







文章目录
- 博客说明:
- 基础知识
-
- 001.Hello,World
- 002.CircularStatement
- 003.ConditionalStatement
- 004.range
- 005.lambda
- 006.random
- 007.time
- 008.re
-
-
- raw string 原生字符串
- re.match(pattern, string, flags=0)
- 强化理解一:贪心模式与懒惰模式
- 强化理解二:实例补充
- 视野拓展:查看官方的开发文档
- re.search(pattern, string, flags=0)
- re.sub(pattern, repl, string, count=0, flags=0)
- re.subn(pattern, repl, string, count=0, flags=0)
- re.compile(pattern[, flags])
- re.escape(string)
- findall(pattern, string, flags=0)
- 强化理解之优先级问题
- re.finditer(pattern, string, flags=0)
- re.split(pattern, string[, maxsplit=0, flags=0])
- re模式
- 贪婪模式与惰性匹配
- group(s)
- 常见字符类
- 正则表达的常见应用(模型)
-
- 009.(not) in
- 010.is
- 011.stack
- 012.queue
- 013.列表生成式
- 014.package
- 015.搜索算法
- 016.最短路径
- 017.矩阵
- 018.排序
- 019.查找
- 020.eval
- 021.待定
- 模板代码
- 项目实战
博客说明:
只是一些python语言的基础应用及其技巧,不断更新、记录,并制作对应目录、索引。
目标是1000例,不断更新补全,如有需要可提前说明相关知识点。
基础知识
001.Hello,World
print "Hello,World!"
print "Hi,Python2!"
print ("Hello,World!")
print ("Hi,Python3!")
# python2.7可以输出python3版本,但反过来不行
Python2.7能够正常输出py2、py3
Python3.7无法正常输出py2,版本不兼容
002.CircularStatement
for i in range(10):
print(i,"Hello,For Circular.")
简单for循环之range示范
# 列表单、双引号都可以使用
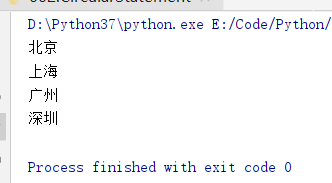
cities = ['北京','上海',"广州","深圳"]
for eachCity in cities:
print (eachCity)
简单for循环之输出列表
# 直接通过迭代器遍历元素
py = "python"
for character in py:
print(character)
print()#默认会输出空行
# 通过列表的索引遍历元素
for i in range(len(py)):
print(i,py[i])
print("\nlen(py)=",len(py))
简单for循环之字符串
# 简单foreach循环,需要Python3
def foreach(function, iterator):
for item in iterator:
function(item)
return
def printItself(it):
print(it,end=" ")
return
# 在这里,试着比较直接使用print与使用printItself的效果
my_tuple = (1, 2, 3, [4, 5], 6)
my_dictionary = {
"Apple": "Red",
"Banana": "Yellow",
"Pear": "Green"
}
foreach(printItself, my_tuple)
# 1 2 3 [4, 5] 6 #注释行为对应的输出结果,下同
print()
foreach(print, my_tuple)
# 1
# 2
# 3
# [4, 5]
# 6
foreach(print, range(len(my_tuple)))
# 0
# 1
# 2
# 3
# 4
print()
foreach(print, my_dictionary)
foreach(print, my_dictionary.keys())
# 上二个语句等价,输出相同
# Apple
# Banana
# Pear
foreach(print, my_dictionary.values())
# Red
# Yellow
# Green
print()
print(my_dictionary)
# {'Apple': 'Red', 'Banana': 'Yellow', 'Pear': 'Green'}
print(my_dictionary.keys())
# dict_keys(['Apple', 'Banana', 'Pear'])
print(my_dictionary.values())
# dict_values(['Red', 'Yellow', 'Green'])
print()
foreach(printItself, range(len(my_dictionary)))
# 0 1 2
print()
foreach(printItself,my_dictionary.keys())
# Apple Banana Pear
print()
foreach(printItself,my_dictionary.values())
# Red Yellow Green
print("\n")
foreach(print,my_dictionary)
print()
foreach(print,my_dictionary.keys())
# 上二个语句等价,输出相同
# Apple
# Banana
# Pear
print()
foreach(print,my_dictionary.values())
# Red
# Yellow
# Green
print()
for item in my_dictionary.items():
print(item)
# ('Apple', 'Red')
# ('Banana', 'Yellow')
# ('Pear', 'Green')
for it in my_dictionary:
print(it,":",my_dictionary[it])
# Apple: Red
# Banana: Yellow
# Pear: Green
# 值得说明的是:dict[key]=value(讲究与之对应),当key值为数值时还可以采用以下途径
for i in range(len(my_dictionary)):
print(i)
# print(my_dictionary[i])#key值不是数值时,找不到对应项会报错
# 0
# 1
# 2
自定义foreach循环之输出元祖
自定义foreach循环之输出字典
003.ConditionalStatement
# -*- coding: UTF-8 -*-
# python 数组用法
# array.array(typecode,[initializer])
# --typecode:元素类型代码;
# initializer:初始化器,若数组为空,则省略初始化器
import array
num = array.array('H',[1]*21)
# print("len(num)=",len(num))
# print(num)
len = len(num)
for i in range(len):
if 0==i or i==1:
num[i] = 0
continue
j = i
while i*j<len:
if(num[j*i]):
num[j*i] = 0
j+=1
# for i in range(len):
# print(i,num[i])
# print(num)
# 以上实现的是一个简单的质数筛法,PrimeNumber
for i in range(len):
if i<2:
print(i,"既不是质数,也不是偶数。")
elif num[i] and i%2:
print(i,"是质数,且是奇质数")
elif num[i] and 0==i%2:
print(i, "是质数,且是偶质数")
elif not(num[i]) and not(i%2):
print(i, "非质数,且是偶数")
else: # not(num[i]) and (i%2)
print(i, "非质数,且是奇数")
条件语句,以及质数筛法
while i*j<len:
statement
该语句完全可以换成另外一种写法(殊途同归)
while True:
statement
if i*j>=len:
break
# 官方文档
https://docs.python.org/2/library/array.html
Python数组类型的说明符
004.range
# range(10)
# [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
# range(5,10)
# [5, 6, 7, 8, 9]
# range(0,10,3)
# [0, 3, 6, 9]
# range(1,10,3)
# [1, 4, 7]
# range(1,10,10)
# [1,]
# range(1,10,-2)
# [1,]
# range(2,-10,-1)
# [2,1,0,-1,-2,-3,-4,-5,-6,-7,-8,-9]
# range(-2,-10,-1)
# [-2,-3,-4,-5,-6,-7,-8,-9]
# range(2,10,-1)、range(-2,10,-1)、range(2,-10,1)
# 以上三个容器都为空
# 语法 range(start, stop[, step])
# range(a,b,c)
# a不写时默认为0,从a开始;生成到b(故通常b>=a);c为步距
# range 默认生成正数方向,若a>b即b<a时将会往左生成负数,步距c也应要改为负数
# 即 不要求start和stop有什么直接的大小关系
# 测试
for i in range(10):
print(i,end=" ")
print()
range(start, stop[, step])
print(sum(range(1,101)))
面试问题:一行代码求和[0,100],并输出结果
005.lambda
lambda
map
filter
reduce
sum
006.random
007.time
008.re
# -*- coding:utf-8 -*-
# re 正则表达式
import re
# raw string 原生字符串
s1 = "abc\nop"
s2 = r"abc\nop"
print("s1=",s1)
print("s2=",s2)# 逗号隔开的输出会默认输出一个空格以分开
print(s2,s2) # 再次验证该空格
raw string 原生字符串
# -*- coding:utf-8 -*-
# re 正则表达式
import re
# patter 正则表达式
# string 待匹配的母字符串
# flags 标志位:是否区分大小写、是否多行匹配
text = 'This is a student,named MY from SJTU University.'
# re.match(pattern, string, flags=0)
# 定死了必须从开头的首元素位置(索引为0)开始匹配
res = re.match('This',text)# 默认flag为0,完全匹配模式(严格大小写、字符配对)
# <re.Match object; span=(0, 4), match='This'>
print(res)
res = re.match('this',text)
# None
print(res)
res = re.match('this',text,re.I)# 置 flags 为 re.I后忽略大小写;爬虫数据清洗通常使用多行匹配且不区分大小写的匹配模式
# <re.Match object; span=(0, 4), match='This'>
print(res)
res = re.match('is',text) # None,re.match()非开头即是匹配得到也不能够配对
print(res)
res = re.match('(.*)is',text)
# "."匹配任意字符(默认为贪婪模式、尽可能多地匹配) + "*"匹配前一个字符0次或多次 = 若存在,则往前取任意多字符直到起始位置(全部取)
# <re.Match object; span=(0, 7), match='This is'>
print(r 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 8970
8970











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![面试问题:一行代码求和[0,100],并输出结果](https://img-blog.csdnimg.cn/20191104221324724.PNG#pic_center){kind=link}
{kind=link}