







认识一下
Elasticsearch是一个基于Apache Lucene™的开源搜索引擎,使用Java开发并使用Lucene作为其核心来实现所有索引和搜索的功能,但是它的目的是通过简单的RESTful API来隐藏Lucene的复杂性,从而让全文搜索变得简单。
- Elasticsearch不仅仅是Lucene和全文搜索
- 分布式的实时文件存储,每个字段都被索引并可被搜索
- 分布式的实时分析搜索引擎
- 可以扩展到上百台服务器,处理PB级结构化或非结构化数据以下内容所提到的ES即为elasticsearch
名词解释
集群(cluster):由一个或多个Node组成集群
节点(node):作为集群组成部分,集群中一个elasticsearch进程即为一个的节点。
分片(shard):索引分成若干份(有点分库分表的意思),每一份就是一个shard,默认5个分片,分散在不同的Node上,但不会存在两个相同的Shard存在一个Node上,这样就没有备份的意义了;需要注意其主分片数量是不能修改的,只能更改副本分片数量。如果要更改主分片数量,要先删除索引重新建索引。
备份(replics):是索引的一份或者多份备份,采用的是Push Replication模式,当你往 master主分片上面索引一个文档,该分片会复制该文档(document)到剩下的所有 replica副本分片中。
索引(index):index相当于数据库概念对于提供全文检索的工具来说,只有通过索引操作,才能对数据进行分析存储、创建倒排索引,从而让使用者查询到相关的信息。
类型(type):类型相当于表的概念;在6.0.0版本为保持兼容,仍然会支持单index,多type结构;在elasticsearch 7.0.0版本必须使用单index,单type,多type结构则会完全移除
文档(document):文件相当于一行数据,在ES中以JSON格式存在,对字段没有特定的约束,可自由增减变换;
字段(field):字段作为ES最小组成部分,即document中key的存在,value拥有复杂的数据结构,比如包含日期、地理位置、另一个对象或者数组。
关系型数据库与ES概念比对
| ID | 关系型数据库 | elasticsearch |
|---|---|---|
| 1 | Database | Index |
| 2 | Table | Type |
| 3 | Row | Document |
| 4 | Column | Field |
| 5 | Schema | Mapping |
| 6 | Index | Everything is indexed |
| 7 | SQL | Query DSL |
| 8 | SQL语句 | Restful Api |
归结:
Relational DB ⇒ Databases ⇒ Tables ⇒ Rows ⇒ Columns
vElasticsearch ⇒ Indices ⇒ Types ⇒ Documents ⇒ Fields
一个ES集群可以包含多个索引(数据库),每个索引又包含了很多类型(表),类型中包含了很多文档(行),每个文档又包含了很多字段(列)。
传统数据库为特定列增加一个索引,例如B-Tree索引来加速检索。Elasticsearch和Lucene使用一种叫做倒排索引(inverted index)的数据结构来达到相同目的。
知识点:
- Elasticsearch没有典型意义的事务;Elasticsearch是一种面向文档的数据库;Elasticsearch没有提供授权和认证特性
- 在Elasticsearch中,所有的字段缺省都建了索引。 也就是说每一个字段都有一个倒排索引,用于快速查询。
- ES支持http协议(json格式)(9200端口)、thrift、servlet、memcached、zeroMQ等的传输协议(通过插件方式集成)。传统关系型数据库不支持。
- es支持分片和副分片,从而方便水平分割和扩展,复制保证了es的高可用与高吞吐。
快速安装
- 需要有java环境(jdk1.7+),这里不多说
2.下载ES压缩包 https://www.elastic.co/cn/downloads/elasticsearch 根据你的系统下载相应版本即可; - 解压后,到对应目录的bin下,运行即可
./bin/elasticsearch - Linux中可以使用一些方式,查看是否启动成功,window和mac可以直接访问以下http地址
curl ‘http://localhost:9200/?pretty’
将看到如下类似信息
{
"name": "VUAuYKQ",
"cluster_name": "elasticsearch_hgspiece",
"cluster_uuid": "tkZteasFSaS6qVRP7Ntn3A",
"version": {
"number": "6.2.4",
"build_hash": "ccec39f",
"build_date": "2018-04-12T20:37:28.497551Z",
"build_snapshot": false,
"lucene_version": "7.2.1",
"minimum_wire_compatibility_version": "5.6.0",
"minimum_index_compatibility_version": "5.0.0"
},
"tagline": "You Know, for Search"
}
这就意味着你现在已经启动并运行一个 Elasticsearch 节点了,你可以用它做实验了。
这里需要特别说明
ES提供两个端口**9200和9300,**它们之间的区别:
9300端口: ES节点之间通讯使用
9200端口: ES节点 和 外部 通讯使用
9300是tcp通讯端口,集群间和TCPClient都走的它;9200是http协议的RESTful接口
集群搭建
单个节点可以作为一个运行中的 Elasticsearch 的实例。 而一个集群是一组拥有相同 cluster.name 的节点, 他们能一起工作并共享数据,还提供容错与可伸缩性。(当然,一个单独的节点也可以组成一个集群) 你可以在 elasticsearch.yml 配置文件中修改 cluster.name ,该文件会在节点启动时加载,这个重启服务后才会生效。
elasticsearch.yml在’/elasticsearch/6.2.4/libexec/config’下
找到以下信息进行修改即可
# ---------------------------------- Cluster -----------------------------------
#
# Use a descriptive name for your cluster:
#
cluster.name: elasticsearch_hgspiece
在配置中你还能修改Node信息(Node)、数据/日志存放日志(Paths)、内存配置(Memory)、网络配置(Network)、服务发现配置(Discovery)、网管(Gateway)、版本(Version),可根据您的具体情况进行修改。
示例
- 准备好多台机器或虚拟机或者直接使用Docker
如:准备三台cenots7环境,设置好ip hostname。
192.168.1.94 es1
192.168.1.92 es2
192.168.1.93 es3
- 安装好es或docker中通过镜像运行
- 修改elasticsearch.yml的cluster.name一致,
- 修改服务发现,修改elasticsearch.yml的Discovery中’discovery.zen.ping.unicast.hosts: ’
添加集群中的主机地址,会自动发现并自动选择master主节点 ,注意由于集群是可能动态扩展的,在使用中会动态加节点,但是这里只要写当前的集群节点就可以了。
如es1的配置:
discovery.zen.ping.unicast.hosts: ["es3", "es2"]#只需要添加另外两台的服务名即可
启动后可以访问以下链接查看情况;
http://192.168.1.94:9200/_cluster/state?pretty
内容较长,这里不给出,可以在’nodes’下看到节点信息
插件
为了更好操作ES,我们可以使用插件进行辅助,提供效率
比如ik分词器、可视化平台Kibana、cerebro可视化操作平台等
可参考:https://www.cnblogs.com/ZJ199012/p/6094083.html
Elasticsearch好奇五问?
到这里对ES及其安装都略有了解了,这里突然想一个问题:数据,在集群中的存储过程及检索过程的是怎样的?主副分片直接如何同步数据的?ES又是怎么选举的?等等问题
对应这些问题很多人都说的不清不楚或者不知道,这里作者对这个问题做了一些整理,希望对你有帮助
问题1:Elasticsearch保存文档,数据落在哪个分片上?
ES使用一个简单算法进行选择
shard = hash(routing) % number_of_primary_shards
routing值是一个任意字符串,它默认是_id,但也可以自定义。这个routing字符串通过哈希函数生成一个数字,然后除以主分片的数量得到一个余数(remainder),余数的范围永远是0到number_of_primary_shards - 1,这个数字就是特定文档所在的分片。这也是为什么分片确定之后不可变的原因,否则之前所确定的位置都会发生变化。
问题2:Elasticsearch多节点情况,请求发送到哪个节点?
我们能够发送请求给集群中任意一个节点。因为每个节点都有能力处理任意请求。每个节点都知道任意文档所在的节点,所以也可以将请求转发到需要的节点。接收请求的节点称之为请求节点(requesting node)。
问题3:Elasticsearch主分配与副分片是如何交互的?
这个问题需要从读、写、读写三个方向进行说明,下面会以三个node的集群,新建一个index,拥有两个主分片和两副分片为例。
写操作:
新建、索引和删除请求都是写(write)操作,它们必须在主分片上成功完成才能复制到相关的副分片上,默认情况同步过程,你可以通过设置replication为async达到异步同步数据。
不建议设置异步:默认的sync复制允许Elasticsearch强制反馈传输。async复制可能会因为在不等待其他分片就绪的情况下发送过多的请求而使Elasticsearch过载。
以下是一个写操作的必要过程
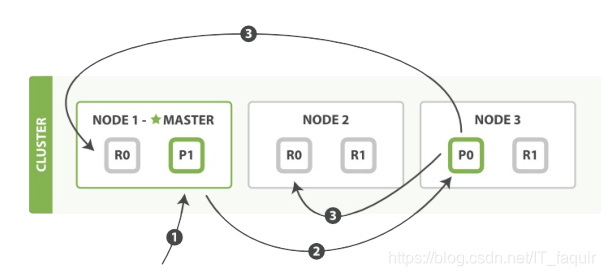
1、客户端给 Node 1 发送新建、索引或删除请求。
2、节点使用文档的_id确定文档属于分片0,它转发请求到 Node 3,分片 0 位于这个节点上。
3、Node 3在主分片上执行请求,如果成功,它转发请求到相应的位于 Node 1 和 Node 2 的复制节点。当所有的复制节点报告成功, Node 3报告成功到请求的节点,请求的节点再报告给客户端。
注意:新索引默认有1个复制分片,这意味着为了满足quorum的要求需要两个活动的分片。当然这个默认设置将阻止我们在单一节点集群中进行操作。为了避免这个问题,规定数量只有在number_of_replicas大于一时才生效。
读操作:
文档能够从主分片或任意一个复制分片被检索。
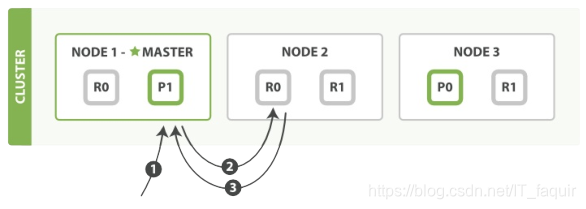
下面罗列在主分片或副分片上检索一个文档必要的顺序步骤:
- 客户端给 Node 1发送get请求。
- 节点使用文档的_id确定文档属于分片0。分片0对应的副分片在三个节点上都有。此时它转发请求到Node 2。
- Node 2 返回 endangered给 Node 1然后返回给客户端。
对于读请求,为了平衡负载,请求节点会为每个请求选择不同的分片——它会循环所有分片副本。
当主副分片数据为异步时,一个被索引的文档已经存在于主分片上却还没来得及同步到副分片上。这时副分片会报告文档未找到,主分片会成功返回文档。一旦索引请求成功返回给用户,文档则在主分片和副分片都是可用的。
读写操作:
这种情况主要出现在对文档的更新操作
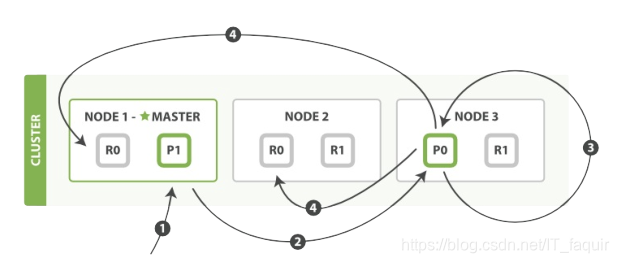
- 客户端给Node 1发送更新请求。
- 它转发请求到主分片所在节点Node 3。
- Node 3 从主分片检索出文档,修改_source字段的JSON,然后在主分片上重建索引。如果有其他进程修改了文档,它以
retry_on_conflict设置的次数重复步骤3,都未成功则放弃。 - 如果Node 3 成功更新文档,它同时转发文档的新版本到Node 1 和 Node 2上的复制节点以重建索引。当所有复制节点报告成功,Node 3 返回成功给请求节点,然后返回给客户端。
注意:ES的更新操作并不是像mysql一个进行真正更新操作,而是原有文档修改后的新版本;这些修改转发到副节点是异步的。
问题4:Elasticsearch是如何实现Master选举的?
Elasticsearch的选主是ZenDiscovery模块负责的,主要包含Ping(节点之间通过这个RPC来发现彼此)和Unicast(单播模块包含一个主机列表以控制哪些节点需要ping通)这两部分;
对所有可以成为master的节点(node.master: true)根据nodeId字典排序,每次选举每个节点都把自己所知道节点排一次序,然后选出第一个(第0位)节点,暂且认为它是master节点。
如果对某个节点的投票数达到一定的值(可以成为master节点数n/2+1)并且该节点自己也选举自己,那这个节点就是master。否则重新选举一直到满足上述条件。
补充:master节点的职责主要包括集群、节点和索引的管理,不负责文档级别的管理;data节点可以关闭http功能。
问题5:Elasticsearch对于大数据量(上亿量级)的聚合如何实现?
掌握Aggregations需要理解两个概念:
桶(Buckets):符合条件的文档的集合,相当于SQL中的group by。比如,在users表中,按“地区”聚合,一个人将被分到北京桶或上海桶或其他桶里;按“性别”聚合,一个人将被分到男桶或女桶。
指标(Metrics):基于Buckets的基础上进行统计分析,相当于SQL中的count,avg,sum等。比如,按“地区”聚合,计算每个地区的人数,平均年龄等;
想象一下在PD级别的数据中去操作一个文档,那岂不是犹如大海捞针,即使是计算机也快不到哪去。因此ES会分析和总结全套的数据而不是寻找单个文档,也就是上面所说的两个概念。
聚合允许我们向数据提出一些复杂的问题。虽然功能完全不同于搜索,但它使用相同的数据结构。这意味着聚合的执行速度很快并且就像搜索一样几乎是实时的。
这对报告和仪表盘是非常强大的。你可以实时显示你的数据,让你立即回应,而不是对你的数据进行汇总( 需要一周时间去运行的 Hadoop 任务 ),您的报告随着你的数据变化而变化,而不是预先计算的、过时的和不相关的。
最后,聚合和搜索是一起的。 这意味着你可以在单个请求里同时对相同的数据进行搜索/过滤和分析。并且由于聚合是在用户搜索的上下文里计算的,你不只是显示四星酒店的数量,而是显示匹配查询条件的四星酒店的数量。
参考:
https://www.elastic.co/guide/cn/elasticsearch/guide/current/index.html
https://www.cnblogs.com/dennisit/p/4133131.html
https://blog.csdn.net/en_joker/article/details/77937405














 170
170











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









