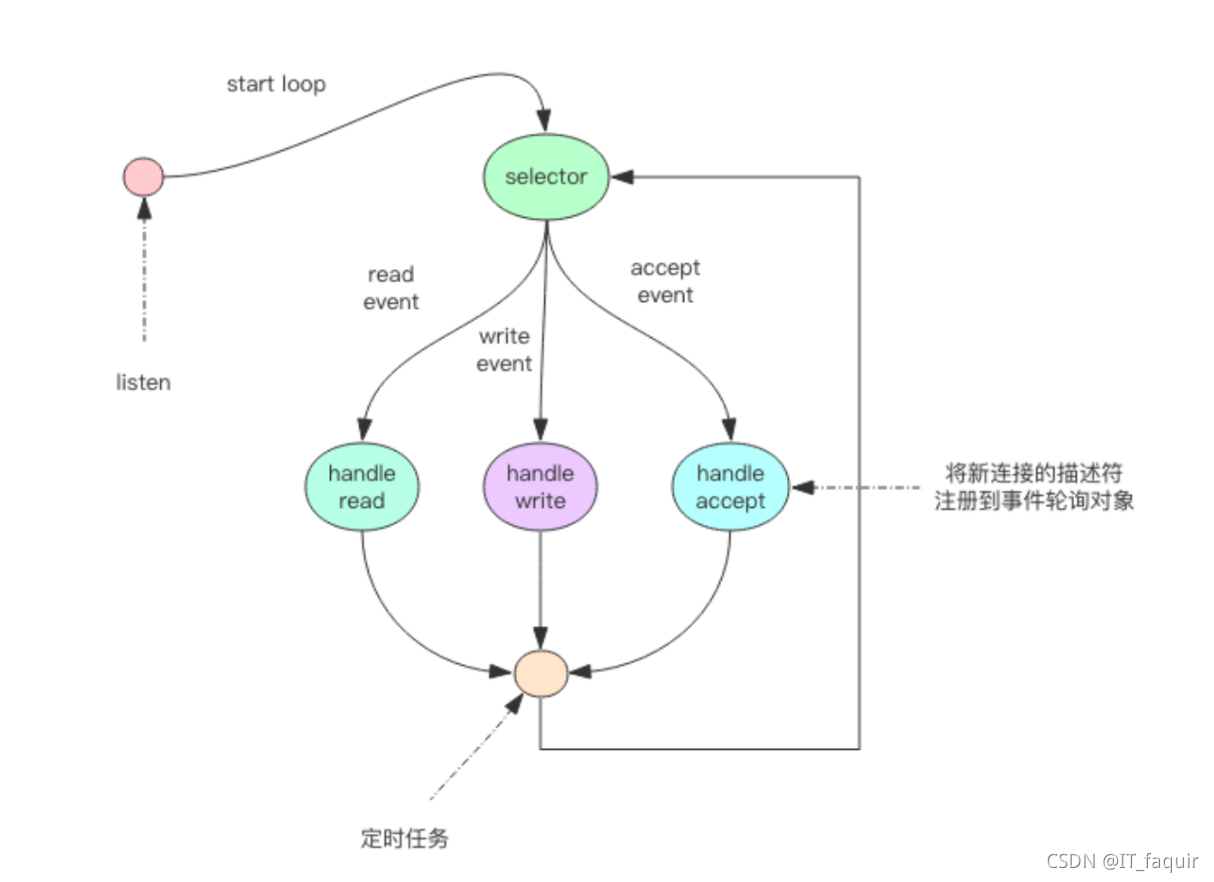
为了解决处理时机问题,使用了事件轮询API(它是操作系统提供给用户程序的 API,select函数是其中最简单的事件轮询函数),死循环方式进行处理(事件循环),一个循环一个周期
epoll 模式:
可参考: https://blog.csdn.net/armlinuxww/article/details/92803381
指令队列:
Redis 会将每个客户端套接字都关联一个指令队列。客户端的指令通过队列来排队进行顺序处理,先到先服务。
响应队列:
Redis 同样也会为每个客户端套接字关联一个响应队列。Redis 服务器通过响应队列来将指令的返回结果回复给客户端。
定时任务:
Redis 的定时任务会记录在一个称为最小堆的数据结构中,这个堆中,最快要执行的任务排在堆的最上方。在每个循环周期,Redis 都会将最小堆里面已经到点的任务立即进行处理。(selet函数 timeout 参数,决定过期情况)
通信协议
Redis 的作者认为数据库系统的瓶颈一般不在于网络流量,而是数据库自身内部逻辑处理上。
所以即使 Redis 使用了浪费流量的文本协议,依然可以取得极高的访问性能。Redis 将所有数据都放在内存,用一个单线程对外提供服务,
单个节点在跑满一个 CPU 核心的情况下可以达到了 10w/s 的超高 QPS。
Redis序列化协议使用自研的RESP(Redis Serialization Protocol) 。它是一种直观的文本协议,优势在于实现异常简单,解析性能极好。
Redis 协议将传输的结构数据分为 5 种最小单元类型,单元结束时统一加上回车换行符号\r\n。
1、单行字符串 以 + 符号开头。
2、多行字符串 以 $ 符号开头,后跟字符串长度。
3、整数值 以 : 符号开头,后跟整数的字符串形式。
4、错误消息 以 - 符号开头。
5、数组 以 * 号开头,后跟数组的长度。
Redis 协议里有大量冗余的回车换行符,但是这不影响它成为互联网技术领域非常受欢
迎的一个文本协议。有很多开源项目使用 RESP 作为它的通讯协议。在技术领域性能并不总
是一切,还有简单性、易理解性和易实现性,这些都需要进行适当权衡。
持久化
Redis宕机怎么办?
Redis 的持久化机制有两种,第一种是快照,第二种是 AOF 日志
快照是一次全量备份,AOF 日志是连续的增量备份。
快照是内存数据的二进制序列化形式,在存储上非常紧凑,而 AOF 日志记录的是内存数据修改的指令记录文本。
AOF 日志在长期的运行过程中会变的无比庞大,数据库重启时需要加载 AOF 日志进行指令重放,这个时间就会无比漫长。
所以需要定期进行 AOF 重写,给 AOF 日志进行瘦身。

快照原理
道 Redis 是单线程程序,无法通过多路复用处理快照的IO操作(会拖垮服务器请求性能)。
怎么实现?Redis 使用操作系统的多进程 COW(Copy On Write) 机制来实现快照持久化
Redis 在持久化时会调用 glibc 的函数 fork 产生一个子进程,快照持久化完全交给子进
程来处理,父进程继续处理客户端请求(父子共享内存)。
进行保存快照时,不是all in处理,而是“页”为单位进行处理,每个页面的大小只有 4K,一个 Redis 实例里面一般都会有成千上万的页面。
AOF原理
AOF 日志存储的是 Redis 服务器的顺序指令序列,AOF 日志只记录对内存进行修改的指令记录。
假设 AOF 日志记录了自 Redis 实例创建以来所有的修改性指令序列,那么就可以通过
对一个空的 Redis 实例顺序执行所有的指令,也就是「重放」,来恢复 Redis 当前实例的内
存数据结构的状态。
redis修改操作指令 -》 存储AOF日志 -》执行指令
AOF瘦身
日志越来越多,导致系统恢复就好越慢,Redis 提供了 bgrewriteaof 指令用于对 AOF 日志进行瘦身。
其原理就是开辟一个子进程 对内存进行遍历转换成一系列 Redis 的操作指令,序列化到一个新的 AOF 日志文件中。
如果机器宕机,AOF日志异步处理则会丢失。可以通过fsyanc指令强制将内核缓存的内容同步到磁盘,尽可能减少丢失,但影响性能。根据实际情况进行取舍
Redis 同样也提供了另外两种策略,一个是永不 fsync——让操作系统来决定合适同步磁盘,很不安全,另一个是来一个指令就 fsync 一次——非常慢。但是在生产环境基本不会使用,了解一下即可。
快照、AOF
1、遍历整个内存,大块写磁盘会加重系统负载
2、AOF 的 fsync 是一个耗时的 IO 操作,它会降低 Redis 性能,同时也会增加系统 IO 负担
混合持久化
Redis 4.0 为了解决这个问题,带来了一个新的持久化选项——混合持久化。将 rdb 文件的内容和增量的 AOF 日志文件存在一起。这里的 AOF 日志不再是全量的日志,而是自持久化开始到持久化结束的这段时间发生的增量 AOF 日志,通常这部分 AOF 日志很小。
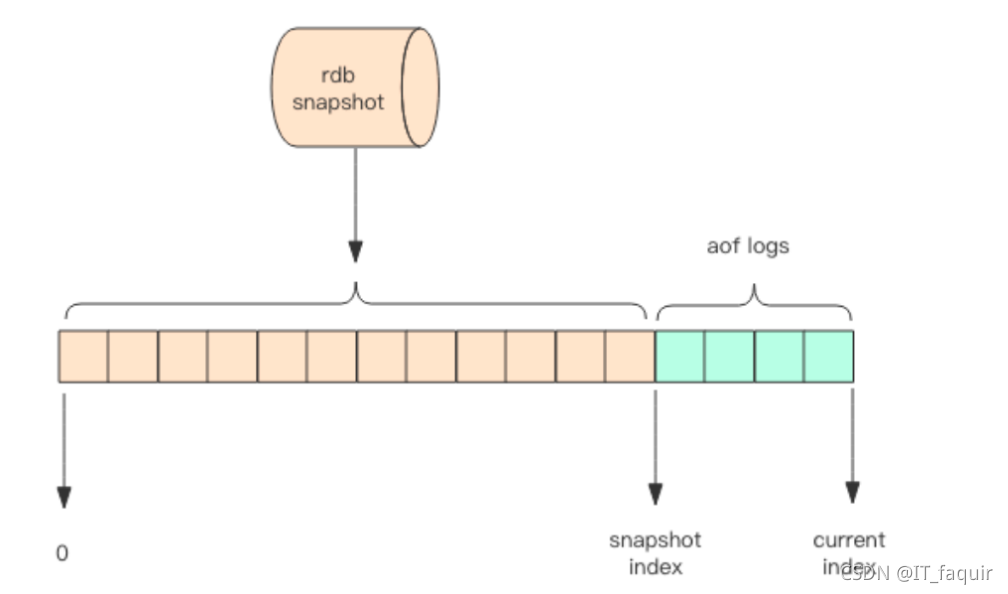
于是在 Redis 重启的时候,可以先加载 rdb 的内容,然后再重放增量 AOF 日志就可以完全替代之前的 AOF 全量文件重放,重启效率因此大幅得到提升。
管道
redis管道不是redis服务器直接提供的,而是由客户端提供。
客户端对管道的优化,客户端通过对管道中的指令列表改变读写顺序就可以大幅节省 IO 时间。管道中指令越多,效果越好。
原:write -> read -> write -> read
现:write -> write -> read -> read
Redis 自带了一个压力测试工具 redis-benchmark,使用这个工具就可以进行管道测试。
t-指令 P-核心数
> redis-benchmark -t set -P 2 -q
SET: 91240.88 requests per second
事务
通常事务的操作都有 begin、commit 和 rollback,begin 指示事务的开始,commit 指示事务的提交,rollback 指示事务的回滚。
Redis 在形式上也差不多,分别是 multi/exec/discard。multi 指示事务的开始,exec 指示事务的执行,discard 指示事务的丢弃(用于丢弃事务缓存队列中的所有指令,在 exec 执行之前。) 注意,redis不支持事务的回滚
> multi
OK
> incr books
QUEUED
> incr books
QUEUED
> exec
(integer) 1
(integer) 2
multi与exec之间的操作指令不执行,而是缓存在服务器的一个事务队列中,直到收到exec指令后才执行
redis分布式锁的是一种悲观锁。
Redis 提供了这种 watch 的机制,它就是一种乐观锁。有了 watch 我们又多了一种可以用来解决并发修改的方法。
Redis 禁止在 multi 和 exec 之间执行 watch 指令,而必须在 multi 之前做好盯住关键变量,否则会出错。
public static int doubleAccount(Jedis jedis, String userId) {
String key = keyFor(userId);
while (true) {
jedis.watch(key);
int value = Integer.parseInt(jedis.get(key));
value *= 2; // 加倍
Transaction tx = jedis.multi();
tx.set(key, String.valueOf(value));
List<Object> res = tx.exec();
if (res != null) {
break; // 成功了
} }
return Integer.parseInt(jedis.get(key)); // 重新获取余额
}
为什么 Redis 的事务不能支持回滚?
1、redis认为错误是在编程过程产生,这些应该在编程过程中避免;
2、增加事务相当于增加了复杂度。没有事务redis才能更好的保证简单且快速;
3、redis一些指令本身就不支持回滚,否则引发错误,如incr命令;
PubSub
PubSub Redis 消息队列的不足之处,那就是它不支持消息的多播机制。
消息不可靠,没有重发机制,没收到就彻底丢了。
近期 Redis5.0 新增了 Stream 数据结构,这个功能给 Redis 带来了持久化消息队列,
从此 PubSub 可以消失了,Disqueue 估计也永远发不出它的 Release 版本了。
小对象压缩存储(ziplist)
Redis 作者为了优化数据结构的内存占用,也苦心孤诣增加了非常多的优化点,这些优化也是以牺牲代码的可读性为代价的。
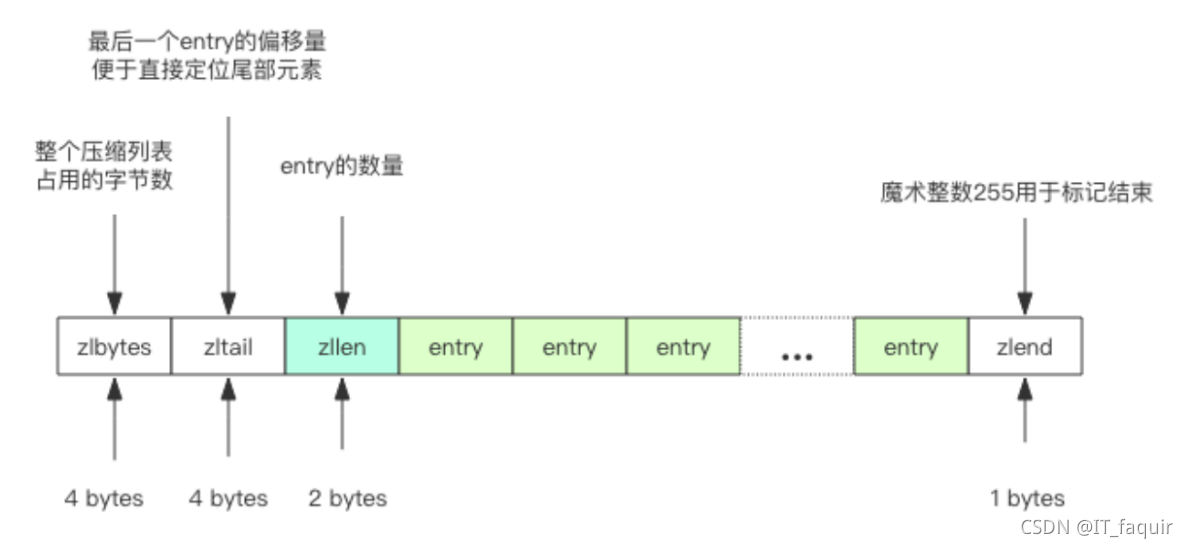
Redis 内部管理的集合数据结构很小,它会使用紧凑存储形式压缩存储(ziplist)。
Redis 的 ziplist 是一个紧凑的字节数组结构,每个元素之间都是紧挨着的。
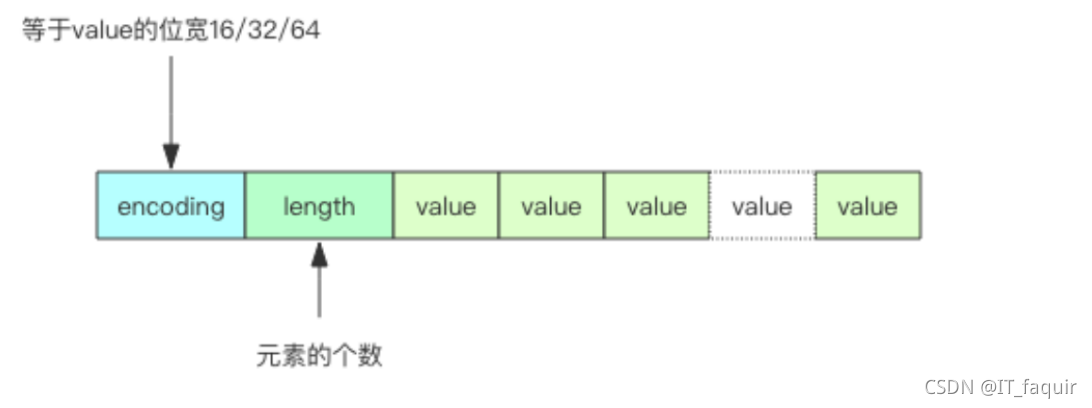
Redis 的 intset 是一个紧凑的整数数组结构,它用于存放元素都是整数的并且元素个数
较少的 set 集合。
如果整数可以用 uint16 表示,那么 intset 的元素就是 16 位的数组,如果新加入的整
数超过了 uint16 的表示范围,那么就使用 uint32 表示,如果新加入的元素超过了 uint32
的表示范围,那么就使用 uint64 表示,Redis 支持 set 集合动态从 uint16 升级到 uint32,
再升级到 uint64。
如果 set 里存储的是字符串,那么 sadd 立即升级为 hashtable 结构
存储界限 当集合对象的元素不断增加,或者某个 value 值过大,这种小对象存储也会
被升级为标准结构。Redis 规定在小对象存储结构的限制条件如下:
hash-max-zipmap-entries 512 # hash 的元素个数超过 512 就必须用标准结构存储
hash-max-zipmap-value 64 # hash 的任意元素的 key/value 的长度超过 64 就必须用标准结构存储
list-max-ziplist-entries 512 # list 的元素个数超过 512 就必须用标准结构存储
list-max-ziplist-value 64 # list 的任意元素的长度超过 64 就必须用标准结构存储
zset-max-ziplist-entries 128 # zset 的元素个数超过 128 就必须用标准结构存储
zset-max-ziplist-value 64 # zset 的任意元素的长度超过 64 就必须用标准结构存储
set-max-intset-entries 512 # set 的整数元素个数超过 512 就必须用标准结构存储
内存回收
Redis 并不总是可以将空闲内存立即归还给操作系统。
如果redis内存使用了10G,删了1G的key,内存并不会有太大变化
原因:操作系统回收内存是以页为单位,如果这个页上只要有一个 key 还在使用,那么它就不能被回收。redis的key会分散到很多页面中。
这种情况怎么办?不用担心,redis会重用那些尚未回收的空闲内存,反而提高效率,无需再找系统分配内存。
内存分配算法
内存分配是一个非常复杂的课题,需要考虑合理划分内存页、处理内存碎片、平衡性能和效率。
Redis将内存分配这块交给三分库jemalloc(facebook)来管理内存,备选tcmalloc。
通过 info memory 指令可以看到 Redis 的 mem_allocator 使用了 jemalloc。
>info memory
sed_memory:35144720
used_memory_human:33.52M
used_memory_rss:47198208
used_memory_rss_human:45.01M
used_memory_peak:37068080
used_memory_peak_human:35.35M
used_memory_peak_perc:94.81%
used_memory_overhead:5024972
used_memory_startup:791264
used_memory_dataset:30119748
used_memory_dataset_perc:87.68%
......
mem_fragmentation_ratio:1.34
mem_allocator:jemalloc-5.1.0
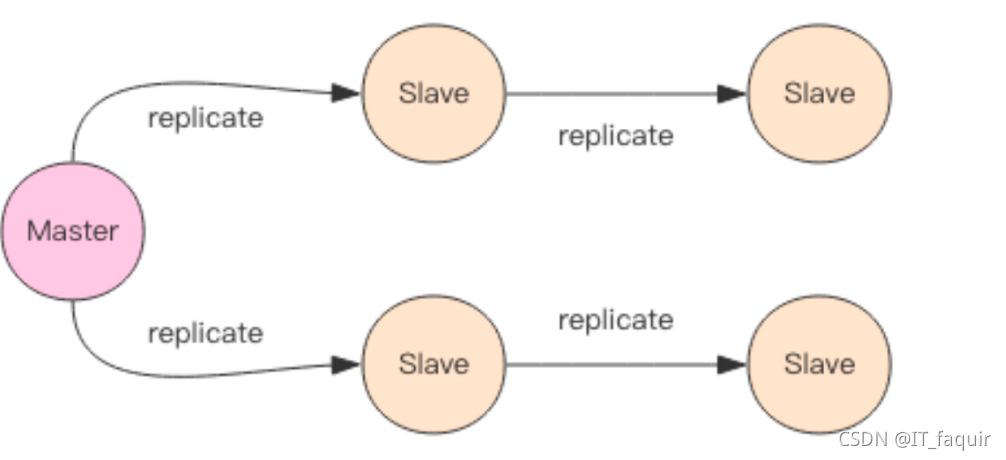
主从同步
redis支持,主从同步和从从同步,统称主从复制。
Redis 的主从数据是异步同步的,不满足一致性要求;主从断开情况下,主节点依旧可以正常对外提供修改服务,满足可用性。
Redis保证最终一致性
CAP 原理就好比分布式领域的牛顿定律,它是分布式存储的理论基石。
- C - Consistent ,一致性
- A - Availability ,可用性
- P - Partition tolerance ,分区容忍性
增量同步
通过一个定长的环形数组作为buffer,主节点将修改操作的指令存到buffer,再异步同步到从节点。
存在问题:如果网络问题,buffer满了还没同步,则会覆盖buffer中老的数据。被覆盖的数据就没法同步?
解决办法:
1、合理调整buffer大小;
2、redis会进行快照同步,达到一致的目的;
快照同步
一个非常耗费资源的操作。需要通过磁盘的IO、同步等过程
主库bgsave(后台异步保存当前数据库的数据到磁盘)-》传输到从节点-》从节点清空数据-》从节点全量加载快照
存在问题:如果快照同步还没有结算,buffer的缓存又满了出现了覆盖,又触发快照同步,陷入一个死循环的窘境,该怎么办?
解决办法:
合理调整buffer大小;
使用无盘复制,提高效率;
无盘复制
Redis 2.8.18 版开始支持
指主服务器直接通过套接字将快照内容发送到从节点,生成快照是一个遍历的过程,主节点会一边遍历内存,一遍将序列化的内容发送到从节点,从节点再进行一次性加载。
wait指令
Redis 的复制是异步进行的,wait 指令可以让异步复制变身同步复制,确保系统的强一致性 (不严格)。wait 指令是 Redis3.0 版本以后才出现的。














 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









