







本系列文章为浙江大学陈越、何钦铭数据结构学习笔记,前面文章链接如下:
数据结构基础:P1-基本概念
文章目录
一、线性表及其实现
1.1 引子:多项式表示
线性结构是数据结构里面最基础、也是最简单的一种数据结构类型,其中典型的一种叫线性表。那么什么是线性表呢?下面我们看下关于一元多项式的表示的问题。
一元多项式的基本形式如下:
f ( x ) = a 0 + a 1 x + . . . + a n − 1 x n − 1 + a n x n f(x) = {a_0} + {a_1}x + ... + {a_{n - 1}}{x^{n - 1}} + {a_n}{x^n} f(x)=a0+a1x+...+an−1xn−1+anxn
主要运算:多项式相加、相减、相乘等
我们就碰到了一个问题:怎么用程序设计语言来表示这样的一个多项式以及实现相应的操作。首先我们分析一下,对多项式来讲,它的关键数据是什么:
多项式的关键数据:
----多项式项数 n n n
----各项系数 a i {a_i} ai及指数 i i i
1.1.1 顺序存储结构直接表示
多项式的表示有很多方法,其中最简单的一种方法就是顺序存储的直接表示。
用个数组 a a a 来表示一个多项式, a [ i ] a[i] a[i] 就可以表示相应的项的系数,而这个 i i i 就是对应的指数。
我们来看个具体的例子
我们有多项式 f ( x ) = 4 x 5 − 3 x 2 + 1 f(x) = 4{x^5} - 3{x^2} + 1 f(x)=4x5−3x2+1,它可以表示成下面这样:
但是这里面也有一些问题:
比方说我们看这个例子: f ( x ) = x + 3 x 2000 f(x) = x + 3{x^{2000}} f(x)=x+3x2000 。显然我们至少要用 2001 个分量的这样的一个数组来表示,而这2001个分量其实只有2项是非零的,其它全是 0。这样的一种表示方法显然会造成空间的巨大浪费,而且做加法运算的时候,要做个循环,从 0 开始一直遍历到 2000,实际上很多计算是在加无效的 0。
思考:所以我们在想,有没有可能只表示非零项?所以这就引入了第二种方法----顺序存储结构表示非零项。
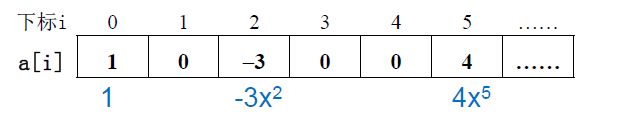
1.1.2 顺序存储结构表示非零项
顺序存储结构表示非零项的思路:
每个非零项 a i x i {a_i}{x^i} aixi 涉及两个信息:系数 a i a_i ai 和指数 i i i。可以将一个多项式看成是一个 ( a i , i ) (a_i,i) (ai,i) 二元组的集合。我们可以用结构数组表示:数组分量是由系数 a i a_i ai、指数 i i i 组成的结构,对应一个非零项。
举个例子
我们有两个多项式 P 1 ( x ) = 9 x 12 + 15 x 8 + 3 x 2 {P_1}(x) = 9{x^{12}} + 15{x^8} + 3{x^2} P1(x)=9x12+15x8+3x2 和 P 2 ( x ) = 26 x 19 − 4 x 8 − 13 x 6 + 82 {P_2}(x) = 26{x^{19}} - 4{x^8} - 13{x^6} + 82 P2(x)=26x19−4x8−13x6+82。用结构数组(按指数大小有序存储)分别表示如下:
这样的一种做法,它怎么做加法运算呢?
我们以前面这个两个多项式做加法为例,先把两个多项式的系数和指数列出来,如下:
接着执行以下操作:
①我们比较第一项:P1 第一项的指数是12,P2 第一项的指数是19。显然是P2第一项大,这两个对象相加的结果就是 26 x 19 26x^{19} 26x19
②接下来我们继续比较P1 的第一项指数12和P2的第二项指数8。显然是P1第一项大,这两个对象相加的结果就是 9 x 12 9x^{12} 9x12
③接下来我们继续比较P1 的第二项指数8和P2的第二项指数8。两者相等,这两个对象相加的结果就是 11 x 8 11x^{8} 11x8
④接下来我们继续比较P1 的第三项指数2和P2的第三项指数6。显然是P2的第三项大,这两个对象相加的结果就是 − 13 x 6 -13x^{6} −13x6
④接下来我们继续比较P1 的第三项指数2和P2的第四项指数0。显然是P1的第三项大,这两个对象相加的结果就是 3 x 2 3x^{2} 3x2
⑤P1 已经结束了,所以下面只剩下把 P2 剩下的内容输出就可以了,所以这就是我们两个多项式相加的结果:
P 3 ( x ) = 26 x 19 + 9 x 12 + 11 x 8 − 13 x 6 + 3 x 2 + 82 {P_3}(x) = 26{x^{19}} + 9{x^{12}} + 11{x^8} - 13{x^6} + 3{x^2} + 82 P3(x)=26x19+9x12+11x8−13x6+3x2+82
相加过程:从头开始,比较两个多项式当前对应项的指数。大的输出,相等的话,系数相加。

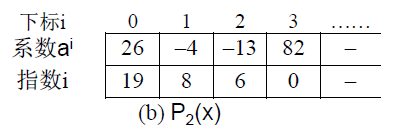
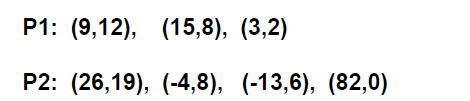
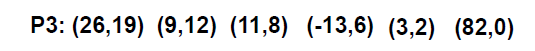
1.1.3 链表结构存储非零项
我不一定非要用数组来表示非零项,我也可以用链表。所以这就引入了我们的第三种方法,用链表结构来存储非零项。链表中每个结点存储多项式中的一个非零项,包括系数和指数这两个数据域以及一个指针域。
typedef struct PolyNode *Polynomial;
struct PolyNode {
int coef; //系数
int expon; //指数
Polynomial link; //指针,下一个结点
}
举个例子
我有两个多项式 P 1 ( x ) = 9 x 12 + 15 x 8 + 3 x 2 {P_1}(x) = 9{x^{12}} + 15{x^{8}} + 3{x^2} P1(x)=9x12+15x8+3x2 和 P 2 ( x ) = 26 x 19 − 4 x 8 − 13 x 6 + 82 {P_2}(x) = 26{x^{19}} - 4{x^{8}} - 13{x^6} + 82 P2(x)=26x19−4x8−13x6+82
对应的链表存储形式为:
同样它的加法运算,整个逻辑过程跟前面两个数组的运算是一样的。也就是说,我们分别指向多项式的头,然后比较指数大小,大的输出。相等的话,系数相加。

1.2 线性表及顺序存储
前面那个多项式的问题给我们什么启示呢?
①同一个问题可以有不同的表示方法,也就是不同的存储方法。一般来说,我们在数据结构里面最常见的就是两种方法:用数组来存储和用链表来存储。
②实际上不仅仅是多项式这个问题,还有很多其他一系列问题跟多项式问题是有共性的。我们的目标,是想管理一个有序的线性序列,我们就把它归结为线性表的问题。
1.2.1 线性表
线性表(Linear List)
由同类型数据元素构成有序序列的线性结构
①表中元素个数称为线性表的长度
②线性表没有元素时,称为空表
③表起始位置称表头,表结束位置称表尾
线性表的抽象数据类型描述
类型名称:线性表(List)
数据对象集:线性表是 n ( ≥ 0 ) n(≥0) n(≥0)个元素构成的有序序列( a 1 a_1 a1, a 2 a_2 a2,…, a n a_n an)
操作集:线性表 L ∈ L i s t {\rm{L}} \in {\rm{List}} L∈List,整数 i i i 表示位置,元素 X ∈ E l e m e n t T y p e {\rm{X}} \in {\rm{ElementType}} X∈ElementType,
线性表基本操作主要有:
----1、List MakeEmpty():初始化一个空线性表L;
----2、ElementType FindKth(int K, List L):根据位序K,返回相应元素 ;
----3、int Find(ElementType X, List L):在线性表L中查找X的第一次出现位置;
----4、void Insert(ElementType X, int i, List L):在位序i前插入一个新元素X;
----5、void Delete(int i, List L):删除指定位序i的元素;
----6、int Length(List L):返回线性表L的长度n。
线性表的顺序存储实现
利用数组的连续存储空间顺序存放线性表的各元素。这样一种存储方法,我们相应的一些数据结构的定义应该是怎么样呢?在这样的一种存储方法里面,显然我们有两个东西需要知道的。
①这个数组是什么,因为数组可以放不同长度的线性表,它是连续存放的。那它最后一个元素在哪里?所以我们要有个指针 Last来指示在这个数组里面存放的、线性表的最后一个元素所在的位置。
②需要定义个数组Data,它的分量类型是 ElementType
这样就构成一个结构,这个结构就可以抽象地实现一个线性表。具体定义如下:
typedef struct LNode *List;
struct LNode{
ElementType Data[MAXSIZE];
int Last;
} ;
struct LNode L;
List PtrL;
访问下标为 i 的元素: L.Data[i] 或 PtrL->Data[i]
线性表的长度: 因为Last的值代表位置,我们是从0开始,所以长度是L.Last+1 或 PtrL->Last+1
1.2.2 线性表的操作
初始化(建立空的顺序表)
List MakeEmpty( )
{
List PtrL;
PtrL = (List)malloc( sizeof(struct LNode));
PtrL->Last = -1;
return PtrL;
}
初始化(查找)
查找成功的平均比较次数为
(
n
+
1
)
/
2
(n +1)/2
(n+1)/2,平均时间性能为
O
(
n
)
O(n)
O(n)。
int Find( ElementType X, List PtrL )
{
int i = 0;
while( i <= PtrL->Last && PtrL->Data[i]!= X )
i++;
if (i > PtrL->Last) return -1; /* 如果没找到,返回-1 */
else return i; /* 找到后返回的是存储位置 */
}
1.3 顺序存储的插入和删除
1.3.1 插入操作实现
当我们在第 i ( 1 ≤ i ≤ n + 1 ) {\rm{i(1}} \le {\rm{i}} \le {\rm{n + 1)}} i(1≤i≤n+1) 个位置上插入一个值为 X X X 的新元素,步骤为:
①它是连续存放的,所以你首先要把下标为 i − 1 i-1 i−1 之后的这些元素全部往后挪一位,腾出 i − 1 i-1 i−1 这个位子来。
②每一个元素都往后挪,显然有个循环就可以做了。这个循环显然应该是从后面开始挪,把最后一个往后挪,倒数第二个往后挪……否则你从前往后挪,这个算法是不对的,会覆盖掉数据。
③插入操作的平均移动次数为 ( n − 2 ) / 2 (n-2)/2 (n−2)/2,平均时间性能为 O ( n ) O(n) O(n)

所以我们这样一个具体的算法就可以写成这样子:
void Insert( ElementType X, int i, List PtrL )
{
int j;
if ( PtrL->Last == MAXSIZE-1 ){ /* 表空间已满,不能插入*/
printf("表满");
return;
}
if ( i < 1 || i > PtrL->Last+2) { /*检查插入位置的合法性*/
printf("位置不合法");
return;
}
for ( j = PtrL->Last; j >= i-1; j-- )
PtrL->Data[j+1] = PtrL->Data[j]; /*将 ai~ an倒序向后移动*/
PtrL->Data[i-1] = X; /*新元素插入*/
PtrL->Last++; /*Last仍指向最后元素*/
return;
}
1.3.2 删除操作实现
删除操作思路分析
我们要把第 i i i 个元素移掉,意味着整个连续存放空间里面这个位置空出来了,所以必须把 i i i 之后的这些元素按照从左往右的顺序全部往前挪。也就是说,下标为 i i i 的元素挪到 i − 1 i-1 i−1,下标为 i + 1 i+1 i+1的元素挪到 i i i…。删除操作的平均移动次数为 ( n − 1 ) / 2 (n-1)/2 (n−1)/2,平均时间性能为 O ( n ) O(n) O(n)。

所以我们这样一个具体的算法就可以写成这样子。
void Delete( int i, List PtrL )
{
int j;
if( i < 1 || i > PtrL->Last+1 ) { /*检查空表及删除位置的合法性*/
printf ("不存在第%d个元素", i );
return ;
}
for ( j = i; j <= PtrL->Last; j++ )
PtrL->Data[j-1] = PtrL->Data[j]; /*将 ai+1~ an顺序向前移动*/
PtrL->Last--; /*Last仍指向最后元素*/
return;
}
1.4 链式存储及查找
1.4.1 链式存储
前面我们讲了,线性表可以用顺序存储,也就说用数组来实现。同样的,线性表也可以用链表来实现。线性表的链式存储就是:
①不要求逻辑上相邻的两个元素物理上也相邻;
②通过链建立起数据元素之间的逻辑关系。
③插入、删除不需要移动数据元素,只需要修改链
链表每个结点都是一个结构,这个结构里面至少有两个分量。一个分量是代表这个结点所对应的数据,另外一个是代表它的下一个结点的位置,就是Next的一个指针。
typedef struct LNode *List;
struct LNode{
ElementType Data;
List Next;
};
struct Lnode L;
List PtrL;
1.4.2 链式存储的操作
求表长
用链表来实现的时候,我们只知道这个链表的头指针,而且它是单向链表。这个时候要想求这个表里的元素,我们就要这个链表遍历一遍,就从头到尾一个个看,看到最后一个元素为止。时间性能为 O ( n ) O(n) O(n)。
对应代码如下
int Length ( List PtrL )
{
List p = PtrL; /* p指向表的第一个结点*/
int j = 0;
while ( p ) {
p = p->Next;
j++; /* 当前p指向的是第 j 个结点*/
}
return j;
}
查找
①按序号查找: FindKth
在数组里面,我们知道,要找到序号为i的元素是很简单的, a [ i − 1 ] a[i-1] a[i−1]就可以了。在链表里面就没那么简单了,我们必须要一个个往后找,所以采用的方法也类似链表的这样一种遍历方法。
对应代码如下
List FindKth( int K, List PtrL )
{
List p = PtrL;
int i = 1;
while (p !=NULL && i < K ){
p = p->Next;
i++;
}
if ( i == K ) return p;
/* 找到第K个,返回指针 */
else return NULL;
/* 否则返回空 */
}
②按值查找: Find
还有一种叫按值查找。我已知一个 X X X,然后问你,这个 X X X 是在这个表的哪个位置,也就是返回这个结点的指针,即这个结点所在的地址。同样的也是一个链表遍历的一种基本方法。
对应代码如下
List Find( ElementType X, List PtrL )
{
List p = PtrL;
while ( p!=NULL && p->Data != X )
p = p->Next;
return p;
}
这两种操作的平均时间性能为 O ( n ) O(n) O(n)。
1.5 链式存储的插入和删除
1.5.1 插入操作实现
现在我准备在第 i − 1 ( 1 ≤ i ≤ n + 1 ) i-1(1≤i≤n+1) i−1(1≤i≤n+1)个结点后插入一个值为 X X X 的新结点,操作步骤为:
①先构造一个新结点,用
s指向;
②再找到链表的第i-1个结点,用p指向;
③然后修改指针,插入结点 (p之后插入新结点是s)
具体操作如图所示:
我们直接依次执行s->Next=p->Next和p->Next=s就能完成插入操作。注意操作顺序不能反,否则会导致s->Next指向s,从而不能正确完成插入。平均查找次数为 n / 2 n/2 n/2,平均时间性能为 O ( n ) O(n) O(n)

相应的代码如下:
List Insert( ElementType X, int i, List PtrL )
{
List p, s;
if ( i == 1 ) { /* 新结点插入在表头 */
s = (List)malloc(sizeof(struct LNode)); /*申请、填装结点*/
s->Data = X;
s->Next = PtrL;
return s; /*返回新表头指针*/
}
p = FindKth( i-1, PtrL ); /* 查找第i-1个结点 */
if ( p == NULL ) { /* 第i-1个不存在,不能插入 */
printf("参数i错");
return NULL;
}else {
s = (List)malloc(sizeof(struct LNode)); /*申请、填装结点*/
s->Data = X;
s->Next = p->Next; /*新结点插入在第i-1个结点的后面*/
p->Next = s;
return PtrL;
}
}
1.5.2 删除操作实现
现在我要删除链表的第 i ( 1 ≤ i ≤ n ) i (1≤i≤n) i(1≤i≤n)个位置上的结点,操作步骤如下:
①先找到链表的第
i-1个结点,用p指向;
②再用指针s指向要被删除的结点(p的下一个结点);
③然后修改指针,删除s所指结点;
④最后释放s所指结点的空间。
具体操作如图所示:
平均查找次数为 n / 2 n/2 n/2,平均时间性能为 O ( n ) O(n) O(n)。

相应代码如下:
List Delete( int i, List PtrL )
{
List p, s;
if ( i == 1 ) { /* 若要删除的是表的第一个结点 */
s = PtrL; /*s指向第1个结点*/
if (PtrL!=NULL) PtrL = PtrL->Next; /*从链表中删除*/
else return NULL;
free(s); /*释放被删除结点 */
return PtrL;
}
p = FindKth( i-1, PtrL ); /*查找第i-1个结点*/
if ( p == NULL ) {
printf("第%d个结点不存在", i-1); return NULL;
} else if ( p->Next == NULL ){
printf("第%d个结点不存在", i); return NULL;
} else {
s = p->Next; /*s指向第i个结点*/
p->Next = s->Next; /*从链表中删除*/
free(s); /*释放被删除结点 */
return PtrL;
}
1.6 广义表与多重链表
前面我们知道了一元多项式的一种表示方法,也就是里面只含一个变量 x x x。那我们就想一个问题:如果是二元多项式呢?也就是说我这里面含有两个变量。比方说我们看到的这样的一个例子: P ( x , y ) = 9 x 12 y 2 + 4 x 12 + 15 x 8 y 3 − x 8 y + 3 x 2 P(x,y) = 9{x^{12}}{y^2} + 4{x^{12}} + 15{x^8}{y^3} - {x^8}y + 3{x^2} P(x,y)=9x12y2+4x12+15x8y3−x8y+3x2。它怎么进行表示?
①一种处理方法就是可以把二元多项式看成是一个关于 x x x 的一元多项式 ,这样我们可以把前面的二元多项式经过重新整理变成这样: P ( x , y ) = ( 9 y 2 + 4 ) x 12 + ( 15 y 3 − y ) x 8 + 3 x 2 P(x,y) = (9{y^2} + 4){x^{12}} + (15{y^3} - y){x^8} + 3{x^2} P(x,y)=(9y2+4)x12+(15y3−y)x8+3x2。即 a x 12 + b x 8 + c x 2 a{x^{12}} + b{x^8} + c{x^2} ax12+bx8+cx2。
②在原来一元多项式里面,我们 x 12 x^{12} x12、 x 8 x^8 x8 相应的系数是常量。那在我们这里就不是常量了,也是一个一元多项式,所以我们可以形成这样的一种链表来表示,这种表我们称之为广义表。

广义表(Generalized List)的定义
广义表是线性表的推广
对于线性表而言, n个元素都是基本的单元素;
广义表中,这些元素不仅可以是单元素也可以是另一个广义表。
广义表的构造
在广义表构造的时候我们会碰到一个问题:一个域有可能是不能分解的单元,有可能是一个指针。那么这个问题怎么处理呢?C语言提供了一种手段,叫做联合 union,可以把不同类型的数据组合在一起。那么怎么区分不同的类型呢?一般的方法,就是设一个标记,根据这个标记,假如说这个标记等于0 ,就代表是单元素。1是代表一个指针,指向另外一张广义表。所以,广义表的单个元素结构如下图所示:

我们写出对应的广义表定义的代码如下:
typedef struct GNode *GList;
struct GNode{
int Tag; /*标志域:0表示结点是单元素,1表示结点是广义表 */
union { /*子表指针域Sublist与单元素数据域Data复用,即共用存储空间*/
ElementType Data;
GList SubList;
} URegion;
GList Next; /* 指向后继结点 */
};
接下来我们来看看多重链表,刚才我们看了那个广义表的例子,实际上它就是一个多重链表。它里面的一些结点即是关于 x x x 的一元多项式的一个结点,也是关于 y y y 多项式的一个结点。
多重链表:链表中的节点可能同时隶属于多个链
①多重链表中结点的指针域会有多个,如前面例子包含了Next和SubList两个指针域;
②但包含两个指针域的链表并不一定是多重链表,比如在双向链表不是多重链表。一个往前指,一个往后指,但实际上这两个指针所串起来的链表是同一个,无非是指向了结点的不同方向。
③多重链表有广泛的用途:基本上如树、图这样相对复杂的数据结构都可以采用多重链表方式实现存储
下面我们来看一个例子:矩阵怎么表示

矩阵可以用二维数组表示,但二维数组表示有两个缺陷:
①数组的大小需要事先确定,
②对于“稀疏矩阵 ”,将造成大量的存储空间浪费。所谓稀疏矩阵,就是说矩阵里面的0很多。一个很典型的例子 ,假如说我们想表示一个大学里面每个学生选了什么课程,什么课程是被哪些学生选的。所以我们可以用二维数组来表示选课的一种记录,比方说行代表课程、列代表学生。对一般学校来讲,学生可能有一两万人,课程可能有三四千门,所以这是一个巨大的矩阵。但是大家可以想象,在这个矩阵里面 0 是很多很多的 ,非零项是很少很少的。像这种矩阵,我们叫稀疏矩阵。
那么在我们这个稀疏矩阵里面能不能也存储非零项?我们先来看看非零项的信息是什么。
①非零项的信息主要是这么几样: A ( i , j ) A(i,j) A(i,j)的值Value、行坐标Row、列坐标Col。
②如果把这三个信息做成一个结点,由于它是个矩阵,矩阵即意味着行跟行之间、列跟列之间还有关系。那么怎么建立这样的关系?我们可以通过两个指针:一个Right、一个Down把行的元素串起来,同一行、同一列的元素串起来。
③这就是我们讲的用多重链表来表示稀疏矩阵的一种方法:十字链表。

我们来仔细分析下这个十字链表。
结点
①这里的结点总共有两种类型:Term(矩阵非0元素结点)类型和Head(头结点)类型。我们用一个标识域Tag来区分头结点和非0元素结点。
②这两个结构明显地不一样但是又有共性:都有两个指针,一个行方向,一个列方向。
③Term结点除了行列方向指针,还包含了行列位置和非零值
④Head节点除了行类方向指针,还包含了Next指针,指向下一个头结点
这些结点的结构如下图所示:
稀疏矩阵
这个稀疏矩阵的入口是一个Term类型结点,里面包含了稀疏矩阵的行和列数以及非零值的数量。同时连接了行和列的各个头节点。
可以看出头节点只有一个next指针,指向了一个行结点和一个列结点,因此对角线上对应的一对行结点和列结点是同一个。
Term类型它是有两个指针,一个是指向同一行的,一个是指向同一列的。这些指针把同一行同一列都设计成一个循环链表。
所以每个结点属于某一行也属于某一列,形成了这样的十字结构,所以我们叫十字链表。




小测验
1、对于线性表,在顺序存储结构和链式存储结构中查找第k个元素,其时间复杂性分别是多少?
A. 都是O(1)
B. 都是O(k)
C. O(1)和O(k)
D. O(k)和O(1)
答案:C
2、在顺序结构表示的线性表中,删除第i个元素(数组下标为i-1),需要把后面的所有元素都往前挪一位,相应的语句是:
for (___________ )
PtrL->Data[j-1]=PtrL->Data[j];
其中空缺部分的内容应该是
A. j = i; j< = PtrL->Last; j++
B. j =PtrL->Last; j>= i; j--
C. j = i-1; j< = PtrL->Last; j++
D. j =PtrL->Last; j>= i-1; j--
答案:A
3、下列函数试图求链式存储的线性表的表长,是否正确?
int Length ( List *PtrL )
{
List *p = PtrL;
int j = 0;
while ( p ) {
p++;
j++;
}
return j;
}
答案:错误

















 815
815











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











