







 本文详细介绍了KNN算法中的数据归一化处理,包括手动处理方法和使用sklearn的MinMaxScaler,强调了归一化不改变数据分布的重要性。同时,讨论了KNN算法的优缺点,如计算效率低、对噪声敏感和需要归一化等,并提出模型优化应关注运算速度、可解释性和模型效果,遵循先训练集后测试集的归一化原则。
本文详细介绍了KNN算法中的数据归一化处理,包括手动处理方法和使用sklearn的MinMaxScaler,强调了归一化不改变数据分布的重要性。同时,讨论了KNN算法的优缺点,如计算效率低、对噪声敏感和需要归一化等,并提出模型优化应关注运算速度、可解释性和模型效果,遵循先训练集后测试集的归一化原则。
数据归一化处理
- 公式:(每个值-最小值)/(最大值-最小值)
- 数据归一化处理,不会改变数据原有的分布情况
- 模拟的数据集
data = [[-1,201],[-0.5,189],[0,199],[1,187],[1,200],[2,196]]
data = pd.DataFrame(data)
data
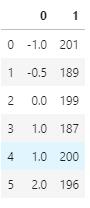
手动处理
- 以其中一列为例(具体根据业务场景)
data[1] =(data[1]-data[1].min())/(data[1].max()-data[1].min())
data
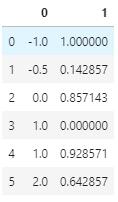
使用sklearn中prepprocessing 中的MinMaxScaler
from sklearn.preprocessing import MinMaxScaler
mms = MinMaxScaler()
mms.fit(data)
data_new = pd.DataFrame(mms.transform(data))
data_new
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2360
2360

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









