









 该文详细介绍了使用L1正则化进行信号降噪的方法,通过构建对偶问题和应用梯度投影法解决含L1正则项的优化问题。对比L2正则化,L1正则化在处理信号间断点时表现更优,能够更好地捕捉信号的突变。实验中展示了L1正则化如何在1000次迭代后得到信号的近似恢复。
该文详细介绍了使用L1正则化进行信号降噪的方法,通过构建对偶问题和应用梯度投影法解决含L1正则项的优化问题。对比L2正则化,L1正则化在处理信号间断点时表现更优,能够更好地捕捉信号的突变。实验中展示了L1正则化如何在1000次迭代后得到信号的近似恢复。
L1正则化降噪,对偶函数的构造,求解含L1正则项的优化问题,梯度投影法
本文主要实现L1正则化降噪,L2 正则化降噪的文章在:
https://blog.csdn.net/IYXUAN/article/details/121565229

原创文章!转载需注明来源:©️ Sylvan Ding’s Blog ❤️
实验目的
- 学会使用L1正则化项求解降噪问题;
- 构造原问题的对偶问题,以求解含L1正则项的优化问题;
- 使用梯度投影法,求解带约束的优化问题;
- 在降噪过程中,注意对比L1和L2正则化的区别,并分析使用L1正则项在此降噪问题中的优势。
实验环境
MATLAB R2021a
实验内容
L2正则化
本文主要实现L1正则化降噪,L2 正则化降噪的文章在:
https://blog.csdn.net/IYXUAN/article/details/121565229
假设有一段被噪声污染的信号,即 y = x + w , x , w , y ∈ R n y=x+w,\ x,w,y\in \mathbb{R}^n y=x+w, x,w,y∈Rn . 其中, x x x 是不含噪声的源信号, w w w 是一未知噪声, y y y 是观察到的含噪信号。
目标是从观察到的信号 y y y 还原出源信号 x x x . 在实验一中,我们假设最初的信号是一段光滑的曲线,选用二次惩罚(Quadratic Penalty)作为正则化项,则有
x ∗ = arg min x ∥ x − y ∥ 2 + λ ∥ L x ∥ 2 , λ > 0 x^* = \arg \min \limits_{x} \Vert x-y \Vert ^2+\lambda \Vert Lx \Vert ^2, \lambda>0 x∗=argxmin∥x−y∥2+λ∥Lx∥2,λ>0
其中, x ∗ x^* x∗ 是所求得的最优解, L ∈ R ( n − 1 ) × n L\in \mathbb{R}^{(n-1)\times n} L∈R(n−1)×n ,
L = [ 1 − 1 0 0 ⋯ 0 0 0 1 − 1 0 ⋯ 0 0 0 0 1 − 1 ⋯ 0 0 ⋮ ⋮ ⋮ ⋮ ⋮ ⋮ 0 0 0 0 ⋯ 1 − 1 ] L= \begin{bmatrix} 1 & -1 & 0 & 0 & \cdots & 0 &0 \\ 0 & 1 & -1 & 0 & \cdots & 0 & 0\\ 0 & 0 & 1 & -1 & \cdots & 0 & 0\\ \vdots & \vdots & \vdots & \vdots & & \vdots & \vdots \\ 0 & 0 & 0 & 0 & \cdots & 1 & -1 \end{bmatrix} L=⎣⎢⎢⎢⎢⎢⎡100⋮0−110⋮00−11⋮000−1⋮0⋯⋯⋯⋯000⋮1000⋮−1⎦⎥⎥⎥⎥⎥⎤
利用最小二乘法,可以解得 x ∗ ( λ ) = ( I + λ L T L ) − 1 y x^*(\lambda) = \left ( I+\lambda L^T L \right )^{-1}y x∗(λ)=(I+λLTL)−1y .
L1正则化
然而,这种使用二次惩罚作为正则项,接着使用最小二乘求解的方法具有一定的局限性,在某些情况下,无论正则化参数 λ \lambda λ 如何设置,都不能得到理想的解。事实上,对于存在断点的信号(比如脉冲信号)来说,由于惩罚项 ∥ L x ∥ 2 \Vert Lx \Vert ^2 ∥Lx∥2 是二次的,断点会导致惩罚项的值急剧增大。因此,这种二次惩罚项会让有噪信号的间断点处更加平滑,但这种间断点处的平滑并不是我们希望得到的。
为了缓解这一问题,削弱信号在跳跃处的惩罚项值增大的幅度,我们使用 L1 范数形式的惩罚项,而非二次惩罚,那么优化问题变为(P)
min x ∥ x − y ∥ 2 + λ ∥ L x ∥ 1 \min \limits_{x} \Vert x-y \Vert ^2+\lambda \Vert Lx \Vert _1 xmin∥x−y∥2+λ∥Lx∥1 .
算法描述
构造对偶问题
优化问题(P)等价于如下问题:
min x , z ∥ x − y ∥ 2 + λ ∥ z ∥ 1 s . t . z = L x \begin{array}{l} \min \limits _{x,z} & \Vert x-y \Vert ^2 + \lambda \Vert z \Vert _1 \\ \mathrm{s.t.} & z=Lx \end{array} x,zmins.t.∥x−y∥2+λ∥z∥1z=Lx
那么,拉格朗日函数 L L L 为
L ( x , z , μ ) = ∥ x − y ∥ 2 + λ ∥ z ∥ 1 + μ T ( L x − z ) = ∥ x − y ∥ 2 + ( L T μ ) T x + λ ∥ z ∥ 1 − μ T z \begin{array}{l} L(x,z,\mu) & = \Vert x-y \Vert ^2 + \lambda \Vert z \Vert _1 + \mu ^T (Lx-z) \\ & = \Vert x-y \Vert ^2 + (L^T \mu)^Tx + \lambda \Vert z \Vert _1 - \mu ^Tz \end{array} L(x,z,μ)=∥x−y∥2+λ∥z∥1+μT(Lx−z)=∥x−y∥2+(LTμ)Tx+λ∥z∥1−μTz
对偶目标函数(Dual objective function)为 q ( μ ) = min x , z L ( x , z , μ ) q(\mu)=\min \limits _{x,z} L(x,z,\mu) q(μ)=x,zminL(x,z,μ).
观察 L L L 可以发现,可分别求 x x x 和 z z z 的最优解,即
q ( μ ) = min x { ∥ x − y ∥ 2 + ( L T μ ) T x } + min z { λ ∥ z ∥ 1 − μ T z } q(\mu)=\min \limits _{x} \left \{ \Vert x-y \Vert ^2 + (L^T \mu)^Tx \right \}+ \min \limits _{z} \left \{ \lambda \Vert z \Vert _1 - \mu ^Tz \right \} q(μ)=xmin{∥x−y∥2+(LTμ)Tx}+zmin{λ∥z∥1−μTz}.
q ( μ ) q(\mu) q(μ) 中关于 x x x 部分的最小值
对于 ∥ x − y ∥ 2 + ( L T μ ) T x \Vert x-y \Vert ^2 + (L^T \mu)^Tx ∥x−y∥2+(LTμ)Tx 求关于 x x x 的最小值,显然这是一个二次函数,在梯度消失时,取得最小值,即
2 ( x − y ) + L T μ = 0 2(x-y)+L^T\mu =0 2(x−y)+LTμ=0
解得 x ∗ = y − 1 2 L T μ x^*=y-\frac{1}{2}L^T\mu x∗=y−21LTμ ,故
min x ∥ x − y ∥ 2 + ( L T μ ) T x = − 1 4 μ T L L T μ + μ T L y . \min \limits _{x} \Vert x-y \Vert ^2 + (L^T \mu)^Tx = -\frac{1}{4}\mu ^T LL^T \mu + \mu ^TLy. xmin∥x−y∥2+(LTμ)Tx=−41μTLLTμ+μTLy.
q ( μ ) q(\mu) q(μ) 中关于 z z z 部分的最小值
min z λ ∥ z ∥ 1 − μ T z = { 0 , ∥ μ ∥ ∞ ≤ λ − ∞ e l s e . \min \limits _z \lambda \Vert z \Vert _1 - \mu ^Tz= \left\{\begin{matrix} 0, & \Vert \mu \Vert _\infty \le \lambda \\ - \infty & else. \end{matrix}\right. zminλ∥z∥1−μTz={0,−∞∥μ∥∞≤λelse.
综上,对偶目标函数为
q ( μ ) = min x , z L ( x , z , μ ) = { − 1 4 μ T L L T μ + μ T L y , ∥ μ ∥ ∞ ≤ λ − ∞ e l s e . q(\mu)=\min \limits _{x,z} L(x,z,\mu)= \left\{\begin{matrix} -\frac{1}{4}\mu ^T LL^T \mu + \mu ^TLy, & \Vert \mu \Vert _\infty \le \lambda \\ -\infty & else. \end{matrix}\right. q(μ)=x,zminL(x,z,μ)={−41μTLLTμ+μTLy,−∞∥μ∥∞≤λelse.
那么,对偶问题就为
max − 1 4 μ T L L T μ + μ T L y s . t . ∥ μ ∥ ∞ ≤ λ . \begin{array}{l} \max & -\frac{1}{4}\mu ^T LL^T \mu + \mu ^TLy \\ \mathrm{s.t.} & \Vert \mu \Vert _\infty \le \lambda. \end{array} maxs.t.−41μTLLTμ+μTLy∥μ∥∞≤λ.
使用梯度投影法求解对偶问题
投影的定义
约束域 C : = { μ ∈ R n − 1 : ∥ μ ∥ ∞ ≤ λ } C:=\left \{ \mu \in \mathbb{R} ^{n-1}: \Vert \mu \Vert _\infty \le \lambda \right \} C:={μ∈Rn−1:∥μ∥∞≤λ} 是“盒状的”,即
− λ ≤ μ i ≤ λ , i = 1 , 2 , … , n − 1. -\lambda \le \mu _i \le \lambda, i=1,2,\dots,n-1. −λ≤μi≤λ,i=1,2,…,n−1.
那么, μ \mu μ 在 C C C 上的投影 P C ( μ ) ∈ R n − 1 P_C(\mu ) \in \mathbb{R} ^{n-1} PC(μ)∈Rn−1 为
[ P C ( μ ) ] i : = { − λ , μ i ≤ − λ μ i , − λ ≤ μ i ≤ λ λ , λ ≤ μ i \left [ P_C(\mu ) \right ] _i := \left\{\begin{matrix} -\lambda , & \mu _i \le -\lambda \\ \mu _i , & -\lambda \le \mu _i \le \lambda \\ \lambda , & \lambda \le \mu _i \\ \end{matrix}\right. [PC(μ)]i:=⎩⎨⎧−λ,μi,λ,μi≤−λ−λ≤μi≤λλ≤μi
其中,
i
=
1
,
2
,
…
,
n
−
1
i=1,2,\dots,n-1
i=1,2,…,n−1. 特别的,当
λ
=
1
\lambda = 1
λ=1 时,即 lambda=1 ,有PcMu=lambda*mu./max(abs(mu),lambda); ,PcMu 是
μ
\mu
μ 在
C
C
C 上的投影,即
P
C
(
μ
)
P_C(\mu )
PC(μ).
求解梯度的Lipschitz常数
对偶目标函数 q ( μ ) q(\mu) q(μ) 中, L L T ∈ R ( n − 1 ) × ( n − 1 ) LL^T\in \mathbb{R} ^{(n-1)\times (n-1)} LLT∈R(n−1)×(n−1) 是一个对称矩阵,对 ∀ μ ≠ 0 \forall \mu \ne 0 ∀μ=0 ,有瑞利商(Rayleigh Quotient)
R L L T ( μ ) = μ T L L T μ ∥ μ ∥ 2 = ∥ L μ ∥ 2 ∥ μ ∥ 2 = ∑ i = 1 n − 1 ( μ i − μ i + 1 ) 2 ∥ μ ∥ 2 ≤ 2 ( ∑ i = 1 n − 1 μ i 2 + ∑ i = 1 n − 1 μ i + 1 2 ) ∥ μ ∥ 2 ≤ 4 ∥ μ ∥ 2 ∥ μ ∥ 2 = 4 \begin{array}{l} R_{LL^T}(\mu ) &= \frac{\mu ^TLL^T\mu}{\Vert \mu \Vert ^2} = \frac{\Vert L\mu \Vert ^2}{\Vert \mu \Vert ^2} = \frac{\sum _{i=1} ^{n-1} (\mu _i- \mu _{i+1})^2}{\Vert \mu \Vert ^2} \\ &\le \frac{2\left ( \sum _{i=1} ^{n-1} \mu _i^2 + \sum _{i=1} ^{n-1} \mu _{i+1}^2\right )}{\Vert \mu \Vert ^2} \le \frac{4\Vert \mu \Vert ^2}{{\Vert \mu \Vert ^2}} = 4 \\ \end{array} RLLT(μ)=∥μ∥2μTLLTμ=∥μ∥2∥Lμ∥2=∥μ∥2∑i=1n−1(μi−μi+1)2≤∥μ∥22(∑i=1n−1μi2+∑i=1n−1μi+12)≤∥μ∥24∥μ∥2=4
由 定理1.11 知, R L L T ( μ ) ≤ λ max ( L L T ) R_{LL^T}(\mu ) \le \lambda_{\max} (LL^T) RLLT(μ)≤λmax(LLT) ,即 λ max ( L L T ) ≤ 4 \lambda_{\max} (LL^T) \le 4 λmax(LLT)≤4.
λ max ( L L T ) \lambda_{\max} (LL^T) λmax(LLT) 是 L L T LL^T LLT 的最大特征值
L L T LL^T LLT 的诱导范数(Induced norm)是一个谱范数(Spectral norm),令 A = L L T A=LL^T A=LLT ,则有
∥ A ∥ 2 , 2 = λ max ( A T A ) = λ max ( A ) . \Vert A \Vert _{2,2} = \sqrt{\lambda _{\max} \left ( A^TA\right )}=\lambda _{\max}(A). ∥A∥2,2=λmax(ATA)=λmax(A).
因此,二次函数 − 1 4 μ T L L T μ + μ T L y -\frac{1}{4}\mu ^T LL^T \mu + \mu ^TLy −41μTLLTμ+μTLy 的梯度Lipschitz常数为
L ′ = 2 × ∥ 1 4 A ∥ 2 , 2 = 1 2 λ max ( A ) = 2. L'=2\times \Vert \frac{1}{4} A \Vert _{2,2}=\frac{1}{2}\lambda _{\max}(A)=2. L′=2×∥41A∥2,2=21λmax(A)=2.
综上,可用梯度投影法求解 μ ∗ \mu ^* μ∗ ,令 t k = t ˉ = 1 L ′ t_k=\bar{t} = \frac{1}{L'} tk=tˉ=L′1,则有
μ k + 1 = P C ( μ k − 1 4 L L T μ k + 1 2 L y ) . \mu _{k+1}=P_C \left ( \mu _k -\frac{1}{4} LL^T \mu _k +\frac{1}{2}Ly \right ). μk+1=PC(μk−41LLTμk+21Ly).
定理 9.16 和 9.18 保证了 μ ∗ \mu ^* μ∗ 的收敛性.
假设 μ ∗ \mu ^* μ∗ 为梯度投影法所得结果,那么原问题的解为
x ∗ = y − 1 2 L T μ ∗ . x^* = y-\frac{1}{2}L^T\mu ^*. x∗=y−21LTμ∗.
实验步骤
在L1正则化中,设定 λ = 1 \lambda = 1 λ=1 ,梯度投影的迭代次数为 1000 1000 1000 次.
%% L2正则化
L=sparse(n-1,n);
for i=1:n-1
L(i,i)=1;
L(i,i+1)=-1;
end
lambda=100;
xde=(speye(n)+lambda*L'*L)\y;
figure(3)
plot(t,xde);
randn('seed',314);
x=zeros(1000,1);
x(1:250)=1;
x(251:500)=3;
x(501:750)=0;
x(751:1000)=2;
figure(1)
plot(1:1000,x,'.')
axis([0,1000,-1,4]);
y=x+0.05*randn(size(x));
figure(2)
plot(1:1000,y,'.')
%% L1正则化
lambda=1;
mu=zeros(n-1,1);
for i=1:1000
mu=mu-0.25*L*(L'*mu)+0.5*(L*y);
mu=lambda*mu./max(abs(mu),lambda);
xde=y-0.5*L'*mu;
end
figure(5)
plot(t,xde,'.');
axis([0,1,-1,4])
结果分析
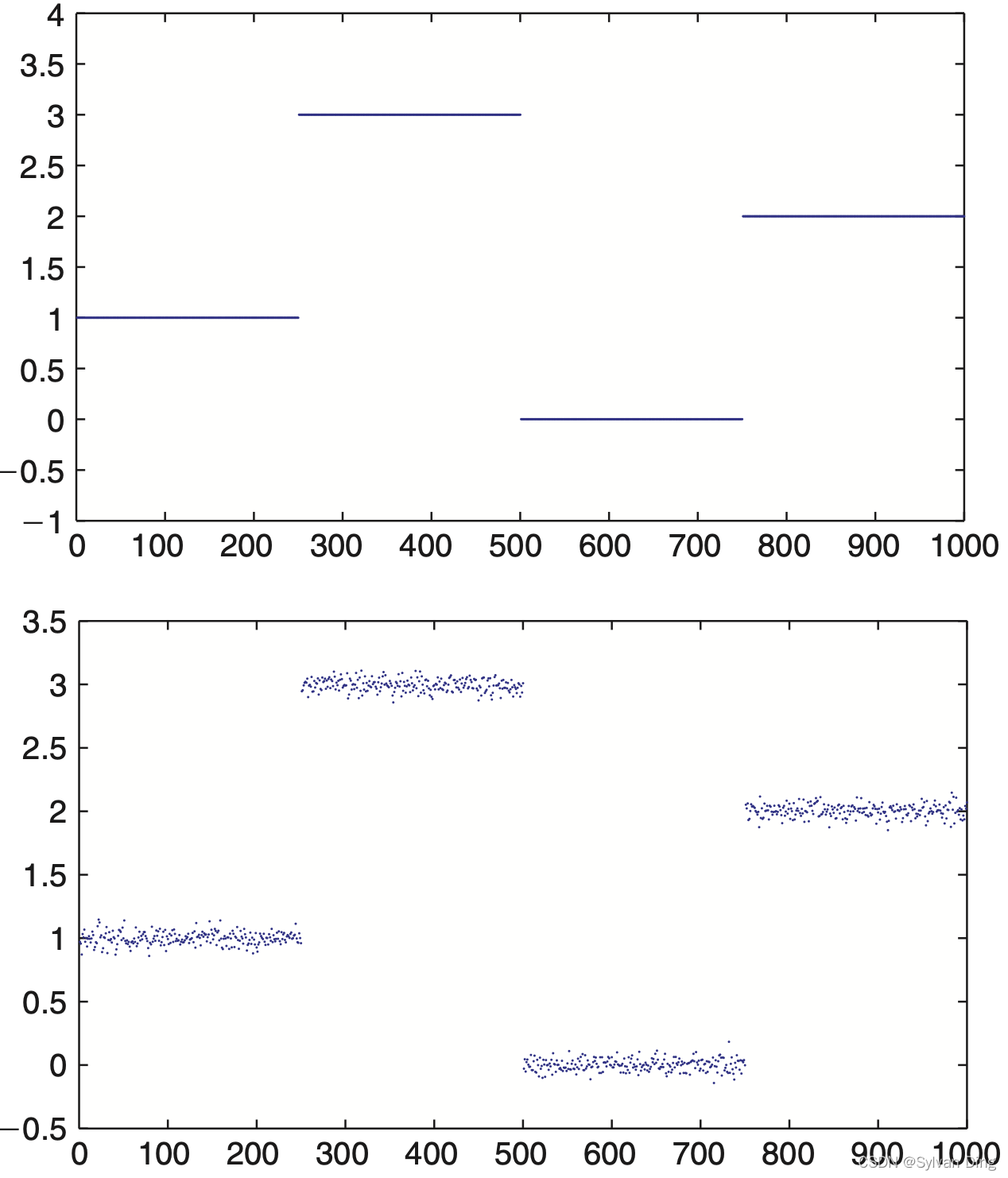
Figure 12.4. True signal (top image) and noisy signal (bottom image).
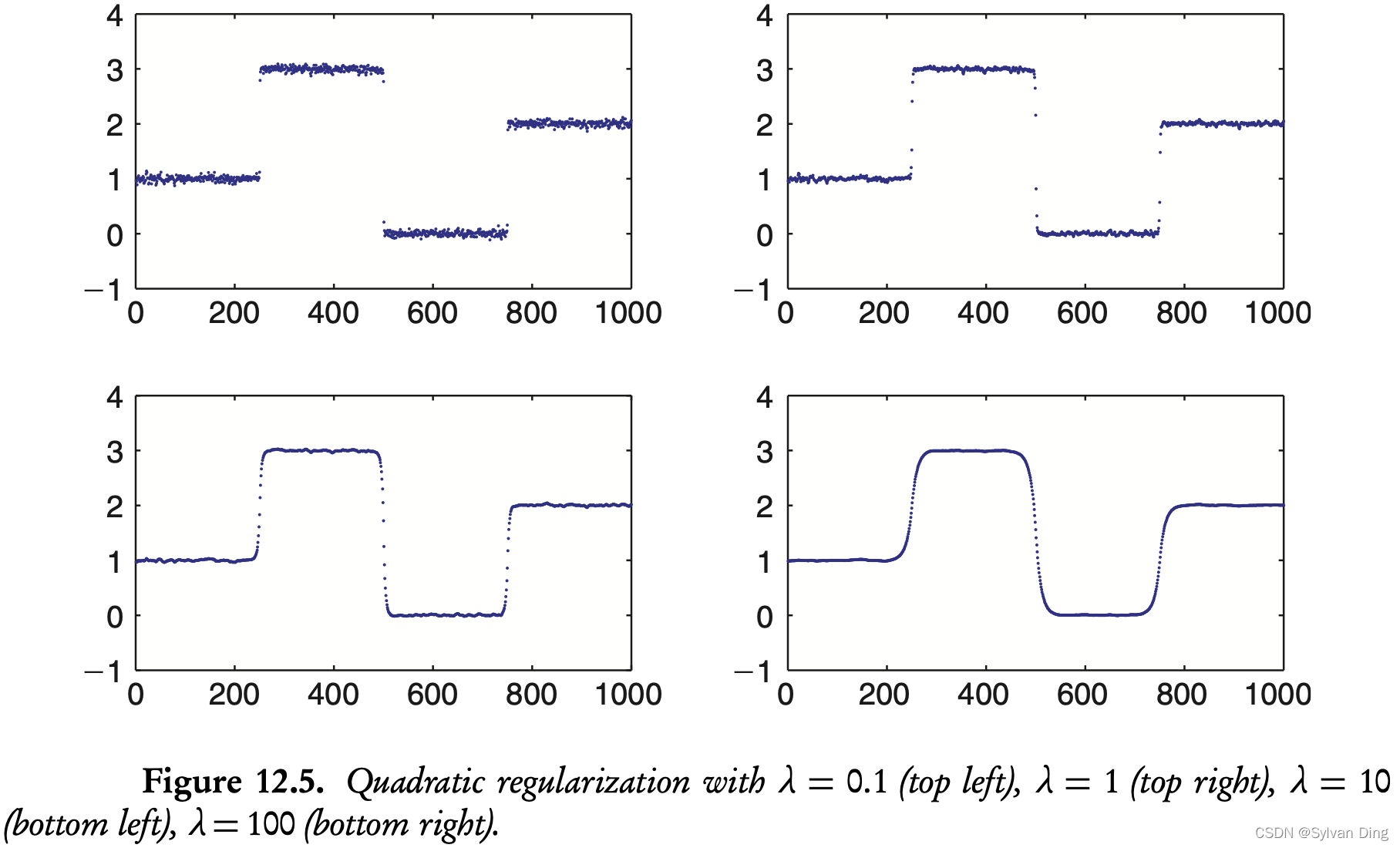
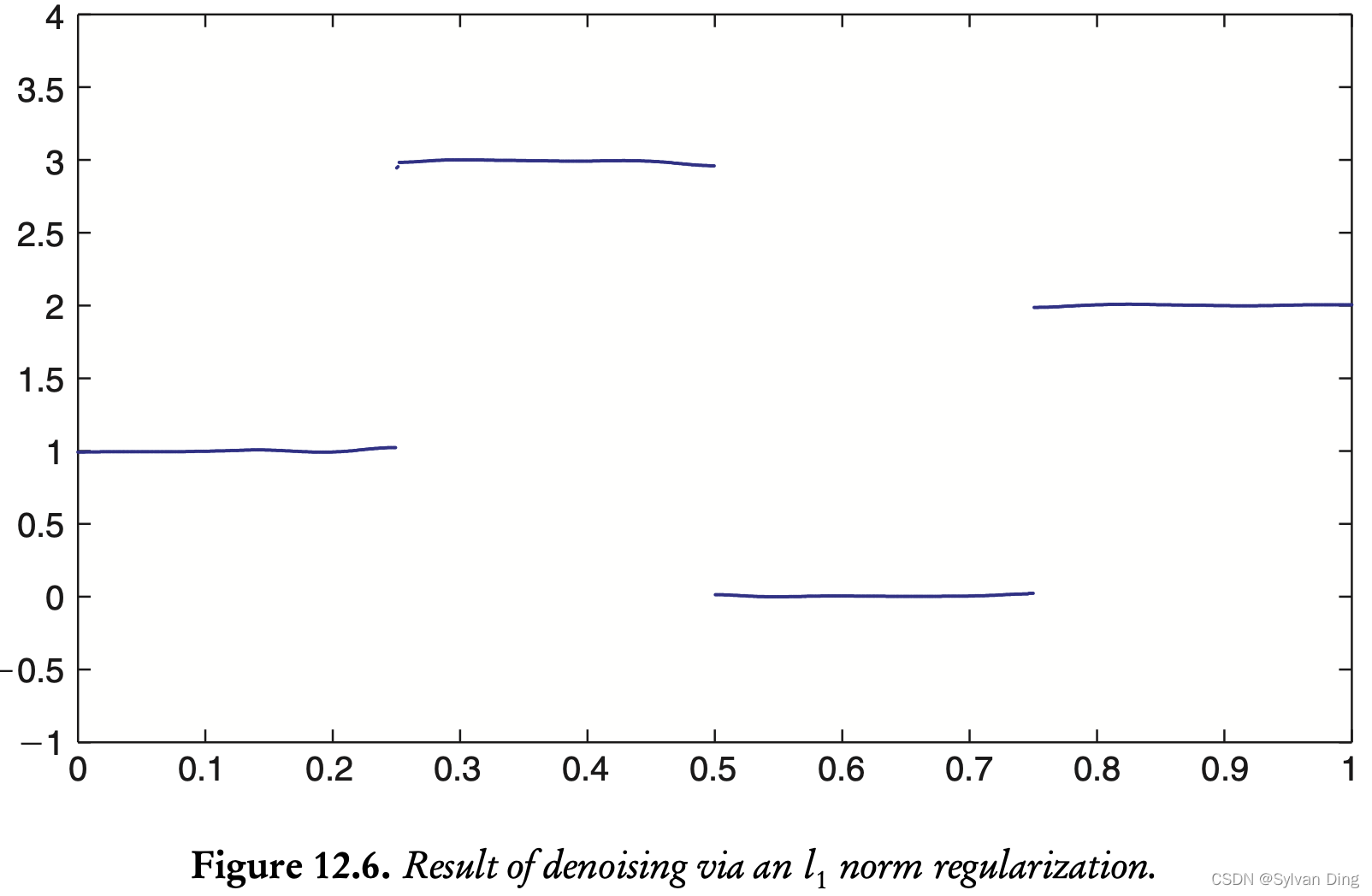
使用 L2 惩罚项时,不能正确处理函数图像的三个间断点。但是,使用 L1 惩罚项时,在间断点处,比任何 λ \lambda λ 时的 L2 惩罚项的表现情况都要好。(This result is much better than any of the quadratic regularization reconstructions, and it captures the breakpoints very well.)
参考文献
- INTRODUCTION TO NONELINEAR OPTIMIZATION. Amir Beck. 2014 : 12.3.10 Denoising
- THE GRADIENT PROJECTION ALGORITHM, https://sites.math.washington.edu/~burke/crs/408/notes/nlp/gpa.pdf
原创文章!转载需注明来源:©️ Sylvan Ding’s Blog ❤️



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









