







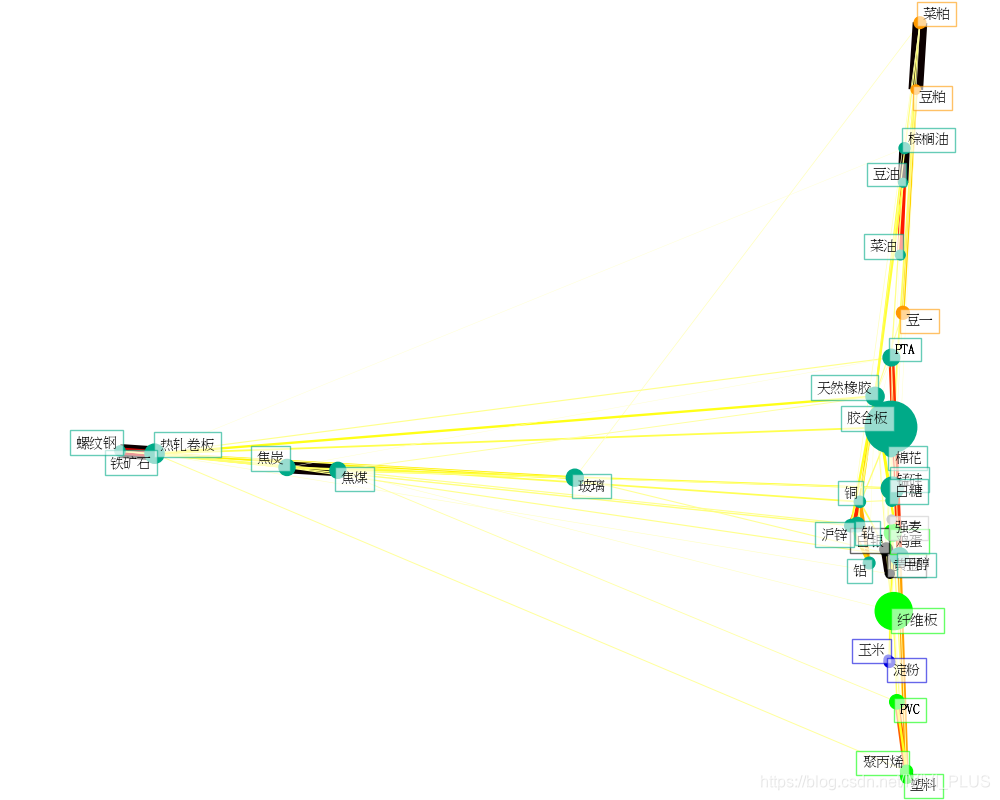
 本文通过获取新浪财经的商品期货日K线数据,利用Python进行数据处理和聚类分析,最终使用Matplotlib可视化聚类结果,展示了商品期货之间的结构关系。
本文通过获取新浪财经的商品期货日K线数据,利用Python进行数据处理和聚类分析,最终使用Matplotlib可视化聚类结果,展示了商品期货之间的结构关系。
参考了SKLearn官网上的示例Visualizing the stock market structure
结果如图:
安装MYSQL,创建数据库
sudo apt install mysql-server
sudo mysql
sudo打开mysql后创建名为ClusteringFutures的数据库,并创建和授权一般用户。Ctrl+c退出
CREATE DATABASE ClusteringFutures;
USE ClusteringFutures;
CREATE USER 'IVIVI_PLUS'@'localhost' IDENTIFIED BY '123456';
GRANT ALL PRIVILEGES ON ClusteringFutures.* TO 'IVIVI_PLUS'@'localhost';
FLUSH PRIVILEGES;
验证以上操作,以一般用户进入数据库。
mysql -u IVIVI_PLUS -p ClusteringFutures
至此,MYSQL准备工作完成。
Python端
基本流程:
1、从新浪财经获取国内商品期货的日K线数据。
2、数据导入MYSQL
3、清洗数据
4、计算单日涨跌幅,作为聚类模型训练的输入
5、SKLearn聚类
6、Matplotlib进行可视化
import requests
import pymysql
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.collections import LineCollection
from sklearn import cluster, covariance, manifold
# 商品期货代码与名称字典
# symbol_dict = {
# 'TA0': 'PTA',
# 'OI0': '菜油',
# 'RS0': '菜籽',
# 'RM0': '菜粕',
# 'ZC0': '动力煤',
# 'WH0': '强麦',
# 'JR0': '粳稻',
# 'SR0': '白糖',
# 'CF0': '棉花',
# 'RI0': '早籼稻',
# 'MA0': '甲醇',
# 'FG0': '玻璃',
# 'LR0': '晚籼稻',
# 'SF0': '硅铁',
# 'SM0': '锰硅',
# 'CY0': '棉纱',
# 'AP0': '苹果',
# 'CJ0': '红枣',
# 'V0': 'PVC',
# 'P0': '棕榈油',
# 'B0': '豆二',
# 'M0': '豆粕',
# 'I0': '铁矿石',
# 'JD0': '鸡蛋',
# 'L0': '塑料',
# 'PP0': '聚丙烯',
# 'FB0': '纤维板',
# 'BB0': '胶合板',
# 'Y0': '豆油',
# 'C0': '玉米',
# 'A0': '豆一',
# 'J0': '焦炭',
# 'JM0': '焦煤',
# 'CS0': '淀粉',
# 'EG0': '乙二醇',
# 'FU0': '燃料油',
# 'SC0': '上海原油',
# 'AL0': '铝',
# 'RU0': '天然橡胶',
# 'ZN0': '沪锌',
# 'CU0': '铜',
# 'AU0': '黄金',
# 'RB0': '螺纹钢',
# 'WR0': '线材',
# 'PB0': '铅',
# 'AG0': '白银',
# 'BU0': '沥青',
# 'HC0': '热轧卷板',
# 'SN0': '锡',
# 'NI0': '镍',
# 'SP0': '纸浆'}
symbol_dict = {
'TA0': 'PTA',
'OI0': '菜油',
'RM0': '菜粕',
'WH0': '强麦',
'SR0': '白糖',
'CF0': '棉花',
'MA0': '甲醇',
'FG0': '玻璃',
'SM0': '锰硅',
'V0': 'PVC',
'P0': '棕榈油',
'M0': '豆粕',
'I0': '铁矿石',
'JD0': '鸡蛋',
'L0': '塑料',
'PP0': '聚丙烯',
'FB0': '纤维板',
'BB0': '胶合板',
'Y0': '豆油',
'C0': '玉米',
'A0': '豆一',
'J0': '焦炭',
'JM0' 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2427
2427

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









