






先说需求: 当因为某种原因(当两个表有同名项,且横向合并时),数据列出现重名的情况,而且同名列数据还不相同时,需要保留第一个数据列(A,A,保留第一个A列)
方法:
- 出现 重复 两字,第一时间想到就是drop_duplicates()方法,但此处不通,因为同名列的数据不一样。不过可以使用index.duplicated()方法,在借助loc方法删除重复列
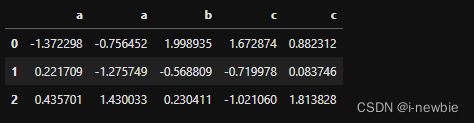
#创建同名列数据框
df=pd.DataFrame(np.random.randn(3,5),columns=list('aabcc'))
df
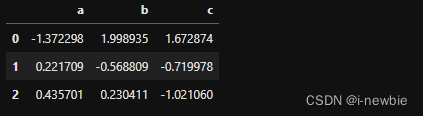
#删除同名列,保留前面一项
df=df.loc[:,~df.columns.duplicated()]
df
- 利用groupby()方法,按列名合并。
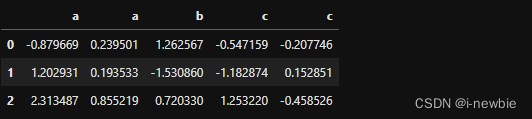
#创建同名列数据框
df=pd.DataFrame(np.random.randn(3,5),columns=list('aabcc'))
df
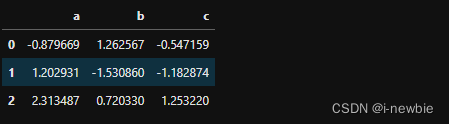
df=df.groupby(level=0,axis=1).first() #后一列就把first变为last即可
df
总结:
一般情况下,以上两种方法都是可行。但是,在某些情况下,第一种方法是最可靠的。如果同名数据列中保留的列有NaN值(A,A,第一个A列数据存在NaN值,而第二个A列数据没有NaN值),执行groupby操作,Nan值会变为第二个A列对应的值,从而使数据化不准确。
如果还有其他方法删除重名列方法,欢迎评论交流















 4535
4535











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









