







数据的物理结构与逻辑结构
目录
数据结构教我们有效地存储数据,既要存储数据本身,还要存储数据之间的关系。
存储数据本身,也就是将数据存储到内存里。数据在内存中的存储状态,就称为数据的存储结构,也叫物理结构。
数据结构中,将数据之间的关系称为数据的逻辑结构。
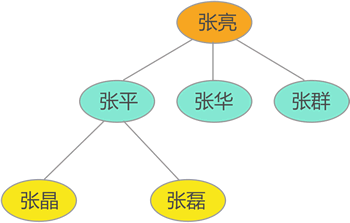
以下图所示的家谱图为例,数据之间存在很多关系,比如张亮是张平的父辈、是张静的祖辈等,所有这些关系就构成了数据的逻辑结构。
数据的物理结构
在内存中,数据的存储结构无非有以下两种情况:
1) 集中存储:所有数据存储在一整块内存空间中,数据之间紧挨着存放(顺序存储结构--顺序表)
2) 分散存储:各个数据随机存储在内存空间中(链式存储结构--链表)
两种存储结构各有优势,将数据集中存储,方便后续查找数据;将数据分散存储,方便后续增加或者删除数据。
数据的逻辑结构
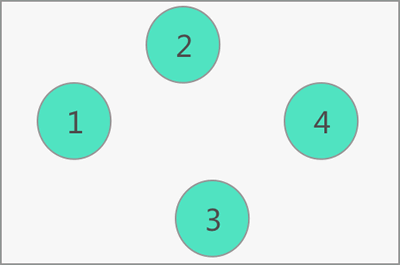
1) 无关系:所谓“无关系”,即数据之间不存在任何关系。例如下图中,{1,2,3,4} 中各个数据之间就没有任何关系。
2) 一对一:下图的数据集中,每个数据的左侧有且仅有一个数据与其相邻(除 1 外);同样,每个数据的右侧也只有一个数据与其相邻(除 n 外),所有的数据都是如此,数据之间就是“一对一”的逻辑结构。

3) 一对多
如“家谱图”中,数据之间就是“一对多”的逻辑结构。
以“张平”为例,他的父辈是“张亮”;他有两个孩子,分别是“张晶”和“张磊”。“张平”和其它数据之间就是“一对多”的关系,整个数据集呈现“一对多”的逻辑结构。
4) 多对多:下图{V1,V2,V3,V4} 数据之间就具有“多对多”的逻辑结构。

多对多关系和一对多关系的区别在于:一对多关系中不存在环路,而多对多关系中存在环路,比如V1->V3->V2->V1就是一个环路。
针对每一种逻辑结构的数据,数据结构都提供了存储它们的方案:
- 查找表存储结构:专门存储无逻辑结构的数据;
- 线性存储结构:专门存储具有“一对一”逻辑结构的数据;
- 树存储结构:专门存储具有“一对多”逻辑结构的数据;
- 图存储结构:专门用来存储具有“多对多”关系的数据;
总结
关于数据结构,与其说它是一门研究存储数据以及数据之间关系的学科,还可以这样概括:它是一门研究数据存储结构和逻辑结构的学科。通过研究数据的物理结构,可以掌握存储数据的方法;通过研究数据的逻辑结构,可以掌握存储数据之间关系的方法。
数据的存储结构有 2 种,分别是集中存储和分散存储。如果想集中存储数据,就选择顺序存储结构;如果想分散存储数据,就择链式存储结构。
数据的逻辑结构有 4 种,分别是“无关系”、“一对一”、“一对多”和“多对多”。无逻辑关系的数据可以选用查找表存储结构;具有“一对一”关系的数据可以选用线性存储结构;具有“一对多”关系的数据可以选用树存储结构;具有“多对多”关系的数据可以选用图存储结构
实际场景中,确定了数据的存储结构和逻辑结构,就可以敲定数据的存储方案。比如,数据呈现“一对多”关系,想分散存储,那么就选用【树的链式存储结构f】。
逻辑结构和存储结构(物理结构)详解 (biancheng.net)
数据结构与算法的区别与联系
数据结构和算法之间完全是两个相互独立的学科,如果非说它们有关系,那也只是互利共赢、“1+1>2”的关系。
我们还可以从分析问题的角度去理清数据结构和算法之间的关系。通常,每个问题的解决都经过以下两个步骤:
- 分析问题,从问题中提取出有价值的数据,将其存储;
- 对存储的数据进行处理,最终得出问题的答案;
数据结构负责解决第一个问题,即数据的存储问题。通过前面的学习我们知道,针对数据不同的逻辑结构和物理结构,可以选出最优的数据存储结构来存储数据。
而剩下的第二个问题,属于算法的职责范围。算法,从表面意思来理解,即解决问题的方法。我们知道,评价一个算法的好坏,取决于在解决相同问题的前提下,哪种算法的效率最高,而这里的效率指的就是处理数据、分析数据的能力。
因此我们得出这样的结论,数据结构用于解决数据存储问题,而算法用于处理和分析数据,它们是完全不同的两类学科。
也正因为如此,你可以认为数据结构和算法存在“互利共赢、1+1>2”的关系。在解决问题的过程中,数据结构要配合算法选择最优的存储结构来存储数据,而算法也要结合数据存储的特点,用最优的策略来分析并处理数据,由此可以最高效地解决问题。
例如,有这样一个问题,计算“1+2+3+4+5”的值。这个问题我们可以这样来分析:
- 计算 1、2、3、4 和 5 的和,首先要选择一种数据存储方式将它们存储起来,通过前面的学习我们知道,数据之间具有“一对一”的逻辑关系,最适合用线性表来存储。结合算法的实现,我们选择顺序表来存储数据(而不是链表)。
- 接下来,我们选择算法。由于数据集中存放,因此我们可以设计这样一个算法,使用一个初始值为 0 的变量 num 依次同存储的数据做“加”运算,最后得到的新 num 值就是最终结果。
选择顺序表而不是链表的原因,是顺序表遍历数据比链表更高效。后续讲顺序表时会做详细介绍。















 2586
2586











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









