






目录
2.3 JobLogReportHelper.java 文件修改
3.2 JobLogReportHelper.java 文件修改
3.3.5 XxlJobLogReportMapper.xml
3.3.6 XxlJobRegistryMapper.xml
1.概述
本社畜最近公司研发的产品需要一些定时job相关的功能,最后选定xxl-job,但是最头疼的一点就是所有的产品都需要过信创,那么就意味着要兼容国产数据库,什么人大金仓、达梦、海量、华为高斯gaussDB、优炫、GBase等等,最后本社畜翻了各种数据库官方文档,最后整理出了一版兼容以上数据库的案例,本人已经测试过了,完美运行。整理不易,望诸君高台贵手,点赞支持。
1.1版本
xxl-job:2.4.0
其他数据库没有特别版本,基本上都能适配,除开有些特殊数据库,比如达梦,需要注意跑脚本的客户端,比如用dbeaver跑dm的数据库,就会有兼容问题:如果建表语句中有大字段,创建索引用单独语句就会有问题,等等一些另类的问题;但是使用达梦官方的客户端就不会存在这个问题
2.改动的地方总结
先把改动总结放在前面,省的文章太长不好找,这样一目了然,哪些地方需要修改。
2.1依赖
依赖这个地方看需求,如果你是打包完成之后用fatjar跑的项目,那么可以不用改项目的maven依赖,只需要你的项目支持-Dloader.patch参数指定加载外部依赖jar就行(maven-assembly-plugin的机制,在这里就不多说了),然后将需要的jdbc依赖放进指定的目录下即可,运行的时候会加载到这些jar;如果你需要将这些jdbc的依赖打进你的项目fatjar中,那么就需要修改你的maven依赖,具体如下:
注意:有些jdbc的驱动是maven中央仓库里没有的,就需要用本地依赖systemPath的方式,systemPath具体的配置目录需要根据每个人的实际情况进行修改
<!--pg-->
<dependency>
<groupId>org.postgresql</groupId>
<artifactId>postgresql</artifactId>
<version>42.2.19</version>
</dependency>
<!--高斯的依赖-->
<dependency>
<groupId>gsjdbc</groupId>
<artifactId>huawei.gauss200.jdb</artifactId>
<version>1.0</version>
<scope>system</scope>
<systemPath>${project.basedir}/src/main/resources/lib/gsjdbc200.jar</systemPath>
</dependency>
<!--人大金仓-->
<dependency>
<groupId>kingbase8</groupId>
<artifactId>kingbase8.jdb</artifactId>
<version>1.0</version>
<scope>system</scope>
<systemPath>${project.basedir}/src/main/resources/lib/kingbase8-8.2.0.jar</systemPath>
</dependency>
<!--gbase-->
<dependency>
<groupId>gbase</groupId>
<artifactId>gbase.jdb</artifactId>
<version>1.0</version>
<scope>system</scope>
<systemPath>${project.basedir}/src/main/resources/lib/gbase-connector-java-9.5.0.1-build1-bin.jar</systemPath>
</dependency>
<!--优炫-->
<dependency>
<groupId>uxdb</groupId>
<artifactId>uxdb.jdb</artifactId>
<version>1.0</version>
<scope>system</scope>
<systemPath>${project.basedir}/src/main/resources/lib/uxdb-jdbc-4.2.jar</systemPath>
</dependency>
<!--达梦-->
<dependency>
<groupId>dm</groupId>
<artifactId>dm8.jdb</artifactId>
<version>1.0</version>
<scope>system</scope>
<systemPath>${project.basedir}/src/main/resources/lib/DmJdbcDriver18.jar</systemPath>
</dependency>
<!--sqlserver-->
<!-- https://mvnrepository.com/artifact/com.microsoft.sqlserver/mssql-jdbc -->
<dependency>
<groupId>com.microsoft.sqlserver</groupId>
<artifactId>mssql-jdbc</artifactId>
<version>12.4.1.jre8</version>
</dependency>
<!--oracle-->
<!-- https://mvnrepository.com/artifact/com.oracle.database.jdbc/ojdbc8 -->
<dependency>
<groupId>com.oracle.ojdbc</groupId>
<artifactId>ojdbc8</artifactId>
<version>19.3.0.0</version>
</dependency>2.2各数据库jdbc配置
spring.datasource.url=jdbc:mysql://127.0.0.1:3306/a_xxl_job?useUnicode=true&characterEncoding=UTF-8&autoReconnect=true&serverTimezone=Asia/Shanghai
spring.datasource.username=xxxx
spring.datasource.password=xxxx
spring.datasource.driver-class-name=com.mysql.cj.jdbc.Driver
#spring.datasource.url=jdbc:postgresql://127.0.0.1:5432/xxxx
#spring.datasource.username=xxxx
#spring.datasource.password=xxxx
#spring.datasource.driver-class-name=org.postgresql.Driver
#spring.datasource.url=jdbc:kingbase8://127.0.0.1:54321/xxxx
#spring.datasource.username=xxxx
#spring.datasource.password=xxxx
#spring.datasource.driver-class-name=com.kingbase8.Driver
#spring.datasource.url=jdbc:sqlserver://127.0.0.1:1433;DatabaseName=xxxx;SelectMethod=Cursor;trustServerCertificate=true
#spring.datasource.username=xxxx
#spring.datasource.password=xxxx
#spring.datasource.driver-class-name=com.microsoft.sqlserver.jdbc.SQLServerDriver
#spring.datasource.url=jdbc:gaussdb://127.0.0.1:15400/xxxx
#spring.datasource.username=xxxx
#spring.datasource.password=xxxx
#spring.datasource.driver-class-name=com.huawei.gauss200.jdbc.Driver
#spring.datasource.url=jdbc:dm://localhost:5236
#spring.datasource.username=SYSDBA
#spring.datasource.password=123456789
#spring.datasource.driver-class-name=dm.jdbc.driver.DmDriver
#spring.datasource.url=jdbc:oracle:thin:@127.0.0.1:1521:orcl
#spring.datasource.username=xxxx
#spring.datasource.password=xxxx
#spring.datasource.driver-class-name=oracle.jdbc.driver.OracleDriver2.3 JobLogReportHelper.java 文件修改
这里面需要改以下源码以适配各种数据库的特性:有些数据库大小写敏感、有些是驼峰等等,具体修改内容见下面
2.4 各mapper.xml修改
mapper.xml的改动大概分为几类:
2.4.1 分页的适配
注意:国产数据库大部分都是pg上改的,所以下面没列出来的数据库都可以套用pg
| mysql | oracle | dm | kingbase | pg | sqlserver | |
| limit A | √ | √ | √ | √ | ||
| limit A, B | √ | √ | ||||
| limit B OFFSET A | √ | √ | ||||
| rownum/rownumber | √ | √ | ||||
| top(pagesize) | √ |
2.4.2 AS语法的适配
as语法主要区别在于oracle,oracle不支持表名的as,字段的as是支持的,所有数据库都支持tableName table别名的写法,所以为了通配,把所有mapper.xml里面的as都去掉即可通配
2.4.3 ``的适配
xxl-job里面默认是mysql,所以所有的mapper里面的字段、表名都加上了mysql特有的``,但是其他数据库不支持,有些数据库为了区分关键字用的是" ",有些是[ ],但是都支持不加,前提是字段和表名都没有关键字冲突,正好,xxl-job里面没有这些关键字冲突的顾虑,所以为了通配,把所有的mapper里面的 ` ` 全局扫描替换成空字符串就行
2.4.4 date函数的适配
date函数在xxl中使用都在XxlJobRegisterMapper.xml中:findDead 查询和 findAll 查询
| 数据库 | 支持的函数 |
| MySQL | DATE_ADD() |
| SQL server | DATEADD() |
| kingbase | date ' ' |
| pg | select NOW() |
| oracle | numtodsinterval() |
| dm | numtodsinterval() |
2.4.5 oracle适配修改
主要是oracle的特殊性,比如:insert的时候需要返回主键,但是按照xxl-job的写法显然是不支持的,需要改造以下,然后是save、update需要指定字段的jdbcType,否则会有转换问题等
具体的修改见下面详情
2.5 sql脚本
xxl-job的表主键都是用的自增,所以适配其他数据库的核心问题是解决id自增问题,不支持自增函数的就需要使用序列来实现。
3. 具体解决方案
依赖和jdbc的配置在这里就不列了,参考2.1和2.2即可
3.1 各数据库sql
注意:因为XXL_JOB_GROUP、XXL_JOB_INFO、XXL_JOB_USER三种表会默认插入一条数据,所以对应的自增id序列不能从1开始,为了统一,省的麻烦,就给每个id自增序列都从2起始就行(ps:好像我给有的从10开始了,问题不大,只要不是从1开始就行)。
3.1.1 Oracle
CREATE SEQUENCE XXL_JOB_INFO_SEQ_ID
START WITH 2
INCREMENT BY 1
NOMAXVALUE;
CREATE TABLE XXL_JOB_INFO (
ID NUMBER(10,0) DEFAULT XXL_JOB_INFO_SEQ_ID.NEXTVAL,
JOB_GROUP NUMBER(10,0) NOT NULL,
JOB_DESC VARCHAR2(255 CHAR) NOT NULL,
ADD_TIME DATE DEFAULT NULL,
UPDATE_TIME DATE DEFAULT NULL,
AUTHOR VARCHAR2(64 CHAR) DEFAULT NULL,
ALARM_EMAIL VARCHAR2(255 CHAR) DEFAULT NULL,
SCHEDULE_TYPE VARCHAR2(50 CHAR) DEFAULT 'NONE',
SCHEDULE_CONF VARCHAR2(128 CHAR) DEFAULT NULL,
MISFIRE_STRATEGY VARCHAR2(50 CHAR) DEFAULT 'DO_NOTHING',
EXECUTOR_ROUTE_STRATEGY VARCHAR2(50 CHAR) DEFAULT NULL,
EXECUTOR_HANDLER VARCHAR2(255 CHAR) DEFAULT NULL,
EXECUTOR_PARAM VARCHAR2(512 CHAR) DEFAULT NULL,
EXECUTOR_BLOCK_STRATEGY VARCHAR2(50 CHAR) DEFAULT NULL,
EXECUTOR_TIMEOUT NUMBER(10,0) DEFAULT '0',
EXECUTOR_FAIL_RETRY_COUNT NUMBER(10,0) DEFAULT '0',
GLUE_TYPE VARCHAR2(50 CHAR) NOT NULL,
GLUE_SOURCE CLOB,
GLUE_REMARK VARCHAR2(128 CHAR) DEFAULT NULL,
GLUE_UPDATETIME DATE DEFAULT NULL,
CHILD_JOBID VARCHAR2(255 CHAR) DEFAULT NULL,
TRIGGER_STATUS NUMBER(10,0) DEFAULT 0,
TRIGGER_LAST_TIME NUMBER(38,0) DEFAULT 0,
TRIGGER_NEXT_TIME NUMBER(38,0) DEFAULT 0,
PRIMARY KEY (ID)
) ;
COMMENT ON COLUMN XXL_JOB_INFO.JOB_GROUP IS '执行器主键ID';
COMMENT ON COLUMN XXL_JOB_INFO.AUTHOR IS '作者';
COMMENT ON COLUMN XXL_JOB_INFO.ALARM_EMAIL IS '报警邮件';
COMMENT ON COLUMN XXL_JOB_INFO.SCHEDULE_TYPE IS '调度类型';
COMMENT ON COLUMN XXL_JOB_INFO.SCHEDULE_CONF IS '调度配置,值含义取决于调度类型';
COMMENT ON COLUMN XXL_JOB_INFO.MISFIRE_STRATEGY IS '调度过期策略';
COMMENT ON COLUMN XXL_JOB_INFO.EXECUTOR_ROUTE_STRATEGY IS '执行器路由策略';
COMMENT ON COLUMN XXL_JOB_INFO.EXECUTOR_HANDLER IS '执行器任务handler';
COMMENT ON COLUMN XXL_JOB_INFO.EXECUTOR_PARAM IS '执行器任务参数';
COMMENT ON COLUMN XXL_JOB_INFO.EXECUTOR_BLOCK_STRATEGY IS '阻塞处理策略';
COMMENT ON COLUMN XXL_JOB_INFO.EXECUTOR_TIMEOUT IS '任务执行超时时间,单位秒';
COMMENT ON COLUMN XXL_JOB_INFO.EXECUTOR_FAIL_RETRY_COUNT IS '失败重试次数';
COMMENT ON COLUMN XXL_JOB_INFO.GLUE_TYPE IS 'GLUE类型';
COMMENT ON COLUMN XXL_JOB_INFO.GLUE_SOURCE IS 'GLUE源代码';
COMMENT ON COLUMN XXL_JOB_INFO.GLUE_REMARK IS 'GLUE备注';
COMMENT ON COLUMN XXL_JOB_INFO.GLUE_UPDATETIME IS 'GLUE更新时间';
COMMENT ON COLUMN XXL_JOB_INFO.CHILD_JOBID IS '子任务ID,多个逗号分隔';
COMMENT ON COLUMN XXL_JOB_INFO.TRIGGER_STATUS IS '调度状态:0-停止,1-运行';
COMMENT ON COLUMN XXL_JOB_INFO.TRIGGER_LAST_TIME IS '上次调度时间';
COMMENT ON COLUMN XXL_JOB_INFO.TRIGGER_NEXT_TIME IS '下次调度时间';
-- ----------------------------
-- Table structure for XXL_JOB_LOG
-- ----------------------------
CREATE SEQUENCE XXL_JOB_LOG_SEQ_ID
START WITH 2
INCREMENT BY 1
NOMAXVALUE;
CREATE TABLE XXL_JOB_LOG (
ID NUMBER(38,0) DEFAULT XXL_JOB_LOG_SEQ_ID.NEXTVAL,
JOB_GROUP NUMBER(10,0) NOT NULL,
JOB_ID NUMBER(10,0) NOT NULL,
EXECUTOR_ADDRESS VARCHAR2(255 CHAR) DEFAULT NULL,
EXECUTOR_HANDLER VARCHAR2(255 CHAR) DEFAULT NULL,
EXECUTOR_PARAM VARCHAR2(512 CHAR) DEFAULT NULL,
EXECUTOR_SHARDING_PARAM VARCHAR2(20 CHAR) DEFAULT NULL,
EXECUTOR_FAIL_RETRY_COUNT NUMBER(10,0) DEFAULT 0,
TRIGGER_TIME DATE DEFAULT NULL,
TRIGGER_CODE NUMBER(10,0) NOT NULL,
TRIGGER_MSG CLOB,
HANDLE_TIME DATE DEFAULT NULL,
HANDLE_CODE NUMBER(10,0) NOT NULL,
HANDLE_MSG CLOB,
ALARM_STATUS NUMBER(10,0) DEFAULT 0,
PRIMARY KEY (ID)
) ;
CREATE INDEX I_TRIGGER_TIME ON XXL_JOB_LOG (TRIGGER_TIME ASC);
CREATE INDEX I_HANDLE_CODE ON XXL_JOB_LOG (HANDLE_CODE ASC);
COMMENT ON COLUMN XXL_JOB_LOG.JOB_GROUP IS '执行器主键ID';
COMMENT ON COLUMN XXL_JOB_LOG.JOB_ID IS '任务,主键ID';
COMMENT ON COLUMN XXL_JOB_LOG.EXECUTOR_ADDRESS IS '执行器地址,本次执行的地址';
COMMENT ON COLUMN XXL_JOB_LOG.EXECUTOR_HANDLER IS '执行器任务handler';
COMMENT ON COLUMN XXL_JOB_LOG.EXECUTOR_PARAM IS '执行器任务参数';
COMMENT ON COLUMN XXL_JOB_LOG.EXECUTOR_SHARDING_PARAM IS '执行器任务分片参数,格式如 1/2';
COMMENT ON COLUMN XXL_JOB_LOG.EXECUTOR_FAIL_RETRY_COUNT IS '失败重试次数';
COMMENT ON COLUMN XXL_JOB_LOG.TRIGGER_TIME IS '调度-时间';
COMMENT ON COLUMN XXL_JOB_LOG.TRIGGER_CODE IS '调度-结果';
COMMENT ON COLUMN XXL_JOB_LOG.TRIGGER_MSG IS '调度-日志';
COMMENT ON COLUMN XXL_JOB_LOG.HANDLE_TIME IS '执行-时间';
COMMENT ON COLUMN XXL_JOB_LOG.HANDLE_CODE IS '执行-状态';
COMMENT ON COLUMN XXL_JOB_LOG.HANDLE_MSG IS '执行-日志';
COMMENT ON COLUMN XXL_JOB_LOG.ALARM_STATUS IS '告警状态:0-默认、1-无需告警、2-告警成功、3-告警失败';
-- ----------------------------
-- Table structure for XXL_JOB_LOG_REPORT
-- ----------------------------
CREATE SEQUENCE XXL_JOB_LOG_REPORT_SEQ_ID
START WITH 2
INCREMENT BY 1
NOMAXVALUE;
CREATE TABLE XXL_JOB_LOG_REPORT (
ID NUMBER(10,0) DEFAULT XXL_JOB_LOG_REPORT_SEQ_ID.NEXTVAL,
TRIGGER_DAY DATE DEFAULT NULL,
RUNNING_COUNT NUMBER(10,0) DEFAULT 0,
SUC_COUNT NUMBER(10,0) DEFAULT 0,
FAIL_COUNT NUMBER(10,0) DEFAULT 0,
UPDATE_TIME DATE DEFAULT NULL,
PRIMARY KEY (ID)
);
CREATE UNIQUE INDEX I_TRIGGER_DAY ON XXL_JOB_LOG_REPORT (TRIGGER_DAY ASC);
COMMENT ON COLUMN XXL_JOB_LOG_REPORT.TRIGGER_DAY IS '调度-时间';
COMMENT ON COLUMN XXL_JOB_LOG_REPORT.RUNNING_COUNT IS '运行中-日志数量';
COMMENT ON COLUMN XXL_JOB_LOG_REPORT.SUC_COUNT IS '执行成功-日志数量';
COMMENT ON COLUMN XXL_JOB_LOG_REPORT.FAIL_COUNT IS '执行失败-日志数量';
-- ----------------------------
-- Table structure for XXL_JOB_LOGGLUE
-- ----------------------------
CREATE SEQUENCE XXL_JOB_LOGGLUE_SEQ_ID
START WITH 2
INCREMENT BY 1
NOMAXVALUE;
CREATE TABLE XXL_JOB_LOGGLUE (
ID NUMBER(10,0) DEFAULT XXL_JOB_LOGGLUE_SEQ_ID.NEXTVAL,
JOB_ID NUMBER(10,0) NOT NULL,
GLUE_TYPE VARCHAR2(50 CHAR) DEFAULT NULL,
GLUE_SOURCE CLOB,
GLUE_REMARK VARCHAR2(128 CHAR) NOT NULL,
ADD_TIME DATE DEFAULT NULL,
UPDATE_TIME DATE DEFAULT NULL,
PRIMARY KEY (ID)
) ;
COMMENT ON COLUMN XXL_JOB_LOGGLUE.JOB_ID IS '任务,主键ID';
COMMENT ON COLUMN XXL_JOB_LOGGLUE.GLUE_TYPE IS 'GLUE类型';
COMMENT ON COLUMN XXL_JOB_LOGGLUE.GLUE_SOURCE IS 'GLUE源代码';
COMMENT ON COLUMN XXL_JOB_LOGGLUE.GLUE_REMARK IS 'GLUE备注';
-- ----------------------------
-- Table structure for XXL_JOB_REGISTRY
-- ----------------------------
CREATE SEQUENCE XXL_JOB_REGISTRY_SEQ_ID
START WITH 2
INCREMENT BY 1
NOMAXVALUE;
CREATE TABLE XXL_JOB_REGISTRY (
ID NUMBER(10,0) DEFAULT XXL_JOB_REGISTRY_SEQ_ID.NEXTVAL,
REGISTRY_GROUP VARCHAR2(50 CHAR) NOT NULL,
REGISTRY_KEY VARCHAR2(255 CHAR) NOT NULL,
REGISTRY_VALUE VARCHAR2(255 CHAR) NOT NULL,
UPDATE_TIME DATE DEFAULT NULL,
PRIMARY KEY (ID)
) ;
CREATE INDEX I_G_K_V ON XXL_JOB_REGISTRY (REGISTRY_GROUP,REGISTRY_KEY,REGISTRY_VALUE ASC);
-- ----------------------------
-- Table structure for XXL_JOB_GROUP
-- ----------------------------
CREATE SEQUENCE XXL_JOB_GROUP_SEQ_ID
START WITH 2
INCREMENT BY 1
NOMAXVALUE;
CREATE TABLE XXL_JOB_GROUP (
ID NUMBER(10,0) DEFAULT XXL_JOB_GROUP_SEQ_ID.NEXTVAL,
APP_NAME VARCHAR2(64 CHAR) NOT NULL,
TITLE VARCHAR2(64 CHAR) NOT NULL,
ADDRESS_TYPE NUMBER(10,0) DEFAULT 0,
ADDRESS_LIST VARCHAR2(512 CHAR),
UPDATE_TIME DATE DEFAULT NULL,
PRIMARY KEY (ID)
) ;
COMMENT ON COLUMN XXL_JOB_GROUP.APP_NAME IS '执行器AppName';
COMMENT ON COLUMN XXL_JOB_GROUP.TITLE IS '执行器名称';
COMMENT ON COLUMN XXL_JOB_GROUP.ADDRESS_TYPE IS '执行器地址类型:0=自动注册、1=手动录入';
COMMENT ON COLUMN XXL_JOB_GROUP.ADDRESS_LIST IS '执行器地址列表,多地址逗号分隔';
-- ----------------------------
-- Table structure for XXL_JOB_USER
-- ----------------------------
CREATE SEQUENCE XXL_JOB_USER_SEQ_ID
START WITH 2
INCREMENT BY 1
NOMAXVALUE;
CREATE TABLE XXL_JOB_USER (
ID NUMBER(10,0) DEFAULT XXL_JOB_USER_SEQ_ID.NEXTVAL,
USERNAME VARCHAR2(50 CHAR) NOT NULL ,
PASSWORD VARCHAR2(50 CHAR) NOT NULL ,
ROLE NUMBER(10,0) NOT NULL ,
PERMISSION VARCHAR2(255 CHAR) DEFAULT NULL,
PRIMARY KEY (ID)
) ;
CREATE UNIQUE INDEX I_USERNAME ON XXL_JOB_USER (USERNAME ASC);
COMMENT ON COLUMN XXL_JOB_USER.USERNAME IS '账号';
COMMENT ON COLUMN XXL_JOB_USER.PASSWORD IS '密码';
COMMENT ON COLUMN XXL_JOB_USER.ROLE IS '角色:0-普通用户、1-管理员';
COMMENT ON COLUMN XXL_JOB_USER.PERMISSION IS '权限:执行器ID列表,多个逗号分割';
-- ----------------------------
-- Table structure for XXL_JOB_LOCK
-- ----------------------------
CREATE TABLE XXL_JOB_LOCK (
LOCK_NAME VARCHAR2(50 CHAR) NOT NULL,
PRIMARY KEY (LOCK_NAME)
) ;
-- 2023-12-27 适配xxl-job
INSERT INTO "XXL_JOB_GROUP"("ID", "APP_NAME", "TITLE", "ADDRESS_TYPE", "ADDRESS_LIST", "UPDATE_TIME") VALUES (1, 'xxl-job-executor-sample', '示例执行器', 0, NULL, TO_DATE('2018-11-03 22:21:31','yyyy-mm-dd hh24:mi:ss'));
INSERT INTO "XXL_JOB_INFO"("ID", "JOB_GROUP", "JOB_DESC", "ADD_TIME", "UPDATE_TIME", "AUTHOR", "ALARM_EMAIL", "SCHEDULE_TYPE", "SCHEDULE_CONF", "MISFIRE_STRATEGY", "EXECUTOR_ROUTE_STRATEGY", "EXECUTOR_HANDLER", "EXECUTOR_PARAM", "EXECUTOR_BLOCK_STRATEGY", "EXECUTOR_TIMEOUT", "EXECUTOR_FAIL_RETRY_COUNT", "GLUE_TYPE", "GLUE_SOURCE", "GLUE_REMARK", "GLUE_UPDATETIME", "CHILD_JOBID") VALUES (1, 1, '测试任务1', TO_DATE('2018-11-03 22:21:31','yyyy-mm-dd hh24:mi:ss'), TO_DATE('2018-11-03 22:21:31','yyyy-mm-dd hh24:mi:ss'), 'XXL', '', 'CRON', '0 0 0 * * ? *', 'DO_NOTHING', 'FIRST', 'demoJobHandler', '', 'SERIAL_EXECUTION', 0, 0, 'BEAN', '', 'GLUE代码初始化', TO_DATE('2018-11-03 22:21:31','yyyy-mm-dd hh24:mi:ss'), '');
INSERT INTO "XXL_JOB_USER"("ID", "USERNAME", "PASSWORD", "ROLE", "PERMISSION") VALUES (1, 'admin', 'e10adc3949ba59abbe56e057f20f883e', 1, NULL);
INSERT INTO "XXL_JOB_LOCK"("LOCK_NAME") VALUES ('schedule_lock');
3.1.2 达梦dm
CREATE SEQUENCE XXL_JOB_INFO_SEQ_ID
INCREMENT BY 1 --每次+1
START WITH 10 --从1开始
nomaxvalue --不限最大值
nominvalue --不限最小值
cache 20; --设置取值缓存数为20
DROP TABLE IF EXISTS XXL_JOB_INFO;
CREATE TABLE "XXL_JOB_INFO" (
"ID" NUMBER(10,0) DEFAULT XXL_JOB_INFO_SEQ_ID.NEXTVAL,
"JOB_GROUP" NUMBER(10,0) NOT NULL,
"JOB_DESC" VARCHAR2(255 CHAR) NOT NULL,
"ADD_TIME" TIMESTAMP DEFAULT NULL,
"UPDATE_TIME" TIMESTAMP DEFAULT NULL,
"AUTHOR" VARCHAR2(64 CHAR) DEFAULT NULL,
"ALARM_EMAIL" VARCHAR2(255 CHAR) DEFAULT NULL,
"SCHEDULE_TYPE" VARCHAR2(50 CHAR) DEFAULT 'NONE',
"SCHEDULE_CONF" VARCHAR2(128 CHAR) DEFAULT NULL,
"MISFIRE_STRATEGY" VARCHAR2(50 CHAR) DEFAULT 'DO_NOTHING',
"EXECUTOR_ROUTE_STRATEGY" VARCHAR2(50 CHAR) DEFAULT NULL,
"EXECUTOR_HANDLER" VARCHAR2(255 CHAR) DEFAULT NULL,
"EXECUTOR_PARAM" VARCHAR2(512 CHAR) DEFAULT NULL,
"EXECUTOR_BLOCK_STRATEGY" VARCHAR2(50 CHAR) DEFAULT NULL,
"EXECUTOR_TIMEOUT" NUMBER(10,0) DEFAULT '0',
"EXECUTOR_FAIL_RETRY_COUNT" NUMBER(10,0) DEFAULT '0',
"GLUE_TYPE" VARCHAR2(50 CHAR) NOT NULL,
"GLUE_SOURCE" CLOB,
"GLUE_REMARK" VARCHAR2(128 CHAR) DEFAULT NULL,
"GLUE_UPDATETIME" TIMESTAMP DEFAULT NULL,
"CHILD_JOBID" VARCHAR2(255 CHAR) DEFAULT NULL,
"TRIGGER_STATUS" NUMBER(10,0) DEFAULT 0,
"TRIGGER_LAST_TIME" NUMBER(38,0) DEFAULT 0,
"TRIGGER_NEXT_TIME" NUMBER(38,0) DEFAULT 0,
PRIMARY KEY (ID)
) ;
COMMENT ON COLUMN "XXL_JOB_INFO"."JOB_GROUP" IS '执行器主键ID';
COMMENT ON COLUMN "XXL_JOB_INFO"."AUTHOR" IS '作者';
COMMENT ON COLUMN "XXL_JOB_INFO"."ALARM_EMAIL" IS '报警邮件';
COMMENT ON COLUMN "XXL_JOB_INFO"."SCHEDULE_TYPE" IS '调度类型';
COMMENT ON COLUMN "XXL_JOB_INFO"."SCHEDULE_CONF" IS '调度配置,值含义取决于调度类型';
COMMENT ON COLUMN "XXL_JOB_INFO"."MISFIRE_STRATEGY" IS '调度过期策略';
COMMENT ON COLUMN "XXL_JOB_INFO"."EXECUTOR_ROUTE_STRATEGY" IS '执行器路由策略';
COMMENT ON COLUMN "XXL_JOB_INFO"."EXECUTOR_HANDLER" IS '执行器任务handler';
COMMENT ON COLUMN "XXL_JOB_INFO"."EXECUTOR_PARAM" IS '执行器任务参数';
COMMENT ON COLUMN "XXL_JOB_INFO"."EXECUTOR_BLOCK_STRATEGY" IS '阻塞处理策略';
COMMENT ON COLUMN "XXL_JOB_INFO"."EXECUTOR_TIMEOUT" IS '任务执行超时时间,单位秒';
COMMENT ON COLUMN "XXL_JOB_INFO"."EXECUTOR_FAIL_RETRY_COUNT" IS '失败重试次数';
COMMENT ON COLUMN "XXL_JOB_INFO"."GLUE_TYPE" IS 'GLUE类型';
COMMENT ON COLUMN "XXL_JOB_INFO"."GLUE_SOURCE" IS 'GLUE源代码';
COMMENT ON COLUMN "XXL_JOB_INFO"."GLUE_REMARK" IS 'GLUE备注';
COMMENT ON COLUMN "XXL_JOB_INFO"."GLUE_UPDATETIME" IS 'GLUE更新时间';
COMMENT ON COLUMN "XXL_JOB_INFO"."CHILD_JOBID" IS '子任务ID,多个逗号分隔';
COMMENT ON COLUMN "XXL_JOB_INFO"."TRIGGER_STATUS" IS '调度状态:0-停止,1-运行';
COMMENT ON COLUMN "XXL_JOB_INFO"."TRIGGER_LAST_TIME" IS '上次调度时间';
COMMENT ON COLUMN "XXL_JOB_INFO"."TRIGGER_NEXT_TIME" IS '下次调度时间';
-- ----------------------------
-- Table structure for XXL_JOB_LOG
-- ----------------------------
CREATE SEQUENCE XXL_JOB_LOG_SEQ_ID
INCREMENT BY 1 --每次+1
START WITH 10 --从1开始
nomaxvalue --不限最大值
nominvalue --不限最小值
cache 20; --设置取值缓存数为20
DROP TABLE IF EXISTS XXL_JOB_LOG;
CREATE TABLE "XXL_JOB_LOG" (
"ID" NUMBER(38,0) DEFAULT XXL_JOB_LOG_SEQ_ID.NEXTVAL,
"JOB_GROUP" NUMBER(10,0) NOT NULL,
"JOB_ID" NUMBER(10,0) NOT NULL,
"EXECUTOR_ADDRESS" VARCHAR2(255 CHAR) DEFAULT NULL,
"EXECUTOR_HANDLER" VARCHAR2(255 CHAR) DEFAULT NULL,
"EXECUTOR_PARAM" VARCHAR2(512 CHAR) DEFAULT NULL,
"EXECUTOR_SHARDING_PARAM" VARCHAR2(20 CHAR) DEFAULT NULL,
"EXECUTOR_FAIL_RETRY_COUNT" NUMBER(10,0) DEFAULT 0,
"TRIGGER_TIME" TIMESTAMP DEFAULT NULL,
"TRIGGER_CODE" NUMBER(10,0) NOT NULL,
"TRIGGER_MSG" CLOB,
"HANDLE_TIME" TIMESTAMP DEFAULT NULL,
"HANDLE_CODE" NUMBER(10,0) NOT NULL,
"HANDLE_MSG" CLOB,
"ALARM_STATUS" NUMBER(10,0) DEFAULT 0,
PRIMARY KEY (ID)
) ;
CREATE INDEX "I_TRIGGER_TIME" ON "XXL_JOB_LOG" ("TRIGGER_TIME" ASC);
CREATE INDEX "I_HANDLE_CODE" ON "XXL_JOB_LOG" ("HANDLE_CODE" ASC);
COMMENT ON COLUMN "XXL_JOB_LOG"."JOB_GROUP" IS '执行器主键ID';
COMMENT ON COLUMN "XXL_JOB_LOG"."JOB_ID" IS '任务,主键ID';
COMMENT ON COLUMN "XXL_JOB_LOG"."EXECUTOR_ADDRESS" IS '执行器地址,本次执行的地址';
COMMENT ON COLUMN "XXL_JOB_LOG"."EXECUTOR_HANDLER" IS '执行器任务handler';
COMMENT ON COLUMN "XXL_JOB_LOG"."EXECUTOR_PARAM" IS '执行器任务参数';
COMMENT ON COLUMN "XXL_JOB_LOG"."EXECUTOR_SHARDING_PARAM" IS '执行器任务分片参数,格式如 1/2';
COMMENT ON COLUMN "XXL_JOB_LOG"."EXECUTOR_FAIL_RETRY_COUNT" IS '失败重试次数';
COMMENT ON COLUMN "XXL_JOB_LOG"."TRIGGER_TIME" IS '调度-时间';
COMMENT ON COLUMN "XXL_JOB_LOG"."TRIGGER_CODE" IS '调度-结果';
COMMENT ON COLUMN "XXL_JOB_LOG"."TRIGGER_MSG" IS '调度-日志';
COMMENT ON COLUMN "XXL_JOB_LOG"."HANDLE_TIME" IS '执行-时间';
COMMENT ON COLUMN "XXL_JOB_LOG"."HANDLE_CODE" IS '执行-状态';
COMMENT ON COLUMN "XXL_JOB_LOG"."HANDLE_MSG" IS '执行-日志';
COMMENT ON COLUMN "XXL_JOB_LOG"."ALARM_STATUS" IS '告警状态:0-默认、1-无需告警、2-告警成功、3-告警失败';
-- ----------------------------
-- Table structure for XXL_JOB_LOG_REPORT
-- ----------------------------
CREATE SEQUENCE XXL_JOB_LOG_REPORT_SEQ_ID
INCREMENT BY 1 --每次+1
START WITH 10 --从1开始
nomaxvalue --不限最大值
nominvalue --不限最小值
cache 20; --设置取值缓存数为20
DROP TABLE IF EXISTS XXL_JOB_LOG_REPORT;
CREATE TABLE "XXL_JOB_LOG_REPORT" (
"ID" NUMBER(10,0) DEFAULT XXL_JOB_LOG_REPORT_SEQ_ID.NEXTVAL,
"TRIGGER_DAY" TIMESTAMP DEFAULT NULL,
"RUNNING_COUNT" NUMBER(10,0) DEFAULT 0,
"SUC_COUNT" NUMBER(10,0) DEFAULT 0,
"FAIL_COUNT" NUMBER(10,0) DEFAULT 0,
"UPDATE_TIME" TIMESTAMP DEFAULT NULL,
PRIMARY KEY (ID)
);
CREATE UNIQUE INDEX "I_TRIGGER_DAY" ON "XXL_JOB_LOG_REPORT" ("TRIGGER_DAY" ASC);
COMMENT ON COLUMN "XXL_JOB_LOG_REPORT"."TRIGGER_DAY" IS '调度-时间';
COMMENT ON COLUMN "XXL_JOB_LOG_REPORT"."RUNNING_COUNT" IS '运行中-日志数量';
COMMENT ON COLUMN "XXL_JOB_LOG_REPORT"."SUC_COUNT" IS '执行成功-日志数量';
COMMENT ON COLUMN "XXL_JOB_LOG_REPORT"."FAIL_COUNT" IS '执行失败-日志数量';
-- ----------------------------
-- Table structure for XXL_JOB_LOGGLUE
-- ----------------------------
CREATE SEQUENCE XXL_JOB_LOGGLUE_SEQ_ID
INCREMENT BY 1 --每次+1
START WITH 10 --从1开始
nomaxvalue --不限最大值
nominvalue --不限最小值
cache 20; --设置取值缓存数为20
DROP TABLE IF EXISTS XXL_JOB_LOGGLUE;
CREATE TABLE "XXL_JOB_LOGGLUE" (
"ID" NUMBER(10,0) DEFAULT XXL_JOB_LOGGLUE_SEQ_ID.NEXTVAL,
"JOB_ID" NUMBER(10,0) NOT NULL,
"GLUE_TYPE" VARCHAR2(50 CHAR) DEFAULT NULL,
"GLUE_SOURCE" CLOB,
"GLUE_REMARK" VARCHAR2(128 CHAR) NOT NULL,
"ADD_TIME" TIMESTAMP DEFAULT NULL,
"UPDATE_TIME" TIMESTAMP DEFAULT NULL,
PRIMARY KEY (ID)
) ;
COMMENT ON COLUMN "XXL_JOB_LOGGLUE"."JOB_ID" IS '任务,主键ID';
COMMENT ON COLUMN "XXL_JOB_LOGGLUE"."GLUE_TYPE" IS 'GLUE类型';
COMMENT ON COLUMN "XXL_JOB_LOGGLUE"."GLUE_SOURCE" IS 'GLUE源代码';
COMMENT ON COLUMN "XXL_JOB_LOGGLUE"."GLUE_REMARK" IS 'GLUE备注';
-- ----------------------------
-- Table structure for XXL_JOB_REGISTRY
-- ----------------------------
CREATE SEQUENCE XXL_JOB_REGISTRY_SEQ_ID
INCREMENT BY 1 --每次+1
START WITH 10 --从1开始
nomaxvalue --不限最大值
nominvalue --不限最小值
cache 20; --设置取值缓存数为20
DROP TABLE IF EXISTS XXL_JOB_REGISTRY;
CREATE TABLE "XXL_JOB_REGISTRY" (
"ID" NUMBER(10,0) DEFAULT XXL_JOB_REGISTRY_SEQ_ID.NEXTVAL,
"REGISTRY_GROUP" VARCHAR2(50 CHAR) NOT NULL,
"REGISTRY_KEY" VARCHAR2(255 CHAR) NOT NULL,
"REGISTRY_VALUE" VARCHAR2(255 CHAR) NOT NULL,
"UPDATE_TIME" TIMESTAMP DEFAULT NULL,
PRIMARY KEY (ID)
) ;
CREATE INDEX "I_G_K_V" ON "XXL_JOB_REGISTRY" ("REGISTRY_GROUP","REGISTRY_KEY","REGISTRY_VALUE" ASC);
-- ----------------------------
-- Table structure for XXL_JOB_GROUP
-- ----------------------------
CREATE SEQUENCE XXL_JOB_GROUP_SEQ_ID
INCREMENT BY 1 --每次+1
START WITH 10 --从1开始
nomaxvalue --不限最大值
nominvalue --不限最小值
cache 20; --设置取值缓存数为20
DROP TABLE IF EXISTS XXL_JOB_GROUP;
CREATE TABLE "XXL_JOB_GROUP" (
"ID" NUMBER(10,0) DEFAULT XXL_JOB_GROUP_SEQ_ID.NEXTVAL,
"APP_NAME" VARCHAR2(64 CHAR) NOT NULL,
"TITLE" VARCHAR2(64 CHAR) NOT NULL,
"ADDRESS_TYPE" NUMBER(10,0) DEFAULT 0,
"ADDRESS_LIST" VARCHAR2(512 CHAR),
"UPDATE_TIME" TIMESTAMP DEFAULT NULL,
PRIMARY KEY (ID)
) ;
COMMENT ON COLUMN "XXL_JOB_GROUP"."APP_NAME" IS '执行器AppName';
COMMENT ON COLUMN "XXL_JOB_GROUP"."TITLE" IS '执行器名称';
COMMENT ON COLUMN "XXL_JOB_GROUP"."ADDRESS_TYPE" IS '执行器地址类型:0=自动注册、1=手动录入';
COMMENT ON COLUMN "XXL_JOB_GROUP"."ADDRESS_LIST" IS '执行器地址列表,多地址逗号分隔';
-- ----------------------------
-- Table structure for XXL_JOB_USER
-- ----------------------------
CREATE SEQUENCE XXL_JOB_USER_SEQ_ID
INCREMENT BY 1 --每次+1
START WITH 10 --从1开始
nomaxvalue --不限最大值
nominvalue --不限最小值
cache 20; --设置取值缓存数为20
DROP TABLE IF EXISTS XXL_JOB_USER;
CREATE TABLE "XXL_JOB_USER" (
"ID" NUMBER(10,0) DEFAULT XXL_JOB_USER_SEQ_ID.NEXTVAL,
"USERNAME" VARCHAR2(50 CHAR) NOT NULL ,
"PASSWORD" VARCHAR2(50 CHAR) NOT NULL ,
"ROLE" NUMBER(10,0) NOT NULL ,
"PERMISSION" VARCHAR2(255 CHAR) DEFAULT NULL,
PRIMARY KEY (ID)
) ;
CREATE UNIQUE INDEX "I_USERNAME" ON "XXL_JOB_USER" ("USERNAME" ASC);
COMMENT ON COLUMN "XXL_JOB_USER"."USERNAME" IS '账号';
COMMENT ON COLUMN "XXL_JOB_USER"."PASSWORD" IS '密码';
COMMENT ON COLUMN "XXL_JOB_USER"."ROLE" IS '角色:0-普通用户、1-管理员';
COMMENT ON COLUMN "XXL_JOB_USER"."PERMISSION" IS '权限:执行器ID列表,多个逗号分割';
-- ----------------------------
-- Table structure for XXL_JOB_LOCK
-- ----------------------------
DROP TABLE IF EXISTS XXL_JOB_LOCK;
CREATE TABLE "XXL_JOB_LOCK" (
"LOCK_NAME" VARCHAR2(50 CHAR) NOT NULL,
PRIMARY KEY ("LOCK_NAME")
) ;
-- 2023-12-27 增加对xxl-job支持
INSERT INTO "XXL_JOB_GROUP"("ID", "APP_NAME", "TITLE", "ADDRESS_TYPE", "ADDRESS_LIST", "UPDATE_TIME") VALUES (1, 'xxl-job-executor-sample', '示例执行器', 0, NULL, TO_DATE('2018-11-03 22:21:31','yyyy-mm-dd hh24:mi:ss'));
INSERT INTO "XXL_JOB_INFO"("ID", "JOB_GROUP", "JOB_DESC", "ADD_TIME", "UPDATE_TIME", "AUTHOR", "ALARM_EMAIL", "SCHEDULE_TYPE", "SCHEDULE_CONF", "MISFIRE_STRATEGY", "EXECUTOR_ROUTE_STRATEGY", "EXECUTOR_HANDLER", "EXECUTOR_PARAM", "EXECUTOR_BLOCK_STRATEGY", "EXECUTOR_TIMEOUT", "EXECUTOR_FAIL_RETRY_COUNT", "GLUE_TYPE", "GLUE_SOURCE", "GLUE_REMARK", "GLUE_UPDATETIME", "CHILD_JOBID") VALUES (1, 1, '测试任务1', TO_DATE('2018-11-03 22:21:31','yyyy-mm-dd hh24:mi:ss'), TO_DATE('2018-11-03 22:21:31','yyyy-mm-dd hh24:mi:ss'), 'XXL', '', 'CRON', '0 0 0 * * ? *', 'DO_NOTHING', 'FIRST', 'demoJobHandler', '', 'SERIAL_EXECUTION', 0, 0, 'BEAN', '', 'GLUE代码初始化', TO_DATE('2018-11-03 22:21:31','yyyy-mm-dd hh24:mi:ss'), '');
INSERT INTO "XXL_JOB_USER"("ID", "USERNAME", "PASSWORD", "ROLE", "PERMISSION") VALUES (1, 'admin', 'e10adc3949ba59abbe56e057f20f883e', 1, NULL);
INSERT INTO "XXL_JOB_LOCK"("LOCK_NAME") VALUES ('schedule_lock');
3.1.3 高斯 gaussdb
CREATE SEQUENCE xxl_job_group_id_seq INCREMENT 1 MINVALUE 1 MAXVALUE 2147483647 START 1 CACHE 1;
SELECT
setval ( 'xxl_job_group_id_seq', 2, TRUE );
CREATE SEQUENCE xxl_job_info_id_seq INCREMENT 1 MINVALUE 1 MAXVALUE 2147483647 START 1 CACHE 1;
CREATE SEQUENCE xxl_job_log_id_seq INCREMENT 1 MINVALUE 1 MAXVALUE 2147483647 START 1 CACHE 1;
CREATE SEQUENCE xxl_job_logglue_id_seq INCREMENT 1 MINVALUE 1 MAXVALUE 2147483647 START 1 CACHE 1;
CREATE SEQUENCE xxl_job_log_report_id_seq INCREMENT 1 MINVALUE 1 MAXVALUE 2147483647 START 1 CACHE 1;
CREATE SEQUENCE xxl_job_registry_id_seq INCREMENT 1 MINVALUE 1 MAXVALUE 2147483647 START 1 CACHE 1;
CREATE SEQUENCE xxl_job_user_id_seq INCREMENT 1 MINVALUE 1 MAXVALUE 2147483647 START 1 CACHE 1;
SELECT
setval ( 'xxl_job_user_id_seq', 2, TRUE );
SELECT
setval ( 'xxl_job_info_id_seq', 2, TRUE );
DROP TABLE IF EXISTS XXL_JOB_INFO CASCADE;
CREATE TABLE XXL_JOB_INFO (
ID INT NOT NULL DEFAULT nextval ( 'xxl_job_info_id_seq' :: regclass ),
JOB_GROUP INT NOT NULL,
JOB_DESC VARCHAR(255) NOT NULL,
ADD_TIME TIMESTAMP DEFAULT NULL,
UPDATE_TIME TIMESTAMP DEFAULT NULL,
AUTHOR VARCHAR(64) DEFAULT NULL,
ALARM_EMAIL VARCHAR(255) DEFAULT NULL,
SCHEDULE_TYPE VARCHAR(50) NOT NULL DEFAULT 'NONE',
SCHEDULE_CONF VARCHAR(128) DEFAULT NULL,
MISFIRE_STRATEGY VARCHAR(50) NOT NULL DEFAULT 'DO_NOTHING' ,
EXECUTOR_ROUTE_STRATEGY VARCHAR(50) DEFAULT NULL,
EXECUTOR_HANDLER VARCHAR(255) DEFAULT NULL,
EXECUTOR_PARAM VARCHAR(512) DEFAULT NULL,
EXECUTOR_BLOCK_STRATEGY VARCHAR(50) DEFAULT NULL,
EXECUTOR_TIMEOUT INT NOT NULL DEFAULT 0,
EXECUTOR_FAIL_RETRY_COUNT INT NOT NULL DEFAULT 0,
GLUE_TYPE VARCHAR(50) NOT NULL,
GLUE_SOURCE TEXT,
GLUE_REMARK VARCHAR(128) DEFAULT NULL,
GLUE_UPDATETIME TIMESTAMP DEFAULT NULL,
CHILD_JOBID VARCHAR(255) DEFAULT NULL,
TRIGGER_STATUS SMALLINT NOT NULL DEFAULT 0,
TRIGGER_LAST_TIME BIGINT NOT NULL DEFAULT 0,
TRIGGER_NEXT_TIME BIGINT NOT NULL DEFAULT 0,
PRIMARY KEY (ID)
) ;
COMMENT ON COLUMN XXL_JOB_INFO.JOB_GROUP IS '执行器主键ID';
COMMENT ON COLUMN XXL_JOB_INFO.AUTHOR IS '作者';
COMMENT ON COLUMN XXL_JOB_INFO.ALARM_EMAIL IS '报警邮件';
COMMENT ON COLUMN XXL_JOB_INFO.SCHEDULE_TYPE IS '调度类型';
COMMENT ON COLUMN XXL_JOB_INFO.SCHEDULE_CONF IS '调度配置,值含义取决于调度类型';
COMMENT ON COLUMN XXL_JOB_INFO.MISFIRE_STRATEGY IS '调度过期策略';
COMMENT ON COLUMN XXL_JOB_INFO.EXECUTOR_ROUTE_STRATEGY IS '执行器路由策略';
COMMENT ON COLUMN XXL_JOB_INFO.EXECUTOR_HANDLER IS '执行器任务handler';
COMMENT ON COLUMN XXL_JOB_INFO.EXECUTOR_PARAM IS '执行器任务参数';
COMMENT ON COLUMN XXL_JOB_INFO.EXECUTOR_BLOCK_STRATEGY IS '阻塞处理策略';
COMMENT ON COLUMN XXL_JOB_INFO.EXECUTOR_TIMEOUT IS '任务执行超时时间,单位秒';
COMMENT ON COLUMN XXL_JOB_INFO.EXECUTOR_FAIL_RETRY_COUNT IS '失败重试次数';
COMMENT ON COLUMN XXL_JOB_INFO.GLUE_TYPE IS 'GLUE类型';
COMMENT ON COLUMN XXL_JOB_INFO.GLUE_SOURCE IS 'GLUE源代码';
COMMENT ON COLUMN XXL_JOB_INFO.GLUE_REMARK IS 'GLUE备注';
COMMENT ON COLUMN XXL_JOB_INFO.GLUE_UPDATETIME IS 'GLUE更新时间';
COMMENT ON COLUMN XXL_JOB_INFO.CHILD_JOBID IS '子任务ID,多个逗号分隔';
COMMENT ON COLUMN XXL_JOB_INFO.TRIGGER_STATUS IS '调度状态:0-停止,1-运行';
COMMENT ON COLUMN XXL_JOB_INFO.TRIGGER_LAST_TIME IS '上次调度时间';
COMMENT ON COLUMN XXL_JOB_INFO.TRIGGER_NEXT_TIME IS '下次调度时间';
-- ----------------------------
-- Table structure for XXL_JOB_LOG
-- ----------------------------
DROP TABLE IF EXISTS XXL_JOB_LOG CASCADE;
CREATE TABLE XXL_JOB_LOG (
ID INT NOT NULL DEFAULT nextval ( 'xxl_job_log_id_seq' :: regclass ),
JOB_GROUP INT NOT NULL,
JOB_ID INT NOT NULL,
EXECUTOR_ADDRESS VARCHAR(255) DEFAULT NULL,
EXECUTOR_HANDLER VARCHAR(255) DEFAULT NULL,
EXECUTOR_PARAM VARCHAR(512) DEFAULT NULL,
EXECUTOR_SHARDING_PARAM VARCHAR(20) DEFAULT NULL,
EXECUTOR_FAIL_RETRY_COUNT INT NOT NULL DEFAULT 0 ,
TRIGGER_TIME TIMESTAMP DEFAULT NULL,
TRIGGER_CODE INT NOT NULL,
TRIGGER_MSG TEXT,
HANDLE_TIME TIMESTAMP DEFAULT NULL,
HANDLE_CODE INT NOT NULL,
HANDLE_MSG TEXT,
ALARM_STATUS SMALLINT NOT NULL DEFAULT 0 ,
PRIMARY KEY (ID)
) ;
CREATE INDEX LOG_I_HANDLE_CODE ON XXL_JOB_LOG USING btree (HANDLE_CODE) ;
CREATE INDEX LOG_I_TRIGGER_TIME ON XXL_JOB_LOG USING btree (TRIGGER_TIME) ;
COMMENT ON COLUMN XXL_JOB_LOG.JOB_GROUP IS '执行器主键ID';
COMMENT ON COLUMN XXL_JOB_LOG.JOB_ID IS '任务,主键ID';
COMMENT ON COLUMN XXL_JOB_LOG.EXECUTOR_ADDRESS IS '执行器地址,本次执行的地址';
COMMENT ON COLUMN XXL_JOB_LOG.EXECUTOR_HANDLER IS '执行器任务handler';
COMMENT ON COLUMN XXL_JOB_LOG.EXECUTOR_PARAM IS '执行器任务参数';
COMMENT ON COLUMN XXL_JOB_LOG.EXECUTOR_SHARDING_PARAM IS '执行器任务分片参数,格式如 1/2';
COMMENT ON COLUMN XXL_JOB_LOG.EXECUTOR_FAIL_RETRY_COUNT IS '失败重试次数';
COMMENT ON COLUMN XXL_JOB_LOG.TRIGGER_TIME IS '调度-时间';
COMMENT ON COLUMN XXL_JOB_LOG.TRIGGER_CODE IS '调度-结果';
COMMENT ON COLUMN XXL_JOB_LOG.TRIGGER_MSG IS '调度-日志';
COMMENT ON COLUMN XXL_JOB_LOG.HANDLE_TIME IS '执行-时间';
COMMENT ON COLUMN XXL_JOB_LOG.HANDLE_CODE IS '执行-状态';
COMMENT ON COLUMN XXL_JOB_LOG.HANDLE_MSG IS '执行-日志';
COMMENT ON COLUMN XXL_JOB_LOG.ALARM_STATUS IS '告警状态:0-默认、1-无需告警、2-告警成功、3-告警失败';
-- ----------------------------
-- Table structure for XXL_JOB_LOG_REPORT
-- ----------------------------
DROP TABLE IF EXISTS XXL_JOB_LOG_REPORT CASCADE;
CREATE TABLE XXL_JOB_LOG_REPORT (
ID INT NOT NULL DEFAULT nextval ( 'xxl_job_log_report_id_seq' :: regclass ),
TRIGGER_DAY TIMESTAMP DEFAULT NULL ,
RUNNING_COUNT INT NOT NULL DEFAULT 0 ,
SUC_COUNT INT NOT NULL DEFAULT 0 ,
FAIL_COUNT INT NOT NULL DEFAULT 0 ,
UPDATE_TIME TIMESTAMP DEFAULT NULL,
PRIMARY KEY (ID)
);
CREATE INDEX I_TRIGGER_DAY ON XXL_JOB_LOG_REPORT USING btree (TRIGGER_DAY) ;
COMMENT ON COLUMN XXL_JOB_LOG_REPORT.TRIGGER_DAY IS '调度-时间';
COMMENT ON COLUMN XXL_JOB_LOG_REPORT.RUNNING_COUNT IS '运行中-日志数量';
COMMENT ON COLUMN XXL_JOB_LOG_REPORT.SUC_COUNT IS '执行成功-日志数量';
COMMENT ON COLUMN XXL_JOB_LOG_REPORT.FAIL_COUNT IS '执行失败-日志数量';
-- ----------------------------
-- Table structure for XXL_JOB_LOGGLUE
-- ----------------------------
DROP TABLE IF EXISTS XXL_JOB_LOGGLUE CASCADE;
CREATE TABLE XXL_JOB_LOGGLUE (
ID INT NOT NULL DEFAULT nextval ( 'xxl_job_logglue_id_seq' :: regclass ),
JOB_ID INT NOT NULL ,
GLUE_TYPE VARCHAR(50) DEFAULT NULL ,
GLUE_SOURCE TEXT ,
GLUE_REMARK VARCHAR(128) NOT NULL ,
ADD_TIME TIMESTAMP DEFAULT NULL,
UPDATE_TIME TIMESTAMP DEFAULT NULL,
PRIMARY KEY (ID)
) ;
COMMENT ON COLUMN XXL_JOB_LOGGLUE.JOB_ID IS '任务,主键ID';
COMMENT ON COLUMN XXL_JOB_LOGGLUE.GLUE_TYPE IS 'GLUE类型';
COMMENT ON COLUMN XXL_JOB_LOGGLUE.GLUE_SOURCE IS 'GLUE源代码';
COMMENT ON COLUMN XXL_JOB_LOGGLUE.GLUE_REMARK IS 'GLUE备注';
-- ----------------------------
-- Table structure for XXL_JOB_REGISTRY
-- ----------------------------
DROP TABLE IF EXISTS XXL_JOB_REGISTRY CASCADE;
CREATE TABLE XXL_JOB_REGISTRY (
ID INT NOT NULL DEFAULT nextval ( 'xxl_job_registry_id_seq' :: regclass ),
REGISTRY_GROUP VARCHAR(50) NOT NULL,
REGISTRY_KEY VARCHAR(255) NOT NULL,
REGISTRY_VALUE VARCHAR(255) NOT NULL,
UPDATE_TIME TIMESTAMP DEFAULT NULL,
PRIMARY KEY (ID)
) ;
CREATE INDEX I_G_K_V ON XXL_JOB_REGISTRY USING btree(REGISTRY_GROUP, REGISTRY_KEY, REGISTRY_VALUE);
-- ----------------------------
-- Table structure for XXL_JOB_GROUP
-- ----------------------------
DROP TABLE IF EXISTS XXL_JOB_GROUP CASCADE;
CREATE TABLE XXL_JOB_GROUP (
ID INT NOT NULL DEFAULT nextval ( 'xxl_job_group_id_seq' :: regclass ),
APP_NAME VARCHAR(64) NOT NULL ,
TITLE VARCHAR(64) NOT NULL ,
ADDRESS_TYPE SMALLINT NOT NULL DEFAULT 0 ,
ADDRESS_LIST TEXT ,
UPDATE_TIME TIMESTAMP DEFAULT NULL,
PRIMARY KEY (ID)
) ;
COMMENT ON COLUMN XXL_JOB_GROUP.APP_NAME IS '执行器AppName';
COMMENT ON COLUMN XXL_JOB_GROUP.TITLE IS '执行器名称';
COMMENT ON COLUMN XXL_JOB_GROUP.ADDRESS_TYPE IS '执行器地址类型:0=自动注册、1=手动录入';
COMMENT ON COLUMN XXL_JOB_GROUP.ADDRESS_LIST IS '执行器地址列表,多地址逗号分隔';
-- ----------------------------
-- Table structure for XXL_JOB_USER
-- ----------------------------
DROP TABLE IF EXISTS XXL_JOB_USER CASCADE;
CREATE TABLE XXL_JOB_USER (
ID INT NOT NULL DEFAULT nextval ( 'xxl_job_user_id_seq' :: regclass ) ,
USERNAME VARCHAR(50) NOT NULL ,
PASSWORD VARCHAR(50) NOT NULL ,
ROLE SMALLINT NOT NULL ,
PERMISSION VARCHAR(255) DEFAULT NULL,
PRIMARY KEY (ID)
) ;
CREATE UNIQUE INDEX I_USERNAME ON XXL_JOB_USER USING btree(USERNAME);
COMMENT ON COLUMN XXL_JOB_USER.USERNAME IS '账号';
COMMENT ON COLUMN XXL_JOB_USER.PASSWORD IS '密码';
COMMENT ON COLUMN XXL_JOB_USER.ROLE IS '角色:0-普通用户、1-管理员';
COMMENT ON COLUMN XXL_JOB_USER.PERMISSION IS '权限:执行器ID列表,多个逗号分割';
-- ----------------------------
-- Table structure for XXL_JOB_LOCK
-- ----------------------------
DROP TABLE IF EXISTS XXL_JOB_LOCK CASCADE;
CREATE TABLE XXL_JOB_LOCK (
LOCK_NAME VARCHAR(50) NOT NULL ,
PRIMARY KEY (LOCK_NAME)
) ;
COMMENT ON COLUMN XXL_JOB_LOCK.LOCK_NAME IS '锁名称';
-- 2023-12-27 适配xxl-job
INSERT INTO XXL_JOB_GROUP(ID, APP_NAME, TITLE, ADDRESS_TYPE, ADDRESS_LIST, UPDATE_TIME) VALUES (1, 'xxl-job-executor-sample', '示例执行器', 0, NULL, '2018-11-03 22:21:31' );
INSERT INTO XXL_JOB_INFO(ID, JOB_GROUP, JOB_DESC, ADD_TIME, UPDATE_TIME, AUTHOR, ALARM_EMAIL, SCHEDULE_TYPE, SCHEDULE_CONF, MISFIRE_STRATEGY, EXECUTOR_ROUTE_STRATEGY, EXECUTOR_HANDLER, EXECUTOR_PARAM, EXECUTOR_BLOCK_STRATEGY, EXECUTOR_TIMEOUT, EXECUTOR_FAIL_RETRY_COUNT, GLUE_TYPE, GLUE_SOURCE, GLUE_REMARK, GLUE_UPDATETIME, CHILD_JOBID) VALUES (1, 1, '测试任务1', '2018-11-03 22:21:31', '2018-11-03 22:21:31', 'XXL', '', 'CRON', '0 0 0 * * ? *', 'DO_NOTHING', 'FIRST', 'demoJobHandler', '', 'SERIAL_EXECUTION', 0, 0, 'BEAN', '', 'GLUE代码初始化', '2018-11-03 22:21:31', '');
INSERT INTO XXL_JOB_USER(ID, USERNAME, PASSWORD, ROLE, PERMISSION) VALUES (1, 'admin', 'e10adc3949ba59abbe56e057f20f883e', 1, NULL);
INSERT INTO XXL_JOB_LOCK(LOCK_NAME) VALUES ( 'schedule_lock');
3.1.4 人大金仓 kingbase
DROP TABLE IF EXISTS XXL_JOB_GROUP;
CREATE TABLE XXL_JOB_GROUP (
ID SERIAL NOT NULL ,
APP_NAME VARCHAR(64) NOT NULL ,
TITLE VARCHAR(64) NOT NULL ,
ADDRESS_TYPE SMALLINT NOT NULL DEFAULT 0 ,
ADDRESS_LIST TEXT ,
UPDATE_TIME TIMESTAMP DEFAULT NULL ,
PRIMARY KEY (ID)
) ;
COMMENT ON COLUMN XXL_JOB_GROUP.APP_NAME IS '执行器AppName';
COMMENT ON COLUMN XXL_JOB_GROUP.TITLE IS '执行器名称';
COMMENT ON COLUMN XXL_JOB_GROUP.ADDRESS_TYPE IS '执行器地址类型:0=自动注册、1=手动录入';
COMMENT ON COLUMN XXL_JOB_GROUP.ADDRESS_LIST IS '执行器地址列表,多地址逗号分隔';
CREATE SEQUENCE "XXL_JOB_GROUP_ID_SEQ"
START WITH 1
INCREMENT BY 1
NO MINVALUE
NO MAXVALUE
CACHE 1;
ALTER SEQUENCE "XXL_JOB_GROUP_ID_SEQ" OWNED BY "XXL_JOB_GROUP"."ID";
DROP TABLE IF EXISTS XXL_JOB_INFO;
CREATE TABLE XXL_JOB_INFO (
ID SERIAL NOT NULL ,
JOB_GROUP INT NOT NULL ,
JOB_DESC VARCHAR(255) NOT NULL ,
ADD_TIME TIMESTAMP DEFAULT NULL ,
UPDATE_TIME TIMESTAMP DEFAULT NULL ,
AUTHOR VARCHAR(64) DEFAULT NULL ,
ALARM_EMAIL VARCHAR(255) DEFAULT NULL ,
SCHEDULE_TYPE VARCHAR(50) NOT NULL DEFAULT 'NONE' ,
SCHEDULE_CONF VARCHAR(128) DEFAULT NULL ,
MISFIRE_STRATEGY VARCHAR(50) NOT NULL DEFAULT 'DO_NOTHING' ,
EXECUTOR_ROUTE_STRATEGY VARCHAR(50) DEFAULT NULL ,
EXECUTOR_HANDLER VARCHAR(255) DEFAULT NULL ,
EXECUTOR_PARAM VARCHAR(512) DEFAULT NULL ,
EXECUTOR_BLOCK_STRATEGY VARCHAR(50) DEFAULT NULL ,
EXECUTOR_TIMEOUT INT NOT NULL DEFAULT 0 ,
EXECUTOR_FAIL_RETRY_COUNT INT NOT NULL DEFAULT 0 ,
GLUE_TYPE VARCHAR(50) NOT NULL ,
GLUE_SOURCE TEXT ,
GLUE_REMARK VARCHAR(128) DEFAULT NULL ,
GLUE_UPDATETIME DATE DEFAULT NULL ,
CHILD_JOBID VARCHAR(255) DEFAULT NULL ,
TRIGGER_STATUS SMALLINT NOT NULL DEFAULT 0 ,
TRIGGER_LAST_TIME BIGINT NOT NULL DEFAULT 0 ,
TRIGGER_NEXT_TIME BIGINT NOT NULL DEFAULT 0 ,
PRIMARY KEY (ID)
) ;
COMMENT ON COLUMN XXL_JOB_INFO.JOB_GROUP IS '执行器主键ID';
COMMENT ON COLUMN XXL_JOB_INFO.AUTHOR IS '作者';
COMMENT ON COLUMN XXL_JOB_INFO.ALARM_EMAIL IS '报警邮件';
COMMENT ON COLUMN XXL_JOB_INFO.SCHEDULE_TYPE IS '调度类型';
COMMENT ON COLUMN XXL_JOB_INFO.SCHEDULE_CONF IS '调度配置,值含义取决于调度类型';
COMMENT ON COLUMN XXL_JOB_INFO.MISFIRE_STRATEGY IS '调度过期策略';
COMMENT ON COLUMN XXL_JOB_INFO.EXECUTOR_ROUTE_STRATEGY IS '执行器路由策略';
COMMENT ON COLUMN XXL_JOB_INFO.EXECUTOR_HANDLER IS '执行器任务handler';
COMMENT ON COLUMN XXL_JOB_INFO.EXECUTOR_PARAM IS '执行器任务参数';
COMMENT ON COLUMN XXL_JOB_INFO.EXECUTOR_BLOCK_STRATEGY IS '阻塞处理策略';
COMMENT ON COLUMN XXL_JOB_INFO.EXECUTOR_TIMEOUT IS '任务执行超时时间,单位秒';
COMMENT ON COLUMN XXL_JOB_INFO.EXECUTOR_FAIL_RETRY_COUNT IS '失败重试次数';
COMMENT ON COLUMN XXL_JOB_INFO.GLUE_TYPE IS 'GLUE类型';
COMMENT ON COLUMN XXL_JOB_INFO.GLUE_SOURCE IS 'GLUE源代码';
COMMENT ON COLUMN XXL_JOB_INFO.GLUE_REMARK IS 'GLUE备注';
COMMENT ON COLUMN XXL_JOB_INFO.GLUE_UPDATETIME IS 'GLUE更新时间';
COMMENT ON COLUMN XXL_JOB_INFO.CHILD_JOBID IS '子任务ID,多个逗号分隔';
COMMENT ON COLUMN XXL_JOB_INFO.TRIGGER_STATUS IS '调度状态:0-停止,1-运行';
COMMENT ON COLUMN XXL_JOB_INFO.TRIGGER_LAST_TIME IS '上次调度时间';
COMMENT ON COLUMN XXL_JOB_INFO.TRIGGER_NEXT_TIME IS '下次调度时间';
CREATE SEQUENCE "XXL_JOB_INFO_ID_SEQ"
START WITH 1
INCREMENT BY 1
NO MINVALUE
NO MAXVALUE
CACHE 1;
ALTER SEQUENCE "XXL_JOB_INFO_ID_SEQ" OWNED BY "XXL_JOB_INFO"."ID";
DROP TABLE IF EXISTS XXL_JOB_LOCK;
CREATE TABLE XXL_JOB_LOCK (
LOCK_NAME VARCHAR(50) NOT NULL ,
PRIMARY KEY (LOCK_NAME)
) ;
COMMENT ON COLUMN XXL_JOB_LOCK.LOCK_NAME IS '锁名称';
DROP TABLE IF EXISTS XXL_JOB_LOG;
CREATE TABLE XXL_JOB_LOG (
ID BIGSERIAL NOT NULL ,
JOB_GROUP INT NOT NULL ,
JOB_ID INT NOT NULL ,
EXECUTOR_ADDRESS VARCHAR(255) DEFAULT NULL ,
EXECUTOR_HANDLER VARCHAR(255) DEFAULT NULL ,
EXECUTOR_PARAM VARCHAR(512) DEFAULT NULL ,
EXECUTOR_SHARDING_PARAM VARCHAR(20) DEFAULT NULL ,
EXECUTOR_FAIL_RETRY_COUNT INT NOT NULL DEFAULT 0 ,
TRIGGER_TIME TIMESTAMP DEFAULT NULL ,
TRIGGER_CODE INT NOT NULL ,
TRIGGER_MSG TEXT ,
HANDLE_TIME TIMESTAMP DEFAULT NULL ,
HANDLE_CODE INT NOT NULL ,
HANDLE_MSG TEXT ,
ALARM_STATUS SMALLINT NOT NULL DEFAULT 0 ,
PRIMARY KEY (ID)
) ;
CREATE INDEX I_TRIGGER_TIME ON XXL_JOB_LOG USING btree (TRIGGER_TIME) ;
CREATE INDEX I_HANDLE_CODE ON XXL_JOB_LOG USING btree (HANDLE_CODE) ;
COMMENT ON COLUMN XXL_JOB_LOG.JOB_GROUP IS '执行器主键ID';
COMMENT ON COLUMN XXL_JOB_LOG.JOB_ID IS '任务,主键ID';
COMMENT ON COLUMN XXL_JOB_LOG.EXECUTOR_ADDRESS IS '执行器地址,本次执行的地址';
COMMENT ON COLUMN XXL_JOB_LOG.EXECUTOR_HANDLER IS '执行器任务handler';
COMMENT ON COLUMN XXL_JOB_LOG.EXECUTOR_PARAM IS '执行器任务参数';
COMMENT ON COLUMN XXL_JOB_LOG.EXECUTOR_SHARDING_PARAM IS '执行器任务分片参数,格式如 1/2';
COMMENT ON COLUMN XXL_JOB_LOG.EXECUTOR_FAIL_RETRY_COUNT IS '失败重试次数';
COMMENT ON COLUMN XXL_JOB_LOG.TRIGGER_TIME IS '调度-时间';
COMMENT ON COLUMN XXL_JOB_LOG.TRIGGER_CODE IS '调度-结果';
COMMENT ON COLUMN XXL_JOB_LOG.TRIGGER_MSG IS '调度-日志';
COMMENT ON COLUMN XXL_JOB_LOG.HANDLE_TIME IS '执行-时间';
COMMENT ON COLUMN XXL_JOB_LOG.HANDLE_CODE IS '执行-状态';
COMMENT ON COLUMN XXL_JOB_LOG.HANDLE_MSG IS '执行-日志';
COMMENT ON COLUMN XXL_JOB_LOG.ALARM_STATUS IS '告警状态:0-默认、1-无需告警、2-告警成功、3-告警失败';
DROP TABLE IF EXISTS XXL_JOB_LOGGLUE;
CREATE TABLE XXL_JOB_LOGGLUE (
ID SERIAL NOT NULL ,
JOB_ID INT NOT NULL ,
GLUE_TYPE VARCHAR(50) DEFAULT NULL ,
GLUE_SOURCE TEXT ,
GLUE_REMARK VARCHAR(128) NOT NULL ,
ADD_TIME TIMESTAMP DEFAULT NULL ,
UPDATE_TIME TIMESTAMP DEFAULT NULL ,
PRIMARY KEY (ID)
) ;
COMMENT ON COLUMN XXL_JOB_LOGGLUE.JOB_ID IS '任务,主键ID';
COMMENT ON COLUMN XXL_JOB_LOGGLUE.GLUE_TYPE IS 'GLUE类型';
COMMENT ON COLUMN XXL_JOB_LOGGLUE.GLUE_SOURCE IS 'GLUE源代码';
COMMENT ON COLUMN XXL_JOB_LOGGLUE.GLUE_REMARK IS 'GLUE备注';
CREATE SEQUENCE "XXL_JOB_LOGGLUE_ID_SEQ"
START WITH 1
INCREMENT BY 1
NO MINVALUE
NO MAXVALUE
CACHE 1;
ALTER SEQUENCE "XXL_JOB_LOGGLUE_ID_SEQ" OWNED BY "XXL_JOB_LOGGLUE"."ID";
CREATE SEQUENCE "XXL_JOB_LOG_ID_SEQ"
START WITH 1
INCREMENT BY 1
NO MINVALUE
NO MAXVALUE
CACHE 1;
ALTER SEQUENCE "XXL_JOB_LOG_ID_SEQ" OWNED BY "XXL_JOB_LOG"."ID";
DROP TABLE IF EXISTS XXL_JOB_LOG_REPORT;
CREATE TABLE XXL_JOB_LOG_REPORT (
ID SERIAL NOT NULL ,
TRIGGER_DAY TIMESTAMP DEFAULT NULL ,
RUNNING_COUNT INT NOT NULL DEFAULT 0 ,
SUC_COUNT INT NOT NULL DEFAULT 0 ,
FAIL_COUNT INT NOT NULL DEFAULT 0 ,
UPDATE_TIME TIMESTAMP DEFAULT NULL ,
PRIMARY KEY (ID)
);
CREATE UNIQUE INDEX I_TRIGGER_DAY ON XXL_JOB_LOG_REPORT USING btree(TRIGGER_DAY) ;
COMMENT ON COLUMN XXL_JOB_LOG_REPORT.TRIGGER_DAY IS '调度-时间';
COMMENT ON COLUMN XXL_JOB_LOG_REPORT.RUNNING_COUNT IS '运行中-日志数量';
COMMENT ON COLUMN XXL_JOB_LOG_REPORT.SUC_COUNT IS '执行成功-日志数量';
COMMENT ON COLUMN XXL_JOB_LOG_REPORT.FAIL_COUNT IS '执行失败-日志数量';
CREATE SEQUENCE "XXL_JOB_LOG_REPORT_ID_SEQ"
START WITH 1
INCREMENT BY 1
NO MINVALUE
NO MAXVALUE
CACHE 1;
ALTER SEQUENCE "XXL_JOB_LOG_REPORT_ID_SEQ" OWNED BY "XXL_JOB_LOG_REPORT"."ID";
DROP TABLE IF EXISTS XXL_JOB_REGISTRY;
CREATE TABLE XXL_JOB_REGISTRY (
ID SERIAL NOT NULL ,
REGISTRY_GROUP VARCHAR(50) NOT NULL ,
REGISTRY_KEY VARCHAR(255) NOT NULL ,
REGISTRY_VALUE VARCHAR(255) NOT NULL ,
UPDATE_TIME TIMESTAMP DEFAULT NULL ,
PRIMARY KEY (ID)
) ;
CREATE INDEX I_G_K_V ON XXL_JOB_REGISTRY USING btree(REGISTRY_GROUP, REGISTRY_KEY, REGISTRY_VALUE);
CREATE SEQUENCE "XXL_JOB_REGISTRY_ID_SEQ"
START WITH 1
INCREMENT BY 1
NO MINVALUE
NO MAXVALUE
CACHE 1;
ALTER SEQUENCE "XXL_JOB_REGISTRY_ID_SEQ" OWNED BY "XXL_JOB_REGISTRY"."ID";
DROP TABLE IF EXISTS XXL_JOB_USER;
CREATE TABLE XXL_JOB_USER (
ID SERIAL NOT NULL ,
USERNAME VARCHAR(50) NOT NULL ,
PASSWORD VARCHAR(50) NOT NULL ,
ROLE SMALLINT NOT NULL ,
PERMISSION VARCHAR(255) DEFAULT NULL ,
PRIMARY KEY (ID)
) ;
CREATE UNIQUE INDEX I_USERNAME ON XXL_JOB_USER USING btree(USERNAME);
COMMENT ON COLUMN XXL_JOB_USER.USERNAME IS '账号';
COMMENT ON COLUMN XXL_JOB_USER.PASSWORD IS '密码';
COMMENT ON COLUMN XXL_JOB_USER.ROLE IS '角色:0-普通用户、1-管理员';
COMMENT ON COLUMN XXL_JOB_USER.PERMISSION IS '权限:执行器ID列表,多个逗号分割';
CREATE SEQUENCE "XXL_JOB_USER_ID_SEQ"
START WITH 1
INCREMENT BY 1
NO MINVALUE
NO MAXVALUE
CACHE 1;
ALTER SEQUENCE "XXL_JOB_USER_ID_SEQ" OWNED BY "XXL_JOB_USER"."ID";
ALTER TABLE ONLY "XXL_JOB_GROUP" ALTER COLUMN "ID" SET DEFAULT NEXTVAL('PUBLIC.XXL_JOB_GROUP_ID_SEQ'::REGCLASS);
ALTER TABLE ONLY "XXL_JOB_INFO" ALTER COLUMN "ID" SET DEFAULT NEXTVAL('PUBLIC.XXL_JOB_INFO_ID_SEQ'::REGCLASS);
ALTER TABLE ONLY "XXL_JOB_LOG" ALTER COLUMN "ID" SET DEFAULT NEXTVAL('PUBLIC.XXL_JOB_LOG_ID_SEQ'::REGCLASS);
ALTER TABLE ONLY "XXL_JOB_LOGGLUE" ALTER COLUMN "ID" SET DEFAULT NEXTVAL('PUBLIC.XXL_JOB_LOGGLUE_ID_SEQ'::REGCLASS);
ALTER TABLE ONLY "XXL_JOB_LOG_REPORT" ALTER COLUMN "ID" SET DEFAULT NEXTVAL('PUBLIC.XXL_JOB_LOG_REPORT_ID_SEQ'::REGCLASS);
ALTER TABLE ONLY "XXL_JOB_REGISTRY" ALTER COLUMN "ID" SET DEFAULT NEXTVAL('PUBLIC.XXL_JOB_REGISTRY_ID_SEQ'::REGCLASS);
ALTER TABLE ONLY "XXL_JOB_USER" ALTER COLUMN "ID" SET DEFAULT NEXTVAL('PUBLIC.XXL_JOB_USER_ID_SEQ'::REGCLASS);
SELECT sys_catalog.setval('"XXL_JOB_GROUP_ID_SEQ"', 10, true);
SELECT sys_catalog.setval('"XXL_JOB_INFO_ID_SEQ"', 10, true);
SELECT sys_catalog.setval('"XXL_JOB_LOGGLUE_ID_SEQ"', 10, true);
SELECT sys_catalog.setval('"XXL_JOB_LOG_ID_SEQ"', 10, true);
SELECT sys_catalog.setval('"XXL_JOB_LOG_REPORT_ID_SEQ"', 10, true);
SELECT sys_catalog.setval('"XXL_JOB_REGISTRY_ID_SEQ"', 10, true);
SELECT sys_catalog.setval('"XXL_JOB_USER_ID_SEQ"', 1, false);
CREATE INDEX "I_handle_code" ON PUBLIC.XXL_JOB_LOG USING BTREE (HANDLE_CODE);
CREATE INDEX "I_trigger_time" ON PUBLIC.XXL_JOB_LOG USING BTREE (TRIGGER_TIME);
CREATE INDEX "i_g_k_v" ON PUBLIC.XXL_JOB_REGISTRY USING BTREE (REGISTRY_GROUP, REGISTRY_KEY, REGISTRY_VALUE);
-- 2023-12-27 适配xxl-job
INSERT INTO XXL_JOB_GROUP(ID, APP_NAME, TITLE, ADDRESS_TYPE, ADDRESS_LIST, UPDATE_TIME) VALUES (1, 'xxl-job-executor-sample', '示例执行器', 0, NULL, '2018-11-03 22:21:31' );
INSERT INTO XXL_JOB_INFO(ID, JOB_GROUP, JOB_DESC, ADD_TIME, UPDATE_TIME, AUTHOR, ALARM_EMAIL, SCHEDULE_TYPE, SCHEDULE_CONF, MISFIRE_STRATEGY, EXECUTOR_ROUTE_STRATEGY, EXECUTOR_HANDLER, EXECUTOR_PARAM, EXECUTOR_BLOCK_STRATEGY, EXECUTOR_TIMEOUT, EXECUTOR_FAIL_RETRY_COUNT, GLUE_TYPE, GLUE_SOURCE, GLUE_REMARK, GLUE_UPDATETIME, CHILD_JOBID) VALUES (1, 1, '测试任务1', '2018-11-03 22:21:31', '2018-11-03 22:21:31', 'XXL', '', 'CRON', '0 0 0 * * ? *', 'DO_NOTHING', 'FIRST', 'demoJobHandler', '', 'SERIAL_EXECUTION', 0, 0, 'BEAN', '', 'GLUE代码初始化', '2018-11-03 22:21:31', '');
INSERT INTO XXL_JOB_USER(ID, USERNAME, PASSWORD, ROLE, PERMISSION) VALUES (1, 'admin', 'e10adc3949ba59abbe56e057f20f883e', 1, NULL);
INSERT INTO XXL_JOB_LOCK (LOCK_NAME) VALUES ( 'schedule_lock');
3.1.5 postgresql
CREATE SEQUENCE xxl_job_group_id_seq INCREMENT 1 MINVALUE 1 MAXVALUE 2147483647 START 1 CACHE 1;
SELECT
setval ( 'xxl_job_group_id_seq', 2, TRUE );
CREATE SEQUENCE xxl_job_info_id_seq INCREMENT 1 MINVALUE 1 MAXVALUE 2147483647 START 1 CACHE 1;
CREATE SEQUENCE xxl_job_log_id_seq INCREMENT 1 MINVALUE 1 MAXVALUE 2147483647 START 1 CACHE 1;
CREATE SEQUENCE xxl_job_logglue_id_seq INCREMENT 1 MINVALUE 1 MAXVALUE 2147483647 START 1 CACHE 1;
CREATE SEQUENCE xxl_job_log_report_id_seq INCREMENT 1 MINVALUE 1 MAXVALUE 2147483647 START 1 CACHE 1;
CREATE SEQUENCE xxl_job_registry_id_seq INCREMENT 1 MINVALUE 1 MAXVALUE 2147483647 START 1 CACHE 1;
CREATE SEQUENCE xxl_job_user_id_seq INCREMENT 1 MINVALUE 1 MAXVALUE 2147483647 START 1 CACHE 1;
SELECT
setval ( 'xxl_job_user_id_seq', 2, TRUE );
SELECT
setval ( 'xxl_job_info_id_seq', 2, TRUE );
CREATE TABLE xxl_job_group (
id INT4 NOT NULL DEFAULT nextval ( 'xxl_job_group_id_seq' :: regclass ),
app_name VARCHAR ( 64 ) NOT NULL,
title VARCHAR ( 128 ) NOT NULL,
address_type INT2 NOT NULL,
address_list text,
update_time TIMESTAMP ( 6 )
);
COMMENT ON COLUMN xxl_job_group.app_name IS '执行器AppName';
COMMENT ON COLUMN xxl_job_group.title IS '执行器名称';
COMMENT ON COLUMN xxl_job_group.address_type IS '执行器地址类型:0=自动注册、1=手动录入';
COMMENT ON COLUMN xxl_job_group.address_list IS '执行器地址列表,多地址逗号分隔';
CREATE TABLE xxl_job_info (
id INT4 NOT NULL DEFAULT nextval ( 'xxl_job_info_id_seq' :: regclass ),
job_group INT4 NOT NULL,
job_desc VARCHAR ( 255 ) NOT NULL,
add_time TIMESTAMP ( 6 ),
update_time TIMESTAMP ( 6 ),
author VARCHAR ( 64 ),
alarm_email VARCHAR ( 255 ),
schedule_type VARCHAR ( 50 ) NOT NULL,
schedule_conf VARCHAR ( 128 ),
misfire_strategy VARCHAR ( 50 ) NOT NULL,
executor_route_strategy VARCHAR ( 50 ),
executor_handler VARCHAR ( 255 ),
executor_param VARCHAR ( 512 ),
executor_block_strategy VARCHAR ( 50 ),
executor_timeout INT4 NOT NULL,
executor_fail_retry_count INT4 NOT NULL,
glue_type VARCHAR ( 50 ) NOT NULL,
glue_source text,
glue_remark VARCHAR ( 128 ),
glue_updatetime TIMESTAMP ( 6 ),
child_jobid VARCHAR ( 255 ),
trigger_status INT2 NOT NULL DEFAULT 0,
trigger_last_time INT8 NOT NULL,
trigger_next_time INT8 NOT NULL
);
COMMENT ON COLUMN xxl_job_info.job_group IS '执行器主键ID';
COMMENT ON COLUMN xxl_job_info.author IS '作者';
COMMENT ON COLUMN xxl_job_info.alarm_email IS '报警邮件';
COMMENT ON COLUMN xxl_job_info.schedule_type IS '调度类型';
COMMENT ON COLUMN xxl_job_info.schedule_conf IS '调度配置,值含义取决于调度类型';
COMMENT ON COLUMN xxl_job_info.misfire_strategy IS '调度过期策略';
COMMENT ON COLUMN xxl_job_info.executor_route_strategy IS '执行器路由策略';
COMMENT ON COLUMN xxl_job_info.executor_handler IS '执行器任务handler';
COMMENT ON COLUMN xxl_job_info.executor_param IS '执行器任务参数';
COMMENT ON COLUMN xxl_job_info.executor_block_strategy IS '阻塞处理策略';
COMMENT ON COLUMN xxl_job_info.executor_timeout IS '任务执行超时时间,单位秒';
COMMENT ON COLUMN xxl_job_info.executor_fail_retry_count IS '失败重试次数';
COMMENT ON COLUMN xxl_job_info.glue_type IS 'GLUE类型';
COMMENT ON COLUMN xxl_job_info.glue_source IS 'GLUE源代码';
COMMENT ON COLUMN xxl_job_info.glue_remark IS 'GLUE备注';
COMMENT ON COLUMN xxl_job_info.glue_updatetime IS 'GLUE更新时间';
COMMENT ON COLUMN xxl_job_info.child_jobid IS '子任务ID,多个逗号分隔';
COMMENT ON COLUMN xxl_job_info.trigger_status IS '调度状态:0-停止,1-运行';
COMMENT ON COLUMN xxl_job_info.trigger_last_time IS '上次调度时间';
COMMENT ON COLUMN xxl_job_info.trigger_next_time IS '下次调度时间';
CREATE TABLE xxl_job_lock ( lock_name VARCHAR ( 50 ) NOT NULL );
COMMENT ON COLUMN xxl_job_lock.lock_name IS '锁名称';
CREATE TABLE xxl_job_log (
id INT4 NOT NULL DEFAULT nextval ( 'xxl_job_log_id_seq' :: regclass ),
job_group INT4 NOT NULL,
job_id INT4 NOT NULL,
executor_address VARCHAR ( 255 ),
executor_handler VARCHAR ( 255 ),
executor_param VARCHAR ( 512 ) ,
executor_sharding_param VARCHAR ( 20 ) ,
executor_fail_retry_count INT4 NOT NULL DEFAULT 0,
trigger_time TIMESTAMP ( 6 ),
trigger_code INT4 NOT NULL,
trigger_msg text ,
handle_time TIMESTAMP ( 6 ),
handle_code INT4 NOT NULL,
handle_msg text ,
alarm_status INT2 NOT NULL DEFAULT 0
);
COMMENT ON COLUMN xxl_job_log.job_group IS '执行器主键ID';
COMMENT ON COLUMN xxl_job_log.job_id IS '任务,主键ID';
COMMENT ON COLUMN xxl_job_log.executor_address IS '执行器地址,本次执行的地址';
COMMENT ON COLUMN xxl_job_log.executor_handler IS '执行器任务handler';
COMMENT ON COLUMN xxl_job_log.executor_param IS '执行器任务参数';
COMMENT ON COLUMN xxl_job_log.executor_sharding_param IS '执行器任务分片参数,格式如 1/2';
COMMENT ON COLUMN xxl_job_log.executor_fail_retry_count IS '失败重试次数';
COMMENT ON COLUMN xxl_job_log.trigger_time IS '调度-时间';
COMMENT ON COLUMN xxl_job_log.trigger_code IS '调度-结果';
COMMENT ON COLUMN xxl_job_log.trigger_msg IS '调度-日志';
COMMENT ON COLUMN xxl_job_log.handle_time IS '执行-时间';
COMMENT ON COLUMN xxl_job_log.handle_code IS '执行-状态';
COMMENT ON COLUMN xxl_job_log.handle_msg IS '执行-日志';
COMMENT ON COLUMN xxl_job_log.alarm_status IS '告警状态:0-默认、1-无需告警、2-告警成功、3-告警失败';
CREATE TABLE xxl_job_log_report (
id INT4 NOT NULL DEFAULT nextval ( 'xxl_job_log_report_id_seq' :: regclass ),
trigger_day TIMESTAMP ( 6 ),
running_count INT4 NOT NULL,
suc_count INT4 NOT NULL,
fail_count INT4 NOT NULL,
update_time TIMESTAMP ( 6 )
);
COMMENT ON COLUMN xxl_job_log_report.trigger_day IS '调度-时间';
COMMENT ON COLUMN xxl_job_log_report.running_count IS '运行中-日志数量';
COMMENT ON COLUMN xxl_job_log_report.suc_count IS '执行成功-日志数量';
COMMENT ON COLUMN xxl_job_log_report.fail_count IS '执行失败-日志数量';
CREATE TABLE xxl_job_logglue (
id INT4 NOT NULL DEFAULT nextval ( 'xxl_job_logglue_id_seq' :: regclass ),
job_id INT4 NOT NULL,
glue_type VARCHAR ( 50 ) ,
glue_source text ,
glue_remark VARCHAR ( 128 ) NOT NULL,
add_time TIMESTAMP ( 6 ),
update_time TIMESTAMP ( 6 )
);
COMMENT ON COLUMN xxl_job_logglue.job_id IS '任务,主键ID';
COMMENT ON COLUMN xxl_job_logglue.glue_type IS 'GLUE类型';
COMMENT ON COLUMN xxl_job_logglue.glue_source IS 'GLUE源代码';
COMMENT ON COLUMN xxl_job_logglue.glue_remark IS 'GLUE备注';
CREATE TABLE xxl_job_registry (
id INT4 NOT NULL DEFAULT nextval ( 'xxl_job_registry_id_seq' :: regclass ),
registry_group VARCHAR ( 50 ) NOT NULL,
registry_key VARCHAR ( 255 ) NOT NULL,
registry_value VARCHAR ( 255 ) NOT NULL,
update_time TIMESTAMP ( 6 )
);
CREATE TABLE xxl_job_user (
id INT4 NOT NULL DEFAULT nextval ( 'xxl_job_user_id_seq' :: regclass ),
username VARCHAR ( 50 ) NOT NULL,
password VARCHAR ( 50 ) NOT NULL,
role INT2 NOT NULL,
permission VARCHAR ( 255 )
);
COMMENT ON COLUMN xxl_job_user.username IS '账号';
COMMENT ON COLUMN xxl_job_user.password IS '密码';
COMMENT ON COLUMN xxl_job_user.role IS '角色:0-普通用户、1-管理员';
COMMENT ON COLUMN xxl_job_user.permission IS '权限:执行器ID列表,多个逗号分割';
ALTER TABLE xxl_job_group ADD CONSTRAINT xxl_job_group_pkey PRIMARY KEY ( id );
ALTER TABLE xxl_job_info ADD CONSTRAINT xxl_job_info_pkey PRIMARY KEY ( id );
ALTER TABLE xxl_job_lock ADD CONSTRAINT xxl_job_lock_pkey PRIMARY KEY ( lock_name );
ALTER TABLE xxl_job_log ADD CONSTRAINT xxl_job_log_pkey PRIMARY KEY ( id );
ALTER TABLE xxl_job_log_report ADD CONSTRAINT xxl_job_log_report_pkey PRIMARY KEY ( id );
ALTER TABLE xxl_job_logglue ADD CONSTRAINT xxl_job_logglue_pkey PRIMARY KEY ( id );
ALTER TABLE xxl_job_registry ADD CONSTRAINT xxl_job_registry_pkey PRIMARY KEY ( id );
ALTER TABLE xxl_job_user ADD CONSTRAINT xxl_job_user_pkey PRIMARY KEY ( id );
INSERT INTO xxl_job_user ( id, username, password, role, permission )
VALUES
( 1, 'admin', 'e10adc3949ba59abbe56e057f20f883e', 1, NULL );
INSERT INTO xxl_job_group ( id, app_name, title, address_type, address_list, update_time )
VALUES
( 1, 'xxl-job-executor', '执行器-测试组', 0, NULL, '2022-06-05 22:21:31' );
INSERT INTO xxl_job_lock ( lock_name )
VALUES
( 'schedule_lock' );3.1.6 sqlserver
CREATE TABLE xxl_job_info (
id int NOT NULL identity(1,1),
job_group int NOT NULL,
job_desc varchar(255) NOT NULL,
add_time datetime DEFAULT NULL,
update_time datetime DEFAULT NULL,
author varchar(64) DEFAULT NULL ,
alarm_email varchar(255) DEFAULT NULL ,
schedule_type varchar(50) NOT NULL DEFAULT 'NONE',
schedule_conf varchar(128) DEFAULT NULL ,
misfire_strategy varchar(50) NOT NULL DEFAULT 'DO_NOTHING' ,
executor_route_strategy varchar(50) DEFAULT NULL ,
executor_handler varchar(255) DEFAULT NULL ,
executor_param varchar(512) DEFAULT NULL ,
executor_block_strategy varchar(50) DEFAULT NULL ,
executor_timeout int NOT NULL DEFAULT '0',
executor_fail_retry_count int NOT NULL DEFAULT '0',
glue_type varchar(50) NOT NULL ,
glue_source varchar(512) ,
glue_remark varchar(128) DEFAULT NULL ,
glue_updatetime datetime DEFAULT NULL ,
child_jobid varchar(255) DEFAULT NULL ,
trigger_status smallint NOT NULL DEFAULT '0',
trigger_last_time bigint NOT NULL DEFAULT '0' ,
trigger_next_time bigint NOT NULL DEFAULT '0',
PRIMARY KEY (id)
);
CREATE TABLE xxl_job_log (
id bigint NOT NULL identity(1,1),
job_group int NOT NULL,
job_id int NOT NULL ,
executor_address varchar(255) DEFAULT NULL ,
executor_handler varchar(255) DEFAULT NULL,
executor_param varchar(512) DEFAULT NULL,
executor_sharding_param varchar(20) DEFAULT NULL,
executor_fail_retry_count int NOT NULL DEFAULT '0',
trigger_time datetime DEFAULT NULL,
trigger_code int NOT NULL,
trigger_msg varchar(512),
handle_time datetime DEFAULT NULL,
handle_code int NOT NULL ,
handle_msg varchar(512),
alarm_status smallint NOT NULL DEFAULT '0',
PRIMARY KEY (id)
);
CREATE NONCLUSTERED INDEX I_trigger_time ON xxl_job_log(trigger_time);
CREATE NONCLUSTERED INDEX I_handle_code ON xxl_job_log(handle_code);
CREATE TABLE xxl_job_log_report (
id int NOT NULL identity(1,1) PRIMARY KEY ,
trigger_day datetime DEFAULT NULL,
running_count int NOT NULL DEFAULT '0',
suc_count int NOT NULL DEFAULT '0',
fail_count int NOT NULL DEFAULT '0',
update_time datetime DEFAULT NULL,
constraint i_trigger_day unique(trigger_day)
);
CREATE TABLE xxl_job_logglue (
id int NOT NULL identity(1,1),
job_id int NOT NULL,
glue_type varchar(50) DEFAULT NULL,
glue_source varchar(512),
glue_remark varchar(128) NOT NULL,
add_time datetime DEFAULT NULL,
update_time datetime DEFAULT NULL,
PRIMARY KEY (id)
);
CREATE TABLE xxl_job_registry (
id int NOT NULL identity(1,1),
registry_group varchar(50) NOT NULL,
registry_key varchar(255) NOT NULL,
registry_value varchar(255) NOT NULL,
update_time datetime DEFAULT NULL,
PRIMARY KEY (id)
);
CREATE NONCLUSTERED INDEX i_g_k_v ON xxl_job_registry(registry_group, registry_key, registry_value);
CREATE TABLE xxl_job_group (
id int NOT NULL identity(1,1),
app_name varchar(64) NOT NULL,
title varchar(128) NOT NULL,
address_type smallint NOT NULL DEFAULT '0',
address_list varchar(512),
update_time datetime DEFAULT NULL,
PRIMARY KEY (id)
);
CREATE TABLE xxl_job_user (
id int NOT NULL identity(1,1),
username varchar(50) NOT NULL,
password varchar(50) NOT NULL,
role smallint NOT NULL,
permission varchar(255) DEFAULT NULL,
PRIMARY KEY (id),
constraint i_username unique(username)
);
CREATE TABLE xxl_job_lock (
lock_name varchar(50) NOT NULL,
PRIMARY KEY (lock_name)
);
INSERT INTO xxl_job_group(app_name, title, address_type, address_list, update_time) VALUES ('xxl-job-executor-sample', '示例执行器', 0, NULL, '2018-11-03 22:21:31' );
INSERT INTO xxl_job_info(job_group, job_desc, add_time, update_time, author, alarm_email, schedule_type, schedule_conf, misfire_strategy, executor_route_strategy, executor_handler, executor_param, executor_block_strategy, executor_timeout, executor_fail_retry_count, glue_type, glue_source, glue_remark, glue_updatetime, child_jobid) VALUES (1, '测试任务1', '2018-11-03 22:21:31', '2018-11-03 22:21:31', 'XXL', '', 'CRON', '0 0 0 * * ? *', 'DO_NOTHING', 'FIRST', 'demoJobHandler', '', 'SERIAL_EXECUTION', 0, 0, 'BEAN', '', 'GLUE代码初始化', '2018-11-03 22:21:31', '');
INSERT INTO xxl_job_user(username, password, role, permission) VALUES ('admin', 'e10adc3949ba59abbe56e057f20f883e', 1, NULL);
INSERT INTO xxl_job_lock ( lock_name) VALUES ( 'schedule_lock');3.2 JobLogReportHelper.java 文件修改
改这个文件的原因是因为每个数据对字段大小写的问题,主要是69行引起的:
Map<String, Object> triggerCountMap = XxlJobAdminConfig.getAdminConfig().getXxlJobLogDao().findLogReport(todayFrom, todayTo);
会调用下面的mapper代码
<select id="findLogReport" resultType="java.util.Map" >
SELECT
COUNT(handle_code) triggerDayCount,
SUM(CASE WHEN (trigger_code in (0, 200) and handle_code = 0) then 1 else 0 end) as triggerDayCountRunning,
SUM(CASE WHEN handle_code = 200 then 1 else 0 end) as triggerDayCountSuc
FROM xxl_job_log
WHERE trigger_time BETWEEN #{from} and #{to}
</select>
然后返回三个字段:triggerDayCount、triggerDayCountRunning、triggerDayCountSuc
但是在pg、kingbase里面返回的是全大写的TRIGGERDAYCOUNT、TRIGGERDAYCOUNTRUNNING、TRIGGERDAYCOUNTSUC
然而源码里面是直接写死的,因此改造了一番,直接复制下面的代码覆盖你本地的java文件即可
我的思路是:统一将key换成大写
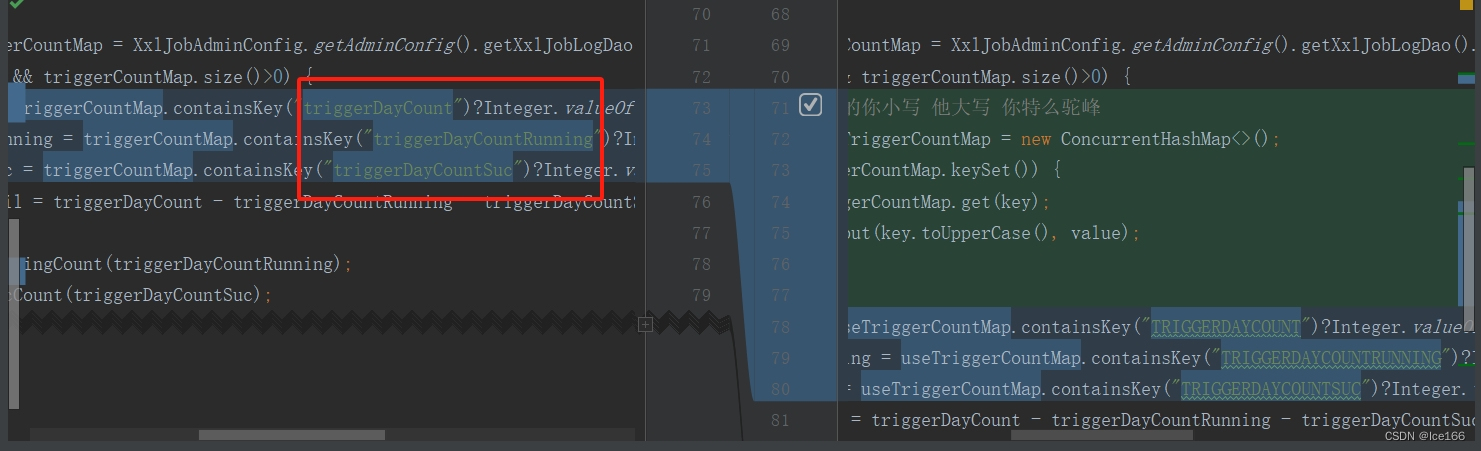
package com.xxl.job.admin.core.thread;
import com.xxl.job.admin.core.conf.XxlJobAdminConfig;
import com.xxl.job.admin.core.model.XxlJobLogReport;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.util.*;
import java.util.concurrent.ConcurrentHashMap;
import java.util.concurrent.TimeUnit;
/**
* job log report helper
*
* @author xuxueli 2019-11-22
*/
public class JobLogReportHelper {
private static Logger logger = LoggerFactory.getLogger(JobLogReportHelper.class);
private static JobLogReportHelper instance = new JobLogReportHelper();
public static JobLogReportHelper getInstance(){
return instance;
}
private Thread logrThread;
private volatile boolean toStop = false;
public void start(){
logrThread = new Thread(new Runnable() {
@Override
public void run() {
// last clean log time
long lastCleanLogTime = 0;
while (!toStop) {
// 1、log-report refresh: refresh log report in 3 days
try {
for (int i = 0; i < 3; i++) {
// today
Calendar itemDay = Calendar.getInstance();
itemDay.add(Calendar.DAY_OF_MONTH, -i);
itemDay.set(Calendar.HOUR_OF_DAY, 0);
itemDay.set(Calendar.MINUTE, 0);
itemDay.set(Calendar.SECOND, 0);
itemDay.set(Calendar.MILLISECOND, 0);
Date todayFrom = itemDay.getTime();
itemDay.set(Calendar.HOUR_OF_DAY, 23);
itemDay.set(Calendar.MINUTE, 59);
itemDay.set(Calendar.SECOND, 59);
itemDay.set(Calendar.MILLISECOND, 999);
Date todayTo = itemDay.getTime();
// refresh log-report every minute
XxlJobLogReport xxlJobLogReport = new XxlJobLogReport();
xxlJobLogReport.setTriggerDay(todayFrom);
xxlJobLogReport.setRunningCount(0);
xxlJobLogReport.setSucCount(0);
xxlJobLogReport.setFailCount(0);
Map<String, Object> triggerCountMap = XxlJobAdminConfig.getAdminConfig().getXxlJobLogDao().findLogReport(todayFrom, todayTo);
if (triggerCountMap!=null && triggerCountMap.size()>0) {
//key全部转大写 妈的 省的你小写 他大写 你特么驼峰
Map<String, Object> useTriggerCountMap = new ConcurrentHashMap<>();
for (String key : triggerCountMap.keySet()) {
Object value = triggerCountMap.get(key);
useTriggerCountMap.put(key.toUpperCase(), value);
}
int triggerDayCount = useTriggerCountMap.containsKey("TRIGGERDAYCOUNT")?Integer.valueOf(String.valueOf(useTriggerCountMap.get("TRIGGERDAYCOUNT"))):0;
int triggerDayCountRunning = useTriggerCountMap.containsKey("TRIGGERDAYCOUNTRUNNING")?Integer.valueOf(String.valueOf(useTriggerCountMap.get("TRIGGERDAYCOUNTRUNNING"))):0;
int triggerDayCountSuc = useTriggerCountMap.containsKey("TRIGGERDAYCOUNTSUC")?Integer.valueOf(String.valueOf(useTriggerCountMap.get("TRIGGERDAYCOUNTSUC"))):0;
int triggerDayCountFail = triggerDayCount - triggerDayCountRunning - triggerDayCountSuc;
xxlJobLogReport.setRunningCount(triggerDayCountRunning);
xxlJobLogReport.setSucCount(triggerDayCountSuc);
xxlJobLogReport.setFailCount(triggerDayCountFail);
}
// do refresh
int ret = XxlJobAdminConfig.getAdminConfig().getXxlJobLogReportDao().update(xxlJobLogReport);
if (ret < 1) {
XxlJobAdminConfig.getAdminConfig().getXxlJobLogReportDao().save(xxlJobLogReport);
}
}
} catch (Exception e) {
if (!toStop) {
logger.error(">>>>>>>>>>> xxl-job, job log report thread error:{}", e);
}
}
// 2、log-clean: switch open & once each day
if (XxlJobAdminConfig.getAdminConfig().getLogretentiondays()>0
&& System.currentTimeMillis() - lastCleanLogTime > 24*60*60*1000) {
// expire-time
Calendar expiredDay = Calendar.getInstance();
expiredDay.add(Calendar.DAY_OF_MONTH, -1 * XxlJobAdminConfig.getAdminConfig().getLogretentiondays());
expiredDay.set(Calendar.HOUR_OF_DAY, 0);
expiredDay.set(Calendar.MINUTE, 0);
expiredDay.set(Calendar.SECOND, 0);
expiredDay.set(Calendar.MILLISECOND, 0);
Date clearBeforeTime = expiredDay.getTime();
// clean expired log
List<Long> logIds = null;
do {
logIds = XxlJobAdminConfig.getAdminConfig().getXxlJobLogDao().findClearLogIds(0, 0, clearBeforeTime, 0, 1000);
if (logIds!=null && logIds.size()>0) {
XxlJobAdminConfig.getAdminConfig().getXxlJobLogDao().clearLog(logIds);
}
} while (logIds!=null && logIds.size()>0);
// update clean time
lastCleanLogTime = System.currentTimeMillis();
}
try {
TimeUnit.MINUTES.sleep(1);
} catch (Exception e) {
if (!toStop) {
logger.error(e.getMessage(), e);
}
}
}
logger.info(">>>>>>>>>>> xxl-job, job log report thread stop");
}
});
logrThread.setDaemon(true);
logrThread.setName("xxl-job, admin JobLogReportHelper");
logrThread.start();
}
public void toStop(){
toStop = true;
// interrupt and wait
logrThread.interrupt();
try {
logrThread.join();
} catch (InterruptedException e) {
logger.error(e.getMessage(), e);
}
}
}
3.3 mapper的修改
3.3.1 XxlJobGroupMapper.xml
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.xxl.job.admin.dao.XxlJobGroupDao">
<resultMap id="XxlJobGroup" type="com.xxl.job.admin.core.model.XxlJobGroup" >
<result column="id" property="id" />
<result column="app_name" property="appname" />
<result column="title" property="title" />
<result column="address_type" property="addressType" />
<result column="address_list" property="addressList" />
<result column="update_time" property="updateTime" />
</resultMap>
<sql id="Base_Column_List">
t.id,
t.app_name,
t.title,
t.address_type,
t.address_list,
t.update_time
</sql>
<select id="findAll" resultMap="XxlJobGroup">
SELECT <include refid="Base_Column_List" />
FROM xxl_job_group t
ORDER BY t.app_name, t.title, t.id ASC
</select>
<select id="findByAddressType" parameterType="java.lang.Integer" resultMap="XxlJobGroup">
SELECT <include refid="Base_Column_List" />
FROM xxl_job_group t
WHERE t.address_type = #{addressType}
ORDER BY t.app_name, t.title, t.id ASC
</select>
<sql databaseId="oracle" id='XXL_JOB_GROUP_ID'>XXL_JOB_GROUP_SEQ_ID.NEXTVAL</sql>
<insert id="save" databaseId="oracle" parameterType="com.xxl.job.admin.core.model.XxlJobGroup" useGeneratedKeys="true" keyProperty="id">
<selectKey keyProperty="id" resultType="int" order="BEFORE">
select <include refid="XXL_JOB_GROUP_ID" /> from dual
</selectKey>
INSERT INTO xxl_job_group (id, app_name, title, address_type, address_list, update_time)
values (#{id}, #{appname,jdbcType=VARCHAR}, #{title,jdbcType=VARCHAR}, #{addressType,jdbcType=NUMERIC}, #{addressList,jdbcType=VARCHAR}, #{updateTime,jdbcType=DATE} )
</insert>
<insert id="save" parameterType="com.xxl.job.admin.core.model.XxlJobGroup" useGeneratedKeys="true" keyProperty="id" >
INSERT INTO xxl_job_group ( app_name, title, address_type, address_list, update_time)
values ( #{appname}, #{title}, #{addressType}, #{addressList}, #{updateTime} )
</insert>
<update id="update" parameterType="com.xxl.job.admin.core.model.XxlJobGroup" >
UPDATE xxl_job_group
SET app_name = #{appname},
title = #{title},
address_type = #{addressType},
address_list = #{addressList},
update_time = #{updateTime}
WHERE id = #{id}
</update>
<update id="update" databaseId="oracle" parameterType="com.xxl.job.admin.core.model.XxlJobGroup" >
UPDATE xxl_job_group
SET app_name = #{appname,jdbcType=VARCHAR},
title = #{title,jdbcType=VARCHAR},
address_type = #{addressType,jdbcType=VARCHAR},
address_list = #{addressList,jdbcType=CLOB},
update_time = #{updateTime,jdbcType=DATE}
WHERE id = #{id}
</update>
<delete id="remove" parameterType="java.lang.Integer" >
DELETE FROM xxl_job_group
WHERE id = #{id}
</delete>
<select id="load" parameterType="java.lang.Integer" resultMap="XxlJobGroup">
SELECT <include refid="Base_Column_List" />
FROM xxl_job_group t
WHERE t.id = #{id}
</select>
<select id="pageList" parameterType="java.util.HashMap" resultMap="XxlJobGroup">
SELECT <include refid="Base_Column_List" />
FROM xxl_job_group t
<trim prefix="WHERE" prefixOverrides="AND | OR" >
<if test="appname != null and appname != ''">
AND t.app_name like CONCAT(CONCAT('%', #{appname}), '%')
</if>
<if test="title != null and title != ''">
AND t.title like CONCAT(CONCAT('%', #{title}), '%')
</if>
</trim>
ORDER BY t.app_name, t.title, t.id ASC
LIMIT #{offset}, #{pagesize}
</select>
<select id="pageList" databaseId="sqlserver" parameterType="java.util.HashMap" resultMap="XxlJobGroup">
SELECT <include refid="Base_Column_List" /> FROM
(
SELECT <include refid="Base_Column_List"/>
,row_number () OVER ( ORDER BY t.app_name, t.title, t.id ASC ) AS rownumber
FROM xxl_job_group AS t
<trim prefix="WHERE" prefixOverrides="AND | OR">
<if test="appname != null and appname != ''">
AND t.app_name like CONCAT(CONCAT('%', #{appname}), '%')
</if>
<if test="title != null and title != ''">
AND t.title like CONCAT(CONCAT('%', #{title}), '%')
</if>
</trim>
) AS t
WHERE t.rownumber <![CDATA[ > ]]> #{offset}
AND t.rownumber <![CDATA[ <= ]]> (#{offset} + #{pagesize})
</select>
<select id="pageList" databaseId="kingbase" parameterType="java.util.HashMap" resultMap="XxlJobGroup">
SELECT <include refid="Base_Column_List" />
FROM xxl_job_group t
<trim prefix="WHERE" prefixOverrides="AND | OR" >
<if test="appname != null and appname != ''">
AND t.app_name like CONCAT(CONCAT('%', #{appname}), '%')
</if>
<if test="title != null and title != ''">
AND t.title like CONCAT(CONCAT('%', #{title}), '%')
</if>
</trim>
ORDER BY t.app_name, t.title, t.id ASC
LIMIT #{pagesize} offset #{offset}
</select>
<select id="pageList" databaseId="pg" parameterType="java.util.HashMap" resultMap="XxlJobGroup">
SELECT <include refid="Base_Column_List" />
FROM xxl_job_group t
<trim prefix="WHERE" prefixOverrides="AND | OR" >
<if test="appname != null and appname != ''">
AND t.app_name like CONCAT(CONCAT('%', #{appname}), '%')
</if>
<if test="title != null and title != ''">
AND t.title like CONCAT(CONCAT('%', #{title}), '%')
</if>
</trim>
ORDER BY t.app_name, t.title, t.id ASC
LIMIT #{pagesize} offset #{offset}
</select>
<select id="pageList" databaseId="oracle" parameterType="java.util.HashMap" resultMap="XxlJobGroup">
SELECT <include refid="Base_Column_List" />
FROM (
SELECT t.*, ROWNUM AS rnum
FROM xxl_job_group t
WHERE 1 = 1
<if test="appname != null and appname != ''">
AND t.app_name like CONCAT(CONCAT('%', #{appname}), '%')
</if>
<if test="title != null and title != ''">
AND t.title like CONCAT(CONCAT('%', #{title}), '%')
</if>
ORDER BY t.app_name, t.title, t.id ASC
) t
WHERE rnum <![CDATA[ > ]]> #{offset} AND rnum <![CDATA[ <= ]]> (#{offset} + #{pagesize})
</select>
<!--<select id="pageList" databaseId="dm" parameterType="java.util.HashMap" resultMap="XxlJobGroup">-->
<!--SELECT <include refid="Base_Column_List" />, rownum-->
<!--FROM xxl_job_group t-->
<!--<trim prefix="WHERE" prefixOverrides="AND | OR" >-->
<!--<if test="appname != null and appname != ''">-->
<!--AND t.app_name like CONCAT(CONCAT('%', #{appname}), '%')-->
<!--</if>-->
<!--<if test="title != null and title != ''">-->
<!--AND t.title like CONCAT(CONCAT('%', #{title}), '%')-->
<!--</if>-->
<!--AND rownum <![CDATA[ > ]]> #{offset} AND rownum <![CDATA[ < ]]> (#{offset} + #{pagesize} + 1)-->
<!--</trim>-->
<!--ORDER BY t.app_name, t.title, t.id ASC-->
<!--</select>-->
<select id="pageListCount" parameterType="java.util.HashMap" resultType="int">
SELECT count(1)
FROM xxl_job_group t
<trim prefix="WHERE" prefixOverrides="AND | OR" >
<if test="appname != null and appname != ''">
AND t.app_name like CONCAT(CONCAT('%', #{appname}), '%')
</if>
<if test="title != null and title != ''">
AND t.title like CONCAT(CONCAT('%', #{title}), '%')
</if>
</trim>
</select>
</mapper>3.3.2 XxlJobInfoMapper.xml
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.xxl.job.admin.dao.XxlJobInfoDao">
<resultMap id="XxlJobInfo" type="com.xxl.job.admin.core.model.XxlJobInfo" >
<result column="id" property="id" />
<result column="job_group" property="jobGroup" />
<result column="job_desc" property="jobDesc" />
<result column="add_time" property="addTime" />
<result column="update_time" property="updateTime" />
<result column="author" property="author" />
<result column="alarm_email" property="alarmEmail" />
<result column="schedule_type" property="scheduleType" />
<result column="schedule_conf" property="scheduleConf" />
<result column="misfire_strategy" property="misfireStrategy" />
<result column="executor_route_strategy" property="executorRouteStrategy" />
<result column="executor_handler" property="executorHandler" />
<result column="executor_param" property="executorParam" />
<result column="executor_block_strategy" property="executorBlockStrategy" />
<result column="executor_timeout" property="executorTimeout" />
<result column="executor_fail_retry_count" property="executorFailRetryCount" />
<result column="glue_type" property="glueType" />
<result column="glue_source" property="glueSource" />
<result column="glue_remark" property="glueRemark" />
<result column="glue_updatetime" property="glueUpdatetime" />
<result column="child_jobid" property="childJobId" />
<result column="trigger_status" property="triggerStatus" />
<result column="trigger_last_time" property="triggerLastTime" />
<result column="trigger_next_time" property="triggerNextTime" />
</resultMap>
<sql id="Base_Column_List">
t.id,
t.job_group,
t.job_desc,
t.add_time,
t.update_time,
t.author,
t.alarm_email,
t.schedule_type,
t.schedule_conf,
t.misfire_strategy,
t.executor_route_strategy,
t.executor_handler,
t.executor_param,
t.executor_block_strategy,
t.executor_timeout,
t.executor_fail_retry_count,
t.glue_type,
t.glue_source,
t.glue_remark,
t.glue_updatetime,
t.child_jobid,
t.trigger_status,
t.trigger_last_time,
t.trigger_next_time
</sql>
<select id="pageList" parameterType="java.util.HashMap" resultMap="XxlJobInfo">
SELECT <include refid="Base_Column_List" />
FROM xxl_job_info t
<trim prefix="WHERE" prefixOverrides="AND | OR" >
<if test="jobGroup gt 0">
AND t.job_group = #{jobGroup}
</if>
<if test="triggerStatus gte 0">
AND t.trigger_status = #{triggerStatus}
</if>
<if test="jobDesc != null and jobDesc != ''">
AND t.job_desc like CONCAT(CONCAT('%', #{jobDesc}), '%')
</if>
<if test="executorHandler != null and executorHandler != ''">
AND t.executor_handler like CONCAT(CONCAT('%', #{executorHandler}), '%')
</if>
<if test="author != null and author != ''">
AND t.author like CONCAT(CONCAT('%', #{author}), '%')
</if>
</trim>
ORDER BY id DESC
LIMIT #{offset}, #{pagesize}
</select>
<select id="pageList" databaseId="sqlserver" parameterType="java.util.HashMap" resultMap="XxlJobInfo">
SELECT <include refid="Base_Column_List" />
FROM (SELECT row_number () OVER ( ORDER BY id DESC ) AS rownumber ,
<include refid="Base_Column_List"/>FROM xxl_job_info AS t
<trim prefix="WHERE" prefixOverrides="AND | OR" >
<if
test="jobGroup gt 0">AND t.job_group = #{jobGroup}
</if>
<if test="triggerStatus gte 0">
AND t.trigger_status = #{triggerStatus}
</if>
<if test="jobDesc != null and jobDesc != ''">
AND t.job_desc like CONCAT(CONCAT('%', #{jobDesc}), '%')
</if>
<if test="executorHandler != null and executorHandler != ''">
AND t.executor_handler like CONCAT(CONCAT('%', #{executorHandler}), '%')
</if>
<if test="author != null and author != ''">
AND t.author like CONCAT(CONCAT('%', #{author}), '%')
</if>
</trim>) AS t
WHERE t.rownumber <![CDATA[ > ]]> #{offset}
AND t.rownumber <![CDATA[ <= ]]> (#{offset} + #{pagesize})
</select>
<select id="pageList" databaseId="kingbase" parameterType="java.util.HashMap" resultMap="XxlJobInfo">
SELECT <include refid="Base_Column_List" />
FROM xxl_job_info t
<trim prefix="WHERE" prefixOverrides="AND | OR" >
<if test="jobGroup gt 0">
AND t.job_group = #{jobGroup}
</if>
<if test="triggerStatus gte 0">
AND t.trigger_status = #{triggerStatus}
</if>
<if test="jobDesc != null and jobDesc != ''">
AND t.job_desc like CONCAT(CONCAT('%', #{jobDesc}), '%')
</if>
<if test="executorHandler != null and executorHandler != ''">
AND t.executor_handler like CONCAT(CONCAT('%', #{executorHandler}), '%')
</if>
<if test="author != null and author != ''">
AND t.author like CONCAT(CONCAT('%', #{author}), '%')
</if>
</trim>
ORDER BY id DESC
LIMIT #{pagesize} offset #{offset}
</select>
<select id="pageList" databaseId="pg" parameterType="java.util.HashMap" resultMap="XxlJobInfo">
SELECT <include refid="Base_Column_List" />
FROM xxl_job_info t
<trim prefix="WHERE" prefixOverrides="AND | OR" >
<if test="jobGroup gt 0">
AND t.job_group = #{jobGroup}
</if>
<if test="triggerStatus gte 0">
AND t.trigger_status = #{triggerStatus}
</if>
<if test="jobDesc != null and jobDesc != ''">
AND t.job_desc like CONCAT(CONCAT('%', #{jobDesc}), '%')
</if>
<if test="executorHandler != null and executorHandler != ''">
AND t.executor_handler like CONCAT(CONCAT('%', #{executorHandler}), '%')
</if>
<if test="author != null and author != ''">
AND t.author like CONCAT(CONCAT('%', #{author}), '%')
</if>
</trim>
ORDER BY id DESC
LIMIT #{pagesize} offset #{offset}
</select>
<select id="pageList" databaseId="oracle" parameterType="java.util.HashMap" resultMap="XxlJobInfo">
SELECT <include refid="Base_Column_List" />
FROM (
SELECT t.*, ROWNUM AS rnum
FROM xxl_job_info t
WHERE 1 = 1
<if test="jobGroup gt 0">
AND t.job_group = #{jobGroup}
</if>
<if test="triggerStatus gte 0">
AND t.trigger_status = #{triggerStatus}
</if>
<if test="jobDesc != null and jobDesc != ''">
AND t.job_desc like CONCAT(CONCAT('%', #{jobDesc}), '%')
</if>
<if test="executorHandler != null and executorHandler != ''">
AND t.executor_handler like CONCAT(CONCAT('%', #{executorHandler}), '%')
</if>
<if test="author != null and author != ''">
AND t.author like CONCAT(CONCAT('%', #{author}), '%')
</if>
ORDER BY id DESC
) t
WHERE rnum <![CDATA[ > ]]> #{offset} AND rnum <![CDATA[ <= ]]> (#{offset} + #{pagesize})
</select>
<!--<select id="pageList" databaseId="dm" parameterType="java.util.HashMap" resultMap="XxlJobInfo">-->
<!--SELECT <include refid="Base_Column_List" />, rownum-->
<!--FROM xxl_job_info t-->
<!--<trim prefix="WHERE" prefixOverrides="AND | OR" >-->
<!--<if test="jobGroup gt 0">-->
<!--AND t.job_group = #{jobGroup}-->
<!--</if>-->
<!--<if test="triggerStatus gte 0">-->
<!--AND t.trigger_status = #{triggerStatus}-->
<!--</if>-->
<!--<if test="jobDesc != null and jobDesc != ''">-->
<!--AND t.job_desc like CONCAT(CONCAT('%', #{jobDesc}), '%')-->
<!--</if>-->
<!--<if test="executorHandler != null and executorHandler != ''">-->
<!--AND t.executor_handler like CONCAT(CONCAT('%', #{executorHandler}), '%')-->
<!--</if>-->
<!--<if test="author != null and author != ''">-->
<!--AND t.author like CONCAT(CONCAT('%', #{author}), '%')-->
<!--</if>-->
<!--AND rownum <![CDATA[ > ]]> #{offset} AND rownum <![CDATA[ < ]]> (#{offset} + #{pagesize} + 1)-->
<!--</trim>-->
<!--ORDER BY id DESC-->
<!--LIMIT #{offset}, #{pagesize}-->
<!--</select>-->
<select id="pageListCount" parameterType="java.util.HashMap" resultType="int">
SELECT count(1)
FROM xxl_job_info t
<trim prefix="WHERE" prefixOverrides="AND | OR" >
<if test="jobGroup gt 0">
AND t.job_group = #{jobGroup}
</if>
<if test="triggerStatus gte 0">
AND t.trigger_status = #{triggerStatus}
</if>
<if test="jobDesc != null and jobDesc != ''">
AND t.job_desc like CONCAT(CONCAT('%', #{jobDesc}), '%')
</if>
<if test="executorHandler != null and executorHandler != ''">
AND t.executor_handler like CONCAT(CONCAT('%', #{executorHandler}), '%')
</if>
<if test="author != null and author != ''">
AND t.author like CONCAT(CONCAT('%', #{author}), '%')
</if>
</trim>
</select>
<insert id="save" parameterType="com.xxl.job.admin.core.model.XxlJobInfo" useGeneratedKeys="true" keyProperty="id" >
INSERT INTO xxl_job_info (
job_group,
job_desc,
add_time,
update_time,
author,
alarm_email,
schedule_type,
schedule_conf,
misfire_strategy,
executor_route_strategy,
executor_handler,
executor_param,
executor_block_strategy,
executor_timeout,
executor_fail_retry_count,
glue_type,
glue_source,
glue_remark,
glue_updatetime,
child_jobid,
trigger_status,
trigger_last_time,
trigger_next_time
) VALUES (
#{jobGroup},
#{jobDesc},
#{addTime},
#{updateTime},
#{author},
#{alarmEmail},
#{scheduleType},
#{scheduleConf},
#{misfireStrategy},
#{executorRouteStrategy},
#{executorHandler},
#{executorParam},
#{executorBlockStrategy},
#{executorTimeout},
#{executorFailRetryCount},
#{glueType},
#{glueSource},
#{glueRemark},
#{glueUpdatetime},
#{childJobId},
#{triggerStatus},
#{triggerLastTime},
#{triggerNextTime}
)
<!--<selectKey resultType="java.lang.Integer" order="AFTER" keyProperty="id">
SELECT LAST_INSERT_ID()
/*SELECT @@IDENTITY AS id*/
</selectKey>-->
</insert>
<sql databaseId="oracle" id='XXL_JOB_INFO_ID'>XXL_JOB_INFO_SEQ_ID.NEXTVAL</sql>
<insert id="save" databaseId="oracle" parameterType="com.xxl.job.admin.core.model.XxlJobInfo" useGeneratedKeys="true" keyProperty="id" >
<selectKey keyProperty="id" resultType="int" order="BEFORE">
select <include refid="XXL_JOB_INFO_ID" /> from dual
</selectKey>
INSERT INTO xxl_job_info (
id,
job_group,
job_desc,
add_time,
update_time,
author,
alarm_email,
schedule_type,
schedule_conf,
misfire_strategy,
executor_route_strategy,
executor_handler,
executor_param,
executor_block_strategy,
executor_timeout,
executor_fail_retry_count,
glue_type,
glue_source,
glue_remark,
glue_updatetime,
child_jobid,
trigger_status,
trigger_last_time,
trigger_next_time
) VALUES (
#{id},
#{jobGroup},
#{jobDesc},
#{addTime},
#{updateTime},
#{author},
#{alarmEmail},
#{scheduleType},
#{scheduleConf},
#{misfireStrategy},
#{executorRouteStrategy},
#{executorHandler},
#{executorParam},
#{executorBlockStrategy},
#{executorTimeout},
#{executorFailRetryCount},
#{glueType},
#{glueSource,jdbcType=CLOB},
#{glueRemark},
#{glueUpdatetime},
#{childJobId},
#{triggerStatus},
#{triggerLastTime},
#{triggerNextTime}
)
<!--<selectKey resultType="java.lang.Integer" order="AFTER" keyProperty="id">
SELECT LAST_INSERT_ID()
/*SELECT @@IDENTITY AS id*/
</selectKey>-->
</insert>
<select id="loadById" parameterType="java.util.HashMap" resultMap="XxlJobInfo">
SELECT <include refid="Base_Column_List" />
FROM xxl_job_info t
WHERE t.id = #{id}
</select>
<update id="update" parameterType="com.xxl.job.admin.core.model.XxlJobInfo" >
UPDATE xxl_job_info
SET
job_group = #{jobGroup},
job_desc = #{jobDesc},
update_time = #{updateTime},
author = #{author},
alarm_email = #{alarmEmail},
schedule_type = #{scheduleType},
schedule_conf = #{scheduleConf},
misfire_strategy = #{misfireStrategy},
executor_route_strategy = #{executorRouteStrategy},
executor_handler = #{executorHandler},
executor_param = #{executorParam},
executor_block_strategy = #{executorBlockStrategy},
executor_timeout = ${executorTimeout},
executor_fail_retry_count = ${executorFailRetryCount},
glue_type = #{glueType},
glue_source = #{glueSource},
glue_remark = #{glueRemark},
glue_updatetime = #{glueUpdatetime},
child_jobid = #{childJobId},
trigger_status = #{triggerStatus},
trigger_last_time = #{triggerLastTime},
trigger_next_time = #{triggerNextTime}
WHERE id = #{id}
</update>
<update id="update" databaseId="oracle" parameterType="com.xxl.job.admin.core.model.XxlJobInfo" >
UPDATE xxl_job_info
SET
job_group = #{jobGroup},
job_desc = #{jobDesc,jdbcType=VARCHAR},
update_time = #{updateTime,jdbcType=DATE},
author = #{author,jdbcType=VARCHAR},
alarm_email = #{alarmEmail,jdbcType=VARCHAR},
schedule_type = #{scheduleType,jdbcType=VARCHAR},
schedule_conf = #{scheduleConf,jdbcType=VARCHAR},
misfire_strategy = #{misfireStrategy,jdbcType=VARCHAR},
executor_route_strategy = #{executorRouteStrategy,jdbcType=VARCHAR},
executor_handler = #{executorHandler,jdbcType=VARCHAR},
executor_param = #{executorParam,jdbcType=VARCHAR},
executor_block_strategy = #{executorBlockStrategy,jdbcType=VARCHAR},
executor_timeout = ${executorTimeout},
executor_fail_retry_count = ${executorFailRetryCount},
glue_type = #{glueType,jdbcType=VARCHAR},
glue_source = #{glueSource,jdbcType=CLOB},
glue_remark = #{glueRemark,jdbcType=VARCHAR},
glue_updatetime = #{glueUpdatetime,jdbcType=DATE},
child_jobid = #{childJobId,jdbcType=VARCHAR},
trigger_status = #{triggerStatus,jdbcType=VARCHAR},
trigger_last_time = #{triggerLastTime},
trigger_next_time = #{triggerNextTime}
WHERE id = #{id}
</update>
<delete id="delete" parameterType="java.util.HashMap">
DELETE
FROM xxl_job_info
WHERE id = #{id}
</delete>
<select id="getJobsByGroup" parameterType="java.util.HashMap" resultMap="XxlJobInfo">
SELECT <include refid="Base_Column_List" />
FROM xxl_job_info t
WHERE t.job_group = #{jobGroup}
</select>
<select id="findAllCount" resultType="int">
SELECT count(1)
FROM xxl_job_info
</select>
<select id="scheduleJobQuery" parameterType="java.util.HashMap" resultMap="XxlJobInfo">
SELECT <include refid="Base_Column_List" />
FROM xxl_job_info t
WHERE t.trigger_status = 1
and t.trigger_next_time <![CDATA[ <= ]]> #{maxNextTime}
ORDER BY id ASC
LIMIT #{pagesize}
</select>
<select id="scheduleJobQuery" databaseId="sqlserver" parameterType="java.util.HashMap" resultMap="XxlJobInfo">
SELECT top (#{pagesize}) <include refid="Base_Column_List" />
FROM xxl_job_info AS t
WHERE t.trigger_status = 1
and t.trigger_next_time <![CDATA[ <= ]]> #{maxNextTime}
ORDER BY id ASC
</select>
<select id="scheduleJobQuery" databaseId="oracle" parameterType="java.util.HashMap" resultMap="XxlJobInfo">
SELECT <include refid="Base_Column_List" />
FROM (
SELECT t.*, ROWNUM AS rnum
FROM xxl_job_info t
WHERE t.trigger_status = 1
AND t.trigger_next_time <![CDATA[ <= ]]> #{maxNextTime}
ORDER BY id ASC
) t
WHERE rnum <![CDATA[ <= ]]> #{pagesize}
</select>
<update id="scheduleUpdate" parameterType="com.xxl.job.admin.core.model.XxlJobInfo" >
UPDATE xxl_job_info
SET
trigger_last_time = #{triggerLastTime},
trigger_next_time = #{triggerNextTime},
trigger_status = #{triggerStatus}
WHERE id = #{id}
</update>
</mapper>3.3.3 XxlJobLogGlueMapper.xml
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.xxl.job.admin.dao.XxlJobLogGlueDao">
<resultMap id="XxlJobLogGlue" type="com.xxl.job.admin.core.model.XxlJobLogGlue" >
<result column="id" property="id" />
<result column="job_id" property="jobId" />
<result column="glue_type" property="glueType" />
<result column="glue_source" property="glueSource" />
<result column="glue_remark" property="glueRemark" />
<result column="add_time" property="addTime" />
<result column="update_time" property="updateTime" />
</resultMap>
<sql id="Base_Column_List">
t.id,
t.job_id,
t.glue_type,
t.glue_source,
t.glue_remark,
t.add_time,
t.update_time
</sql>
<insert id="save" parameterType="com.xxl.job.admin.core.model.XxlJobLogGlue" useGeneratedKeys="true" keyProperty="id" >
INSERT INTO xxl_job_logglue (
job_id,
glue_type,
glue_source,
glue_remark,
add_time,
update_time
) VALUES (
#{jobId},
#{glueType},
#{glueSource},
#{glueRemark},
#{addTime},
#{updateTime}
)
<!--<selectKey resultType="java.lang.Integer" order="AFTER" keyProperty="id">
SELECT LAST_INSERT_ID()
</selectKey>-->
</insert>
<sql databaseId="oracle" id='XXL_JOB_LOGGLUE_ID'>XXL_JOB_LOGGLUE_SEQ_ID.NEXTVAL</sql>
<insert id="save" databaseId="oracle" parameterType="com.xxl.job.admin.core.model.XxlJobLogGlue" useGeneratedKeys="true" keyProperty="id" >
<selectKey keyProperty="id" resultType="int" order="BEFORE">
select <include refid="XXL_JOB_LOGGLUE_ID" /> from dual
</selectKey>
INSERT INTO xxl_job_logglue (
id,
job_id,
glue_type,
glue_source,
glue_remark,
add_time,
update_time
) VALUES (
#{id},
#{jobId},
#{glueType,jdbcType=VARCHAR},
#{glueSource,jdbcType=CLOB},
#{glueRemark,jdbcType=VARCHAR},
#{addTime,jdbcType=DATE},
#{updateTime,jdbcType=DATE}
)
<!--<selectKey resultType="java.lang.Integer" order="AFTER" keyProperty="id">
SELECT LAST_INSERT_ID()
</selectKey>-->
</insert>
<select id="findByJobId" parameterType="java.lang.Integer" resultMap="XxlJobLogGlue">
SELECT <include refid="Base_Column_List" />
FROM xxl_job_logglue t
WHERE t.job_id = #{jobId}
ORDER BY id DESC
</select>
<delete id="removeOld" >
DELETE FROM xxl_job_logglue
WHERE id NOT in(
SELECT id FROM(
SELECT id FROM xxl_job_logglue
WHERE job_id = #{jobId}
ORDER BY update_time desc
LIMIT 0, #{limit}
) t1
) AND job_id = #{jobId}
</delete>
<delete id="removeOld" databaseId="sqlserver">
DELETE FROM xxl_job_logglue
WHERE id NOT in(
SELECT id FROM(
SELECT top(#{limit}) id FROM xxl_job_logglue
WHERE job_id = #{jobId}
ORDER BY update_time desc
) t1
) AND job_id = #{jobId}
</delete>
<delete id="removeOld" databaseId="kingbase">
DELETE FROM xxl_job_logglue
WHERE id NOT in(
SELECT id FROM(
SELECT id FROM xxl_job_logglue
WHERE job_id = #{jobId}
ORDER BY update_time desc
LIMIT #{limit}
) t1
) AND job_id = #{jobId}
</delete>
<delete id="removeOld" databaseId="pg">
DELETE FROM xxl_job_logglue
WHERE id NOT in(
SELECT id FROM(
SELECT id FROM xxl_job_logglue
WHERE job_id = #{jobId}
ORDER BY update_time desc
LIMIT #{limit}
) t1
) AND job_id = #{jobId}
</delete>
<delete id="removeOld" databaseId="oracle">
DELETE FROM xxl_job_logglue
WHERE id NOT in(
SELECT id FROM(
SELECT id, rownum FROM xxl_job_logglue
WHERE job_id = #{jobId} AND rownum <![CDATA[ < ]]> (#{limit} + 1)
ORDER BY update_time desc
) t1
) AND job_id = #{jobId}
</delete>
<!--<delete id="removeOld" databaseId="dm">-->
<!--DELETE FROM xxl_job_logglue-->
<!--WHERE id NOT in(-->
<!--SELECT id FROM(-->
<!--SELECT id, rownum FROM xxl_job_logglue-->
<!--WHERE job_id = #{jobId} AND rownum <![CDATA[ < ]]> (#{limit} + 1)-->
<!--ORDER BY update_time desc-->
<!--) t1-->
<!--) AND job_id = #{jobId}-->
<!--</delete>-->
<delete id="deleteByJobId" parameterType="java.lang.Integer" >
DELETE FROM xxl_job_logglue
WHERE job_id = #{jobId}
</delete>
</mapper>3.3.4 XxlJobLogMapper.xml
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.xxl.job.admin.dao.XxlJobLogDao">
<resultMap id="XxlJobLog" type="com.xxl.job.admin.core.model.XxlJobLog" >
<result column="id" property="id" />
<result column="job_group" property="jobGroup" />
<result column="job_id" property="jobId" />
<result column="executor_address" property="executorAddress" />
<result column="executor_handler" property="executorHandler" />
<result column="executor_param" property="executorParam" />
<result column="executor_sharding_param" property="executorShardingParam" />
<result column="executor_fail_retry_count" property="executorFailRetryCount" />
<result column="trigger_time" property="triggerTime" />
<result column="trigger_code" property="triggerCode" />
<result column="trigger_msg" property="triggerMsg" />
<result column="handle_time" property="handleTime" />
<result column="handle_code" property="handleCode" />
<result column="handle_msg" property="handleMsg" />
<result column="alarm_status" property="alarmStatus" />
</resultMap>
<sql id="Base_Column_List">
t.id,
t.job_group,
t.job_id,
t.executor_address,
t.executor_handler,
t.executor_param,
t.executor_sharding_param,
t.executor_fail_retry_count,
t.trigger_time,
t.trigger_code,
t.trigger_msg,
t.handle_time,
t.handle_code,
t.handle_msg,
t.alarm_status
</sql>
<select id="pageList" resultMap="XxlJobLog">
SELECT <include refid="Base_Column_List" />
FROM xxl_job_log t
<trim prefix="WHERE" prefixOverrides="AND | OR" >
<if test="jobId==0 and jobGroup gt 0">
AND t.job_group = #{jobGroup}
</if>
<if test="jobId gt 0">
AND t.job_id = #{jobId}
</if>
<if test="triggerTimeStart != null">
AND t.trigger_time <![CDATA[ >= ]]> #{triggerTimeStart}
</if>
<if test="triggerTimeEnd != null">
AND t.trigger_time <![CDATA[ <= ]]> #{triggerTimeEnd}
</if>
<if test="logStatus == 1" >
AND t.handle_code = 200
</if>
<if test="logStatus == 2" >
AND (
t.trigger_code NOT IN (0, 200) OR
t.handle_code NOT IN (0, 200)
)
</if>
<if test="logStatus == 3" >
AND t.trigger_code = 200
AND t.handle_code = 0
</if>
</trim>
ORDER BY t.trigger_time DESC
LIMIT #{offset}, #{pagesize}
</select>
<select id="pageList" databaseId="sqlserver" resultMap="XxlJobLog">
SELECT <include refid="Base_Column_List" />
from (
SELECT row_number () OVER ( ORDER BY t.trigger_time DESC ) AS rownumber,
<include refid="Base_Column_List" />
FROM xxl_job_log AS t
<trim prefix="WHERE" prefixOverrides="AND | OR" >
<if test="jobId==0 and jobGroup gt 0">
AND t.job_group = #{jobGroup}
</if>
<if test="jobId gt 0">
AND t.job_id = #{jobId}
</if>
<if test="triggerTimeStart != null">
AND t.trigger_time <![CDATA[ >= ]]> #{triggerTimeStart}
</if>
<if test="triggerTimeEnd != null">
AND t.trigger_time <![CDATA[ <= ]]> #{triggerTimeEnd}
</if>
<if test="logStatus == 1" >
AND t.handle_code = 200
</if>
<if test="logStatus == 2" >
AND (
t.trigger_code NOT IN (0, 200) OR
t.handle_code NOT IN (0, 200)
)
</if>
<if test="logStatus == 3" >
AND t.trigger_code = 200
AND t.handle_code = 0
</if>
</trim>
) AS t
WHERE t.rownumber <![CDATA[ > ]]> #{offset}
AND t.rownumber <![CDATA[ <= ]]> (#{offset} + #{pagesize})
</select>
<select id="pageList" resultMap="XxlJobLog" databaseId="kingbase">
SELECT <include refid="Base_Column_List" />
FROM xxl_job_log t
<trim prefix="WHERE" prefixOverrides="AND | OR" >
<if test="jobId==0 and jobGroup gt 0">
AND t.job_group = #{jobGroup}
</if>
<if test="jobId gt 0">
AND t.job_id = #{jobId}
</if>
<if test="triggerTimeStart != null">
AND t.trigger_time <![CDATA[ >= ]]> #{triggerTimeStart}
</if>
<if test="triggerTimeEnd != null">
AND t.trigger_time <![CDATA[ <= ]]> #{triggerTimeEnd}
</if>
<if test="logStatus == 1" >
AND t.handle_code = 200
</if>
<if test="logStatus == 2" >
AND (
t.trigger_code NOT IN (0, 200) OR
t.handle_code NOT IN (0, 200)
)
</if>
<if test="logStatus == 3" >
AND t.trigger_code = 200
AND t.handle_code = 0
</if>
</trim>
ORDER BY t.trigger_time DESC
LIMIT #{pagesize} offset #{offset}
</select>
<select id="pageList" databaseId="pg" resultMap="XxlJobLog">
SELECT <include refid="Base_Column_List" />
FROM xxl_job_log t
<trim prefix="WHERE" prefixOverrides="AND | OR" >
<if test="jobId==0 and jobGroup gt 0">
AND t.job_group = #{jobGroup}
</if>
<if test="jobId gt 0">
AND t.job_id = #{jobId}
</if>
<if test="triggerTimeStart != null">
AND t.trigger_time <![CDATA[ >= ]]> #{triggerTimeStart}
</if>
<if test="triggerTimeEnd != null">
AND t.trigger_time <![CDATA[ <= ]]> #{triggerTimeEnd}
</if>
<if test="logStatus == 1" >
AND t.handle_code = 200
</if>
<if test="logStatus == 2" >
AND (
t.trigger_code NOT IN (0, 200) OR
t.handle_code NOT IN (0, 200)
)
</if>
<if test="logStatus == 3" >
AND t.trigger_code = 200
AND t.handle_code = 0
</if>
</trim>
ORDER BY t.trigger_time DESC
LIMIT #{pagesize} offset #{offset}
</select>
<select id="pageList" databaseId="oracle" resultMap="XxlJobLog">
SELECT <include refid="Base_Column_List" />
FROM (
SELECT t.*, ROWNUM AS rnum
FROM xxl_job_log t
WHERE 1 = 1
<if test="jobId==0 and jobGroup gt 0">
AND t.job_group = #{jobGroup}
</if>
<if test="jobId gt 0">
AND t.job_id = #{jobId}
</if>
<if test="triggerTimeStart != null">
AND t.trigger_time <![CDATA[ >= ]]> #{triggerTimeStart}
</if>
<if test="triggerTimeEnd != null">
AND t.trigger_time <![CDATA[ <= ]]> #{triggerTimeEnd}
</if>
<if test="logStatus == 1" >
AND t.handle_code = 200
</if>
<if test="logStatus == 2" >
AND (
t.trigger_code NOT IN (0, 200) OR
t.handle_code NOT IN (0, 200)
)
</if>
<if test="logStatus == 3" >
AND t.trigger_code = 200
AND t.handle_code = 0
</if>
ORDER BY t.trigger_time DESC
) t
WHERE rnum <![CDATA[ > ]]> #{offset} AND rnum <![CDATA[ <= ]]> (#{offset} + #{pagesize})
</select>
<!--<select id="pageList" databaseId="dm" resultMap="XxlJobLog">-->
<!--SELECT <include refid="Base_Column_List" />, rownum-->
<!--FROM xxl_job_log t-->
<!--<trim prefix="WHERE" prefixOverrides="AND | OR" >-->
<!--<if test="jobId==0 and jobGroup gt 0">-->
<!--AND t.job_group = #{jobGroup}-->
<!--</if>-->
<!--<if test="jobId gt 0">-->
<!--AND t.job_id = #{jobId}-->
<!--</if>-->
<!--<if test="triggerTimeStart != null">-->
<!--AND t.trigger_time <![CDATA[ >= ]]> #{triggerTimeStart}-->
<!--</if>-->
<!--<if test="triggerTimeEnd != null">-->
<!--AND t.trigger_time <![CDATA[ <= ]]> #{triggerTimeEnd}-->
<!--</if>-->
<!--<if test="logStatus == 1" >-->
<!--AND t.handle_code = 200-->
<!--</if>-->
<!--<if test="logStatus == 2" >-->
<!--AND (-->
<!--t.trigger_code NOT IN (0, 200) OR-->
<!--t.handle_code NOT IN (0, 200)-->
<!--)-->
<!--</if>-->
<!--<if test="logStatus == 3" >-->
<!--AND t.trigger_code = 200-->
<!--AND t.handle_code = 0-->
<!--</if>-->
<!--AND rownum <![CDATA[ > ]]> #{offset} AND rownum <![CDATA[ < ]]> (#{offset} + #{pagesize} + 1)-->
<!--</trim>-->
<!--ORDER BY t.trigger_time DESC-->
<!--</select>-->
<select id="pageListCount" resultType="int">
SELECT count(1)
FROM xxl_job_log t
<trim prefix="WHERE" prefixOverrides="AND | OR" >
<if test="jobId==0 and jobGroup gt 0">
AND t.job_group = #{jobGroup}
</if>
<if test="jobId gt 0">
AND t.job_id = #{jobId}
</if>
<if test="triggerTimeStart != null">
AND t.trigger_time <![CDATA[ >= ]]> #{triggerTimeStart}
</if>
<if test="triggerTimeEnd != null">
AND t.trigger_time <![CDATA[ <= ]]> #{triggerTimeEnd}
</if>
<if test="logStatus == 1" >
AND t.handle_code = 200
</if>
<if test="logStatus == 2" >
AND (
t.trigger_code NOT IN (0, 200) OR
t.handle_code NOT IN (0, 200)
)
</if>
<if test="logStatus == 3" >
AND t.trigger_code = 200
AND t.handle_code = 0
</if>
</trim>
</select>
<select id="load" parameterType="java.lang.Long" resultMap="XxlJobLog">
SELECT <include refid="Base_Column_List" />
FROM xxl_job_log t
WHERE t.id = #{id}
</select>
<sql databaseId="oracle" id='XXL_JOB_LOG_ID'>XXL_JOB_LOGGLUE_SEQ_ID.NEXTVAL</sql>
<insert id="save" parameterType="com.xxl.job.admin.core.model.XxlJobLog" useGeneratedKeys="true" keyProperty="id" >
INSERT INTO xxl_job_log (
job_group,
job_id,
trigger_time,
trigger_code,
handle_code
) VALUES (
#{jobGroup},
#{jobId},
#{triggerTime},
#{triggerCode},
#{handleCode}
)
<!--<selectKey resultType="java.lang.Integer" order="AFTER" keyProperty="id">
SELECT LAST_INSERT_ID()
</selectKey>-->
</insert>
<insert id="save" databaseId="oracle" parameterType="com.xxl.job.admin.core.model.XxlJobLog" useGeneratedKeys="true" keyProperty="id" >
<selectKey keyProperty="id" resultType="int" order="BEFORE">
select <include refid="XXL_JOB_LOG_ID" /> from dual
</selectKey>
INSERT INTO xxl_job_log (
id,
job_group,
job_id,
trigger_time,
trigger_code,
handle_code
) VALUES (
#{id},
#{jobGroup},
#{jobId},
#{triggerTime},
#{triggerCode},
#{handleCode}
)
<!--<selectKey resultType="java.lang.Integer" order="AFTER" keyProperty="id">
SELECT LAST_INSERT_ID()
</selectKey>-->
</insert>
<update id="updateTriggerInfo" >
UPDATE xxl_job_log
SET
trigger_time= #{triggerTime},
trigger_code= #{triggerCode},
trigger_msg= #{triggerMsg},
executor_address= #{executorAddress},
executor_handler=#{executorHandler},
executor_param= #{executorParam},
executor_sharding_param= #{executorShardingParam},
executor_fail_retry_count= #{executorFailRetryCount}
WHERE id= #{id}
</update>
<update id="updateTriggerInfo" databaseId="oracle">
UPDATE xxl_job_log
SET
trigger_time= #{triggerTime,jdbcType=DATE},
trigger_code= #{triggerCode,jdbcType=VARCHAR},
trigger_msg= #{triggerMsg,jdbcType=VARCHAR},
executor_address= #{executorAddress,jdbcType=VARCHAR},
executor_handler=#{executorHandler,jdbcType=VARCHAR},
executor_param= #{executorParam,jdbcType=VARCHAR},
executor_sharding_param= #{executorShardingParam,jdbcType=VARCHAR},
executor_fail_retry_count= #{executorFailRetryCount}
WHERE id= #{id}
</update>
<update id="updateHandleInfo">
UPDATE xxl_job_log
SET
handle_time= #{handleTime},
handle_code= #{handleCode},
handle_msg= #{handleMsg}
WHERE id= #{id}
</update>
<update id="updateHandleInfo" databaseId="oracle">
UPDATE xxl_job_log
SET
handle_time= #{handleTime,jdbcType=DATE},
handle_code= #{handleCode,jdbcType=VARCHAR},
handle_msg= #{handleMsg,jdbcType=CLOB}
WHERE id= #{id}
</update>
<delete id="delete" >
delete from xxl_job_log
WHERE job_id = #{jobId}
</delete>
<!--<select id="triggerCountByDay" resultType="java.util.Map" >
SELECT
DATE_FORMAT(trigger_time,'%Y-%m-%d') triggerDay,
COUNT(handle_code) triggerDayCount,
SUM(CASE WHEN (trigger_code in (0, 200) and handle_code = 0) then 1 else 0 end) as triggerDayCountRunning,
SUM(CASE WHEN handle_code = 200 then 1 else 0 end) as triggerDayCountSuc
FROM xxl_job_log
WHERE trigger_time BETWEEN #{from} and #{to}
GROUP BY triggerDay
ORDER BY triggerDay
</select>-->
<select id="findLogReport" resultType="java.util.Map" >
SELECT
COUNT(handle_code) triggerDayCount,
SUM(CASE WHEN (trigger_code in (0, 200) and handle_code = 0) then 1 else 0 end) as triggerDayCountRunning,
SUM(CASE WHEN handle_code = 200 then 1 else 0 end) as triggerDayCountSuc
FROM xxl_job_log
WHERE trigger_time BETWEEN #{from} and #{to}
</select>
<select id="findLogReport" databaseId="kingbase" resultType="java.util.Map" >
SELECT
COUNT(handle_code) TRIGGERDAYCOUNT,
SUM(CASE WHEN (trigger_code in (0, 200) and handle_code = 0) then 1 else 0 end) as TRIGGERDAYCOUNTRUNNING,
SUM(CASE WHEN handle_code = 200 then 1 else 0 end) as TRIGGERDAYCOUNTSUC
FROM xxl_job_log
WHERE trigger_time BETWEEN #{from} and #{to}
</select>
<select id="findClearLogIds" resultType="long" >
SELECT id FROM xxl_job_log
<trim prefix="WHERE" prefixOverrides="AND | OR" >
<if test="jobGroup gt 0">
AND job_group = #{jobGroup}
</if>
<if test="jobId gt 0">
AND job_id = #{jobId}
</if>
<if test="clearBeforeTime != null">
AND trigger_time <![CDATA[ <= ]]> #{clearBeforeTime}
</if>
<if test="clearBeforeNum gt 0">
AND id NOT in(
SELECT id FROM(
SELECT id FROM xxl_job_log t
<trim prefix="WHERE" prefixOverrides="AND | OR" >
<if test="jobGroup gt 0">
AND t.job_group = #{jobGroup}
</if>
<if test="jobId gt 0">
AND t.job_id = #{jobId}
</if>
</trim>
ORDER BY t.trigger_time desc
LIMIT 0, #{clearBeforeNum}
) t1
)
</if>
</trim>
order by id asc
LIMIT #{pagesize}
</select>
<select id="findClearLogIds" databaseId="sqlserver" resultType="long" >
SELECT top (#{pagesize}) id FROM xxl_job_log
<trim prefix="WHERE" prefixOverrides="AND | OR" >
<if test="jobGroup gt 0">
AND job_group = #{jobGroup}
</if>
<if test="jobId gt 0">
AND job_id = #{jobId}
</if>
<if test="clearBeforeTime != null">
AND trigger_time <![CDATA[ <= ]]> #{clearBeforeTime}
</if>
<if test="clearBeforeNum gt 0">
AND id NOT in(
SELECT id FROM(
SELECT top (#{clearBeforeNum}) id FROM xxl_job_log AS t
<trim prefix="WHERE" prefixOverrides="AND | OR" >
<if test="jobGroup gt 0">
AND t.job_group = #{jobGroup}
</if>
<if test="jobId gt 0">
AND t.job_id = #{jobId}
</if>
</trim>
ORDER BY t.trigger_time desc
) t1
)
</if>
</trim>
order by id asc
</select>
<select id="findClearLogIds" databaseId="kingbase" resultType="long" >
SELECT id FROM xxl_job_log
<trim prefix="WHERE" prefixOverrides="AND | OR" >
<if test="jobGroup gt 0">
AND job_group = #{jobGroup}
</if>
<if test="jobId gt 0">
AND job_id = #{jobId}
</if>
<if test="clearBeforeTime != null">
AND trigger_time <![CDATA[ <= ]]> #{clearBeforeTime}
</if>
<if test="clearBeforeNum gt 0">
AND id NOT in(
SELECT id FROM(
SELECT id FROM xxl_job_log t
<trim prefix="WHERE" prefixOverrides="AND | OR" >
<if test="jobGroup gt 0">
AND t.job_group = #{jobGroup}
</if>
<if test="jobId gt 0">
AND t.job_id = #{jobId}
</if>
</trim>
ORDER BY t.trigger_time desc
LIMIT #{clearBeforeNum}
) t1
)
</if>
</trim>
order by id asc
LIMIT #{pagesize}
</select>
<select id="findClearLogIds" databaseId="pg" resultType="long" >
SELECT id FROM xxl_job_log
<trim prefix="WHERE" prefixOverrides="AND | OR" >
<if test="jobGroup gt 0">
AND job_group = #{jobGroup}
</if>
<if test="jobId gt 0">
AND job_id = #{jobId}
</if>
<if test="clearBeforeTime != null">
AND trigger_time <![CDATA[ <= ]]> #{clearBeforeTime}
</if>
<if test="clearBeforeNum gt 0">
AND id NOT in(
SELECT id FROM(
SELECT id FROM xxl_job_log AS t
<trim prefix="WHERE" prefixOverrides="AND | OR" >
<if test="jobGroup gt 0">
AND t.job_group = #{jobGroup}
</if>
<if test="jobId gt 0">
AND t.job_id = #{jobId}
</if>
</trim>
ORDER BY t.trigger_time desc
LIMIT #{clearBeforeNum}
) t1
)
</if>
</trim>
order by id asc
LIMIT #{pagesize}
</select>
<select id="findClearLogIds" databaseId="oracle" resultType="long" >
SELECT id
FROM (
SELECT t.id, ROWNUM AS rnum
FROM xxl_job_log t
WHERE 1 = 1
<if test="jobGroup gt 0">
AND t.job_group = #{jobGroup}
</if>
<if test="jobId gt 0">
AND t.job_id = #{jobId}
</if>
<if test="clearBeforeTime != null">
AND t.trigger_time <![CDATA[ <= ]]> #{clearBeforeTime}
</if>
<if test="clearBeforeNum gt 0">
AND t.id NOT IN (
SELECT id
FROM (
SELECT t1.id
FROM xxl_job_log t1
WHERE 1 = 1
<if test="jobGroup gt 0">
AND t1.job_group = #{jobGroup}
</if>
<if test="jobId gt 0">
AND t1.job_id = #{jobId}
</if>
ORDER BY t1.trigger_time DESC
FETCH FIRST #{clearBeforeNum} ROWS ONLY
)
)
</if>
ORDER BY t.id ASC
)
WHERE rnum <![CDATA[ <= ]]> #{pagesize}
</select>
<!--<select id="findClearLogIds" databaseId="dm" resultType="long" >-->
<!--SELECT temp.id id FROM (-->
<!--SELECT id, rownum FROM xxl_job_log-->
<!--<trim prefix="WHERE" prefixOverrides="AND | OR" >-->
<!--<if test="jobGroup gt 0">-->
<!--AND job_group = #{jobGroup}-->
<!--</if>-->
<!--<if test="jobId gt 0">-->
<!--AND job_id = #{jobId}-->
<!--</if>-->
<!--<if test="clearBeforeTime != null">-->
<!--AND trigger_time <![CDATA[ <= ]]> #{clearBeforeTime}-->
<!--</if>-->
<!--<if test="clearBeforeNum gt 0">-->
<!--AND id NOT in(-->
<!--SELECT id FROM(-->
<!--SELECT id FROM xxl_job_log t-->
<!--<trim prefix="WHERE" prefixOverrides="AND | OR" >-->
<!--<if test="jobGroup gt 0">-->
<!--AND t.job_group = #{jobGroup}-->
<!--</if>-->
<!--<if test="jobId gt 0">-->
<!--AND t.job_id = #{jobId}-->
<!--</if>-->
<!--</trim>-->
<!--ORDER BY t.trigger_time desc-->
<!--LIMIT 0, #{clearBeforeNum}-->
<!--) t1-->
<!--)-->
<!--</if>-->
<!--AND rownum <![CDATA[ < ]]> (#{pagesize} + 1)-->
<!--</trim>-->
<!--order by id asc) temp-->
<!--</select>-->
<delete id="clearLog" >
delete from xxl_job_log
WHERE id in
<foreach collection="logIds" item="item" open="(" close=")" separator="," >
#{item}
</foreach>
</delete>
<select id="findFailJobLogIds" resultType="long" >
SELECT id FROM xxl_job_log
WHERE !(
(trigger_code in (0, 200) and handle_code = 0)
OR
(handle_code = 200)
)
AND alarm_status = 0
ORDER BY id ASC
LIMIT #{pagesize}
</select>
<select id="findFailJobLogIds" databaseId="sqlserver" resultType="long" >
SELECT top (#{pagesize}) id FROM xxl_job_log
WHERE ( (trigger_code != 0 or handle_code != 0) and (handle_code != 200) )
AND alarm_status = 0
ORDER BY id ASC
</select>
<select id="findFailJobLogIds" databaseId="kingbase" resultType="long" >
SELECT id FROM xxl_job_log
WHERE not(
(trigger_code in (0, 200) and handle_code = 0)
OR
(handle_code = 200)
)
AND alarm_status = 0
ORDER BY id ASC
LIMIT #{pagesize}
</select>
<select id="findFailJobLogIds" databaseId="pg" resultType="long" >
SELECT id FROM xxl_job_log
WHERE (
(trigger_code in (0, 200) and handle_code = 0)
OR
(handle_code = 200)
)=false
AND alarm_status = 0
ORDER BY id ASC
LIMIT #{pagesize}
</select>
<select id="findFailJobLogIds" databaseId="oracle" resultType="long">
SELECT id FROM (
SELECT id, ROWNUM AS rnum FROM xxl_job_log
WHERE not(
(trigger_code in (0, 200) and handle_code = 0)
OR
(handle_code = 200)
)
AND alarm_status = 0
ORDER BY id ASC
)
WHERE rnum <![CDATA[ <= ]]> #{pagesize,jdbcType=INTEGER}
</select>
<select id="findFailJobLogIds" databaseId="dm" resultType="long" >
SELECT id FROM xxl_job_log
WHERE not(
(trigger_code in (0, 200) and handle_code = 0)
OR
(handle_code = 200)
)
AND alarm_status = 0
ORDER BY id ASC
LIMIT #{pagesize}
</select>
<update id="updateAlarmStatus" >
UPDATE xxl_job_log
SET
alarm_status = #{newAlarmStatus}
WHERE id= #{logId} AND alarm_status = #{oldAlarmStatus}
</update>
<select id="findLostJobIds" resultType="long" >
SELECT
t.id
FROM
xxl_job_log t
LEFT JOIN xxl_job_registry t2 ON t.executor_address = t2.registry_value
WHERE
t.trigger_code = 200
AND t.handle_code = 0
AND t.trigger_time <![CDATA[ <= ]]> #{losedTime}
AND t2.id IS NULL
</select>
<!--
SELECT t.id
FROM xxl_job_log AS t
WHERE t.trigger_code = 200
and t.handle_code = 0
and t.trigger_time <![CDATA[ <= ]]> #{losedTime}
and t.executor_address not in (
SELECT t2.registry_value
FROM xxl_job_registry AS t2
)
-->
</mapper>3.3.5 XxlJobLogReportMapper.xml
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.xxl.job.admin.dao.XxlJobLogReportDao">
<resultMap id="XxlJobLogReport" type="com.xxl.job.admin.core.model.XxlJobLogReport" >
<result column="id" property="id" />
<result column="trigger_day" property="triggerDay" />
<result column="running_count" property="runningCount" />
<result column="suc_count" property="sucCount" />
<result column="fail_count" property="failCount" />
</resultMap>
<sql id="Base_Column_List">
t.id,
t.trigger_day,
t.running_count,
t.suc_count,
t.fail_count
</sql>
<insert id="save" parameterType="com.xxl.job.admin.core.model.XxlJobLogReport" useGeneratedKeys="true" keyProperty="id" >
INSERT INTO xxl_job_log_report (
trigger_day,
running_count,
suc_count,
fail_count
) VALUES (
#{triggerDay},
#{runningCount},
#{sucCount},
#{failCount}
)
<!--<selectKey resultType="java.lang.Integer" order="AFTER" keyProperty="id">
SELECT LAST_INSERT_ID()
</selectKey>-->
</insert>
<sql databaseId="oracle" id='XXL_JOB_LOG_REPORT_ID'>XXL_JOB_LOG_REPORT_SEQ_ID.NEXTVAL</sql>
<insert id="save" databaseId="oracle" parameterType="com.xxl.job.admin.core.model.XxlJobLogReport" useGeneratedKeys="true" keyProperty="id" >
<selectKey keyProperty="id" resultType="int" order="BEFORE">
select <include refid="XXL_JOB_LOG_REPORT_ID" /> from dual
</selectKey>
INSERT INTO xxl_job_log_report (
id,
trigger_day,
running_count,
suc_count,
fail_count
) VALUES (
#{id},
#{triggerDay,jdbcType=DATE},
#{runningCount,jdbcType=NUMERIC},
#{sucCount,jdbcType=NUMERIC},
#{failCount,jdbcType=NUMERIC}
)
</insert>
<update id="update" databaseId="oracle">
UPDATE xxl_job_log_report
SET running_count = #{runningCount,jdbcType=NUMERIC},
suc_count = #{sucCount,jdbcType=NUMERIC},
fail_count = #{failCount,jdbcType=NUMERIC}
WHERE trigger_day = #{triggerDay}
</update>
<update id="update" >
UPDATE xxl_job_log_report
SET running_count = #{runningCount},
suc_count = #{sucCount},
fail_count = #{failCount}
WHERE trigger_day = #{triggerDay}
</update>
<select id="queryLogReport" resultMap="XxlJobLogReport">
SELECT <include refid="Base_Column_List" />
FROM xxl_job_log_report t
WHERE t.trigger_day between #{triggerDayFrom} and #{triggerDayTo}
ORDER BY t.trigger_day ASC
</select>
<select id="queryLogReportTotal" resultMap="XxlJobLogReport">
SELECT
SUM(running_count) running_count,
SUM(suc_count) suc_count,
SUM(fail_count) fail_count
FROM xxl_job_log_report t
</select>
</mapper>3.3.6 XxlJobRegistryMapper.xml
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.xxl.job.admin.dao.XxlJobRegistryDao">
<resultMap id="XxlJobRegistry" type="com.xxl.job.admin.core.model.XxlJobRegistry" >
<result column="id" property="id" />
<result column="registry_group" property="registryGroup" />
<result column="registry_key" property="registryKey" />
<result column="registry_value" property="registryValue" />
<result column="update_time" property="updateTime" />
</resultMap>
<sql id="Base_Column_List">
t.id,
t.registry_group,
t.registry_key,
t.registry_value,
t.update_time
</sql>
<select id="findDead" parameterType="java.util.HashMap" resultType="java.lang.Integer" >
SELECT t.id
FROM xxl_job_registry t
WHERE t.update_time <![CDATA[ < ]]> DATE_ADD(#{nowTime},INTERVAL -#{timeout} SECOND)
</select>
<select id="findDead" databaseId="sqlserver" parameterType="java.util.HashMap" resultType="java.lang.Integer" >
SELECT t.id
FROM xxl_job_registry AS t
WHERE t.update_time <![CDATA[ < ]]> DATEADD(ss, -#{timeout}, #{nowTime})
</select>
<select id="findDead" databaseId="kingbase" parameterType="java.util.HashMap" resultType="java.lang.Integer" >
SELECT t.id
FROM xxl_job_registry t
WHERE t.update_time <![CDATA[ < ]]> date '${nowTime}' - INTERVAL '${timeout} second'
</select>
<select id="findDead" databaseId="pg" parameterType="java.util.HashMap" resultType="java.lang.Integer" >
SELECT t.id
FROM xxl_job_registry t
WHERE t.update_time <![CDATA[ < ]]> ((select NOW())-INTERVAL ' ${timeout} SEC ' )
</select>
<select id="findDead" databaseId="oracle" parameterType="java.util.HashMap" resultType="java.lang.Integer" >
SELECT t.id
FROM xxl_job_registry t
WHERE t.update_time <![CDATA[ < ]]> (#{nowTime} - numtodsinterval(#{timeout},'second'))
</select>
<select id="findDead" databaseId="dm" parameterType="java.util.HashMap" resultType="java.lang.Integer" >
SELECT t.id
FROM xxl_job_registry t
WHERE t.update_time <![CDATA[ < ]]> (#{nowTime} - numtodsinterval(#{timeout},'second'))
</select>
<delete id="removeDead" parameterType="java.lang.Integer" >
DELETE FROM xxl_job_registry
WHERE id in
<foreach collection="ids" item="item" open="(" close=")" separator="," >
#{item}
</foreach>
</delete>
<select id="findAll" parameterType="java.util.HashMap" resultMap="XxlJobRegistry">
SELECT <include refid="Base_Column_List" />
FROM xxl_job_registry t
WHERE t.update_time <![CDATA[ > ]]> DATE_ADD(#{nowTime},INTERVAL -#{timeout} SECOND)
</select>
<select id="findAll" databaseId="sqlserver" parameterType="java.util.HashMap" resultMap="XxlJobRegistry">
SELECT <include refid="Base_Column_List" />
FROM xxl_job_registry AS t
WHERE t.update_time <![CDATA[ > ]]> DATEADD(ss, -#{timeout}, #{nowTime})
</select>
<select id="findAll" databaseId="kingbase" parameterType="java.util.HashMap" resultMap="XxlJobRegistry">
SELECT <include refid="Base_Column_List" />
FROM xxl_job_registry AS t
WHERE t.update_time <![CDATA[ > ]]> date '${nowTime}' - INTERVAL '${timeout} second'
</select>
<select id="findAll" databaseId="pg" parameterType="java.util.HashMap" resultMap="XxlJobRegistry">
SELECT <include refid="Base_Column_List" />
FROM xxl_job_registry t
WHERE t.update_time <![CDATA[ > ]]> ((select NOW())-INTERVAL ' ${timeout} SEC ' )
</select>
<select id="findAll" databaseId="oracle" parameterType="java.util.HashMap" resultMap="XxlJobRegistry">
SELECT <include refid="Base_Column_List" />
FROM xxl_job_registry t
WHERE t.update_time <![CDATA[ > ]]> (#{nowTime} - numtodsinterval(#{timeout},'second'))
</select>
<select id="findAll" databaseId="dm" parameterType="java.util.HashMap" resultMap="XxlJobRegistry">
SELECT <include refid="Base_Column_List" />
FROM xxl_job_registry t
WHERE t.update_time <![CDATA[ > ]]> (#{nowTime} - numtodsinterval(#{timeout},'second'))
</select>
<update id="registryUpdate" >
UPDATE xxl_job_registry
SET update_time = #{updateTime}
WHERE registry_group = #{registryGroup}
AND registry_key = #{registryKey}
AND registry_value = #{registryValue}
</update>
<sql id='XXL_JOB_REGISTRY_ID'>XXL_JOB_REGISTRY_SEQ_ID.NEXTVAL</sql>
<insert id="registrySave" >
INSERT INTO xxl_job_registry( registry_group , registry_key , registry_value, update_time)
VALUES( #{registryGroup} , #{registryKey} , #{registryValue}, #{updateTime})
</insert>
<insert id="registrySave" databaseId="oracle">
<selectKey keyProperty="id" resultType="int" order="BEFORE">
select <include refid="XXL_JOB_REGISTRY_ID" /> from dual
</selectKey>
INSERT INTO xxl_job_registry( id ,registry_group , registry_key , registry_value, update_time)
VALUES( #{id} , #{registryGroup} , #{registryKey} , #{registryValue}, #{updateTime})
</insert>
<delete id="registryDelete" >
DELETE FROM xxl_job_registry
WHERE registry_group = #{registryGroup}
AND registry_key = #{registryKey}
AND registry_value = #{registryValue}
</delete>
</mapper>3.3.7 XxlJobUserMapper.xml
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.xxl.job.admin.dao.XxlJobUserDao">
<resultMap id="XxlJobUser" type="com.xxl.job.admin.core.model.XxlJobUser" >
<result column="id" property="id" />
<result column="username" property="username" />
<result column="password" property="password" />
<result column="role" property="role" />
<result column="permission" property="permission" />
</resultMap>
<sql id="Base_Column_List">
t.id,
t.username,
t.password,
t.role,
t.permission
</sql>
<select id="pageList" parameterType="java.util.HashMap" resultMap="XxlJobUser">
SELECT <include refid="Base_Column_List" />
FROM xxl_job_user t
<trim prefix="WHERE" prefixOverrides="AND | OR" >
<if test="username != null and username != ''">
AND t.username like CONCAT(CONCAT('%', #{username}), '%')
</if>
<if test="role gt -1">
AND t.role = #{role}
</if>
</trim>
ORDER BY username ASC
LIMIT #{offset}, #{pagesize}
</select>
<select id="pageList" databaseId="sqlserver" parameterType="java.util.HashMap" resultMap="XxlJobUser">
SELECT <include refid="Base_Column_List" />
from (
SELECT row_number () OVER ( ORDER BY username ASC ) AS rownumber,
<include refid="Base_Column_List" />
FROM xxl_job_user AS t
<trim prefix="WHERE" prefixOverrides="AND | OR" >
<if test="username != null and username != ''">
AND t.username like CONCAT(CONCAT('%', #{username}), '%')
</if>
<if test="role gt -1">
AND t.role = #{role}
</if>
</trim>) AS t
WHERE t.rownumber <![CDATA[ > ]]> #{offset}
AND t.rownumber <![CDATA[ <= ]]> (#{offset} + #{pagesize})
</select>
<select id="pageList" databaseId="kingbase" parameterType="java.util.HashMap" resultMap="XxlJobUser">
SELECT <include refid="Base_Column_List" />
FROM xxl_job_user t
<trim prefix="WHERE" prefixOverrides="AND | OR" >
<if test="username != null and username != ''">
AND t.username like CONCAT(CONCAT('%', #{username}), '%')
</if>
<if test="role gt -1">
AND t.role = #{role}
</if>
</trim>
ORDER BY username ASC
LIMIT #{pagesize} offset #{offset}
</select>
<select id="pageList" databaseId="pg" parameterType="java.util.HashMap" resultMap="XxlJobUser">
SELECT <include refid="Base_Column_List" />
FROM xxl_job_user t
<trim prefix="WHERE" prefixOverrides="AND | OR" >
<if test="username != null and username != ''">
AND t.username like CONCAT(CONCAT('%', #{username}), '%')
</if>
<if test="role gt -1">
AND t.role = #{role}
</if>
</trim>
ORDER BY username ASC
LIMIT #{pagesize} offset #{offset}
</select>
<select id="pageList" databaseId="oracle" parameterType="java.util.HashMap" resultMap="XxlJobUser">
SELECT <include refid="Base_Column_List" />, rownum
FROM xxl_job_user t
<trim prefix="WHERE" prefixOverrides="AND | OR" >
<if test="username != null and username != ''">
AND t.username like CONCAT(CONCAT('%', #{username}), '%')
</if>
<if test="role gt -1">
AND t.role = #{role}
</if>
AND rownum <![CDATA[ > ]]> #{offset} AND rownum <![CDATA[ < ]]> (#{offset} + #{pagesize} + 1)
</trim>
ORDER BY username ASC
</select>
<!--<select id="pageList" databaseId="dm" parameterType="java.util.HashMap" resultMap="XxlJobUser">-->
<!--SELECT <include refid="Base_Column_List" />, rownum-->
<!--FROM xxl_job_user t-->
<!--<trim prefix="WHERE" prefixOverrides="AND | OR" >-->
<!--<if test="username != null and username != ''">-->
<!--AND t.username like CONCAT(CONCAT('%', #{username}), '%')-->
<!--</if>-->
<!--<if test="role gt -1">-->
<!--AND t.role = #{role}-->
<!--</if>-->
<!--AND rownum <![CDATA[ > ]]> #{offset} AND rownum <![CDATA[ < ]]> (#{offset} + #{pagesize} + 1)-->
<!--</trim>-->
<!--ORDER BY username ASC-->
<!--LIMIT #{offset}, #{pagesize}-->
<!--</select>-->
<select id="pageListCount" parameterType="java.util.HashMap" resultType="int">
SELECT count(1)
FROM xxl_job_user t
<trim prefix="WHERE" prefixOverrides="AND | OR" >
<if test="username != null and username != ''">
AND t.username like CONCAT(CONCAT('%', #{username}), '%')
</if>
<if test="role gt -1">
AND t.role = #{role}
</if>
</trim>
</select>
<select id="loadByUserName" parameterType="java.util.HashMap" resultMap="XxlJobUser">
SELECT <include refid="Base_Column_List" />
FROM xxl_job_user t
WHERE t.username = #{username}
</select>
<insert id="save" parameterType="com.xxl.job.admin.core.model.XxlJobUser" useGeneratedKeys="true" keyProperty="id" >
INSERT INTO xxl_job_user (
username,
password,
role,
permission
) VALUES (
#{username},
#{password},
#{role},
#{permission}
)
</insert>
<update id="update" parameterType="com.xxl.job.admin.core.model.XxlJobUser" >
UPDATE xxl_job_user
SET
<if test="password != null and password != ''">
password = #{password},
</if>
role = #{role},
permission = #{permission}
WHERE id = #{id}
</update>
<delete id="delete" parameterType="java.util.HashMap">
DELETE
FROM xxl_job_user
WHERE id = #{id}
</delete>
</mapper>3.4 自定义DatabaseIdProvider
多数据库的适配主要是用了mybaties的databaseId来实现的,因此需要在项目里面对databaseId做自定义的映射配置
具体如下:
package com.xxl.job.admin.core.conf;
import org.apache.ibatis.mapping.DatabaseIdProvider;
import org.apache.ibatis.mapping.VendorDatabaseIdProvider;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import java.util.Properties;
/**
* @Description TODO
* @Author wx
*/
@Configuration
public class XxlJobDatabaseIdProvider {
@Bean
public DatabaseIdProvider databaseIdProvider() {
DatabaseIdProvider databaseIdProvider = new VendorDatabaseIdProvider();
Properties properties = new Properties();
properties.setProperty("Oracle", "oracle");
properties.setProperty("MySQL", "mysql");
properties.setProperty("DM DBMS", "dm");
properties.setProperty("DM", "dm");
properties.setProperty("PostgreSQL", "pg");
properties.setProperty("Zenith", "pg");
properties.setProperty("UXSQL", "pg");
properties.setProperty("SQL Server", "sqlserver");
properties.setProperty("Microsoft SQL Server", "sqlserver");
properties.setProperty("Kingbase", "kingbase");
properties.setProperty("KingbaseES", "kingbase");
properties.setProperty("GBase", "gbase");
databaseIdProvider.setProperties(properties);
return databaseIdProvider;
}
}















 4428
4428











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









