







本系列文章为哈尔滨工业大学刘宏伟计算机组成原理学习笔记,前面的系列文章链接如下:
计算机组成原理:P1-计算机系统概述
计算机组成原理:P2-系统总线
计算机组成原理:P3-存储器(上)
一、只读存储器(ROM)
只读存储器的发展
早期的只读存储器----在厂家就写好了内容
这种适用于大批量的计算机或某种设备生产,实现了节约化,价格较低。但是对科研人员来讲,如果我们想研制一台新的机器,自己来编制系统程序、系统的配置信息,这种只读存储器就不合适了。
• 改进1:用户可以自己写----一次性
• 改进2:可以多次写----要能对信息进行擦除
• 改进3:电可擦写----特定设备
• 改进4:电可擦写----直接连接到计算机上
各类别的只读存储器
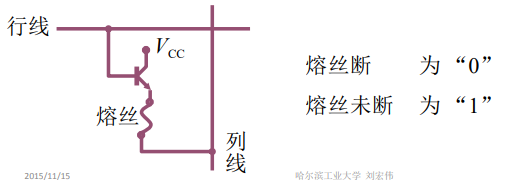
①掩模ROM(MROM)
行列选择线交叉处有 MOS 管为“1”
行列选择线交叉处无 MOS 管为“0”
②PROM(一次性编程)
这是一种破坏性的编程,如果程序有错误只能重新购买芯片进行烧写。
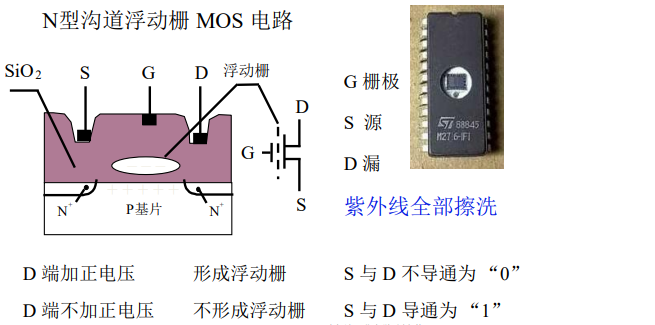
③EPROM(多次性编程)
每次使用紫外线对浮动栅进行擦洗。芯片上有个石英窗口,紫外线通过这个窗口对浮动栅的驱散操作。
④EEPROM(多次性编程)
电可擦写
局部擦写
全部擦写
⑤Flash Memory(闪速型存储器)
EPROM----价格便宜,集成度高
EEPROM----电可擦洗重写
比EEPROM----快,具备RAM功能
二、存储器与CPU的连接
CPU执行的指令、需要的数据、程序运行的结果都保存在主存储器中,因此必须实现CPU和主存储器的正确连接才能实现信息交换。通常情况下CPU的地址线条数较多,寻址空间的范围比较大,要构成一个主存储器需要多个存储芯片共同组成。
2.1 存储器容量的扩展
位扩展(增加存储字长)
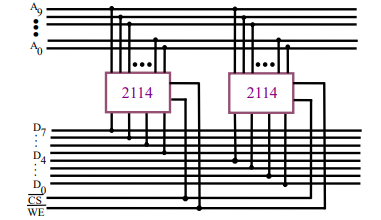
假设我们手上有1K×4位的存储芯片,用几个这样的芯片如何组成1K×8位的存储器?
我们的芯片:10根地址线,每个存储单元提供4位数据
构成的芯片:10根地址线,每个存储单元提供8位数据
使用两个芯片,使用相同的片选信号 C S ‾ \overline {{\rm{CS}}} CS(两个芯片同时被选中进行工作)、读写信号 W E ‾ \overline {{\rm{WE}}} WE(每次从两个芯片相同的位置取4位数据)。地址线还是10根,将地址线输入到两个芯片的地址管脚。数据线是8根,每个芯片占4根。
字扩展(增加存储字的数量)
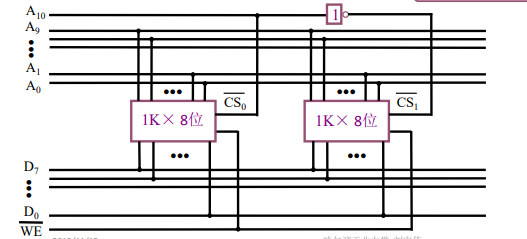
假设我们手上有1K×8位的存储芯片,用几个这样的芯片如何组成2K×8位的存储器?
我们的芯片:10根地址线,每个存储单元提供8位数据
构成的芯片:11根地址线,每个存储单元提供8位数据
两个芯片的地址管脚、数据管脚分别与10条地址线、8条数据线相连。两个芯片不能同时工作,否则存储字长就为16位了。于是我们将2K×8的存储器分成两个1K×8的芯片,由于还剩余了1条地址线,根据 A 10 \rm{A_{10}} A10是0/1来决定使用第一个还是第二个芯片。这样, A 10 \rm{A_{10}} A10就是这两个芯片的片选信号。
字、位扩展
假设我们手上有1K×4位的存储芯片,用几个这样的芯片如何组成4K×8位的存储器?
我们的芯片:10根地址线,每个存储单元提供4位数据
构成的芯片:12根地址线,每个存储单元提供8位数据
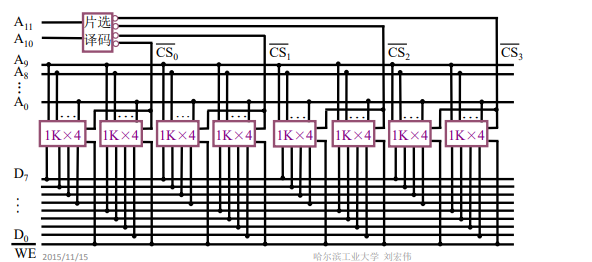
需要(4×8)/(1×4)=8个芯片。首先用两个1K×4位的芯片构成1个1K×8位的芯片,这两个芯片的片选是相同的。一共需要4组这样的芯片构成4K×8位的芯片。剩余的2根地址线用来做片选信号,根据00/01/10/11判断选择哪个芯片。
第一组芯片:000000000000~001111111111
第二组芯片:010000000000~011111111111
第三组芯片:100000000000~101111111111
第四组芯片:110000000000~111111111111
2.2 存储器和CPU的连接
例1:
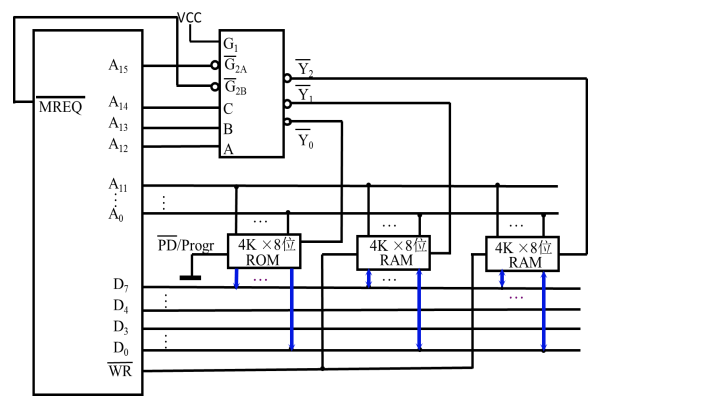
题目描述: CPU有16根地址线(寻址范围为 2 16 = 64 K \rm{2^{16}=64K} 216=64K),8根数据线(一次传输8bit数据),用 M R E Q ‾ \overline {{\rm{MREQ}}} MREQ作为访存控制信号(低电平有效:低电平时访问存储器,高电平访问I/O)。存储芯片RAM有1K×4位、4K×8位、8k×8位的,ROM有2K×8位、4K×8位、8k×8位的。现在我们要构成一个存储体,要求从6000到67FF是系统程序区,从6800到6BFF是用户程序区。同时,使用138译码器。
思路:
①写出对应的二进制地址码
地址线是16根,所以写成16位。
对于系统程序区,起始地址6000就是0110 0000 0000 0000。结束地址67FF就是0110 0111 1111 1111。所以,存储空间就是 0110011111111111 − 0110000000000000 = 2 11 = 2 K 0110 0111 1111 1111 - 0110 0000 0000 0000 = 2^{11}=\rm{2K} 0110011111111111−0110000000000000=211=2K
对于用户程序区,起始地址6800就是0110 1000 0000 0000。结束地址6BFF就是0110 1011 1111 1111。所以,存储空间就是 0110101111111111 − 0110100000000000 = 2 10 = 1 K 0110 1011 1111 1111 - 0110 1000 0000 0000 = 2^{10}=\rm{1K} 0110101111111111−0110100000000000=210=1K
② 确定芯片的数量及类型
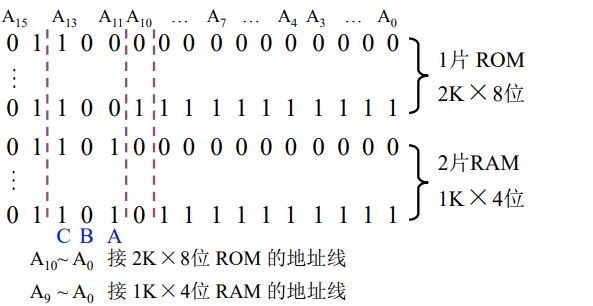
系统程序区选用ROM,只读。由于有2K×8的芯片,于是选用1片2K×8的芯片。
用户程序去选用RAM,可读可写。由于没有1K×8的芯片,我们使用2片1K×4的芯片,将片选信号连接起来即可。
③分配地址线
对于2K×8的ROM, A 0 \rm{A_{0}} A0- A 10 \rm{A_{10}} A10作为芯片需要的内部地址, A 11 \rm{A_{11}} A11- A 15 \rm{A_{15}} A15作为芯片选择信号。
对于2片1K×4的RAM, A 0 \rm{A_{0}} A0- A 9 \rm{A_{9}} A9作为芯片需要的内部地址, A 10 \rm{A_{10}} A10- A 15 \rm{A_{15}} A15作为芯片选择信号。
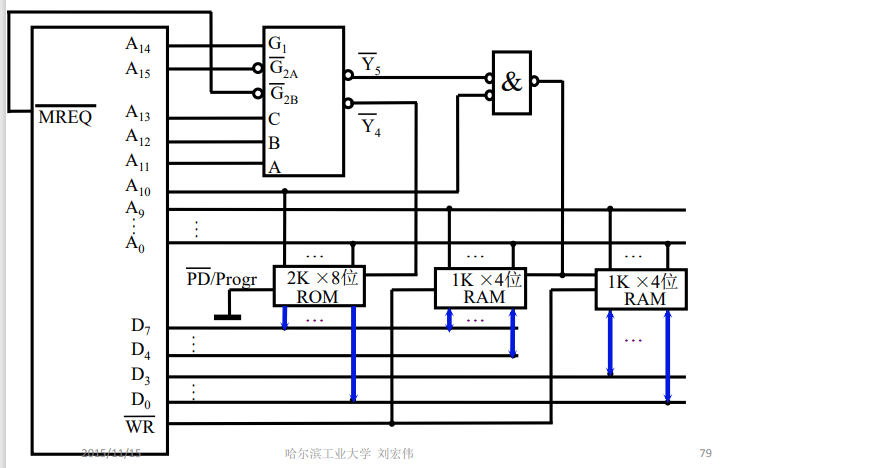
④分配片选信号并确定片选逻辑
现在要求我们使用138译码器,有3个输入C、B、A,3个控制信号 G 1 \rm{G_1} G1(高电平有效)、 G 2 A ‾ \overline {{\rm{G_{2A}}}} G2A(低电平有效)、 G 2 B ‾ \overline {{\rm{G_{2B}}}} G2B(低电平有效),2个输出 Y 4 ‾ \overline {{\rm{Y_4}}} Y4(低电平有效)、 Y 5 ‾ \overline {{\rm{Y_5}}} Y5(低电平有效)。
输入A、B、C直接连接到 A 11 \rm{A_{11}} A11- A 13 \rm{A_{13}} A13,对应输出 Y 4 ‾ \overline {{\rm{Y_4}}} Y4连接到ROM,输出 Y 5 ‾ \overline {{\rm{Y_5}}} Y5连接到RAM同时 A 10 \rm{A_{10}} A10要为低电平才能选中RAM。控制信号 G 1 \rm{G_1} G1高电平有效,所以连接到 A 14 \rm{A_{14}} A14。控制信号 G 2 A ‾ \overline {{\rm{G_{2A}}}} G2A低电平有效,所以连接到 A 15 \rm{A_{15}} A15。最后 G 2 B ‾ \overline {{\rm{G_{2B}}}} G2B还需要连,不要忘了低电平有效的 M R E Q ‾ \overline {{\rm{MREQ}}} MREQ,连接起来。最后,将ROM的编程端接地,读写信号线连接到RAM上。ROM和8条数据线连接,2片RAM分别连接4条数据线,ROM只能读出所以数据线是单向的。

例2:
题目描述: 假设同前,要求最小4K为系统程序区,相邻8K为用户程序区。
思路:
①写出对应的二进制地址码并确定芯片数量
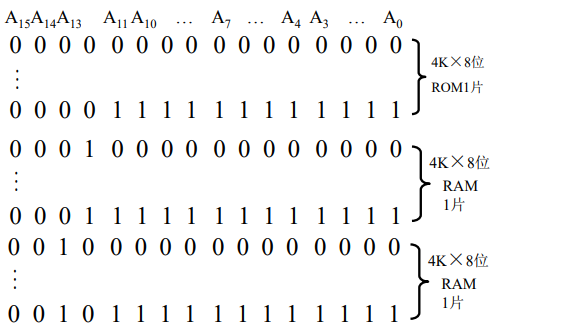
系统程序区是4K,于是使用 A 0 \rm{A_{0}} A0- A 11 \rm{A_{11}} A11,从0000 0000 0000 0000到0000 1111 1111 1111。由于有4K×8的ROM,所以使用1片4K×8的ROM。
用户程序区是相邻的8K,即从0001 0000 0000 0000开始。0001 0000 0000 0000到0001 1111 1111 1111是4K,于是再来1个4K构成8K,另外4K就是0010 0000 0000 0000到0010 1111 1111 1111。
②分配地址线
由于都是4K×8的芯片,于是需要的地址输入就是 A 0 \rm{A_{0}} A0- A 11 \rm{A_{11}} A11,我们可以从 A 11 \rm{A_{11}} A11到 A 12 \rm{A_{12}} A12之间划开。后面的 A 0 \rm{A_{0}} A0- A 11 \rm{A_{11}} A11给每一个芯片,前面的作为芯片选择信号。
③分配片选信号和片选逻辑
将 A 12 \rm{A_{12}} A12- A 15 \rm{A_{15}} A15作为输入分配给C、B、A。 G 1 \rm{G_1} G1(高电平有效)接电源(也可以将 A 15 \rm{A_{15}} A15接个非门再接上)、 G 2 A ‾ \overline {{\rm{G_{2A}}}} G2A(低电平有效)接 A 15 \rm{A_{15}} A15、 G 2 B ‾ \overline {{\rm{G_{2B}}}} G2B(低电平有效)接 M R E Q ‾ \overline {{\rm{MREQ}}} MREQ。ROM编程端接地,数据线是8根,方向是单向的。RAM数据线是8根,方向是双向的,并街上读写信号。
三、存储器的校验
3.1 校验原理
为什么要对存储器的信息进行校验?
以内存为例,它是电子设备,信息保存在电容中。如果是静态RAM,信息是保存在一个4管的触发器中。如果内存所处的电磁环境比较复杂或是在空间环境下受到带电粒子的打击,就可能会造成电容的充电/放电或触发器的翻转,存放在存储器中的信息就可能会出错。存储器中保存了程序运行需要的数据、代码等,如果不对保存的信息进行校验,就会导致程序的运行错误,引发程序失效和一些更大的后果。因此,我们需要对存储器的信息进行校验。现在不仅是一些安全关键系统需要对存储器进行校验,我们用的台式计算机、笔记本、手机、Pad里面保存的信息都采用校验技术。
为了能够校验出信息是否正确,如何进行编码?
例子:
①假设我们现在有这样一个合法代码集合{000,001,010,011,100,101,110,111},其中保存了从000到111的连续变化。现在假设000出错变成了001,而001仍然是集合中的合法代码。所以它是:检0位错、纠0位错
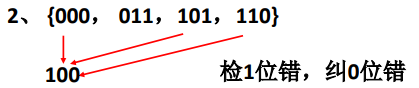
②下面我们对代码进行改造,现在的合法代码集只包含了4个代码{000, 011,101,110},编码特点是1的个数为0个或偶数个。如果000出错变成100,显然可以检测出错误,因为100不是合法代码集的代码。但是不能知道是那位错误,因为000、101、110错误一位都可以变成100。所以它是:检1位错、纠0位错
③假如我们采用3倍冗余的方式来存储计算机中的0和1,例如我们用000表示0,111表示1。 假设现在我收到了100,说明出错了,而存储器出错故障较多,可能是1位错、2位错、3位错。但是1位错的概率最大,甚至超过90%。因此根据收到的100,我们可以得到原始保存的应该是000。所以它是:检1位错、纠1位错
④假如我们采用4倍冗余,用0000表示0,1111表示1。此时如果收到1000,可以判断出原始值为0000,可以纠正1位错。如果收到1100,我们可以知道错了2位,但是无法纠正2位错误。所以它是:检2位错、纠1位错
⑤假如我们采用5倍冗余,用00000表示0,11111表示1。如果接受到11000,可以知道原始值是11000,检2位错,纠2位错。如果收到11100,检测不出3位错。所以它是:检2位错、纠2位错
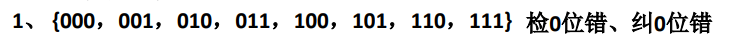



纠错或检错能力与什么因素有关?
与任意两组合法代码之间二进制位的最少差异数有关。从上面5个例子来看,1个合法代码变到另外一个合法代码分别要改变:0、2、3、4、5位。我们将任意两组合法代码之间二进制位的最少差异数称为编码的最小距离,编码的纠错 、检错能力与编码的最小距离有关。检错能力、纠错能力与编码最小距离的关系如下:
L − 1 = D + C ( D ≥ C ) L-1 = D + C(D≥C) L−1=D+C(D≥C)
L —— 编码的最小距离
D —— 检测错误的位数
C —— 纠正错误的位数
3.2 汉明码
汉明码
①汉明码采用奇偶校验
奇校验:1个校验位+原来的数据位,合在一起,使得代码中1的个数是奇数个。
偶校验:1个校验位+原来的数据位,合在一起,使得代码中1的个数是偶数个。
②汉明码采用分组校验
假设现在我们有8位的数据00100011,采用偶校验,则在前面加上个1,结果为100100011。当把数据取出来发现1的个数为奇数时,就知道有1位错了,但是不知道是这9位中哪一位错了。现在我们可以采用分组的方式来更加精确地定位出错误在哪一片区域。比如现在我们采用2位校验位,将数据分成2组,即0010和0011。加上校验位后,分别为10010和00011。如果收到数据时发现前面5位中1的个数为奇数,就知道前面5位有错。如果后面5位中1的个数为奇数,就知道后面5位有错。
③汉明码的分组是一种非划分方式
上面的分组方式是基于划分的方式,组和组之间没有重叠,各个组的数据合在一起就是要传输的数据。汉明码是一种非划分方式,组和组之间是有交叉的,即有些位属于多个组,有些位属于1个组。
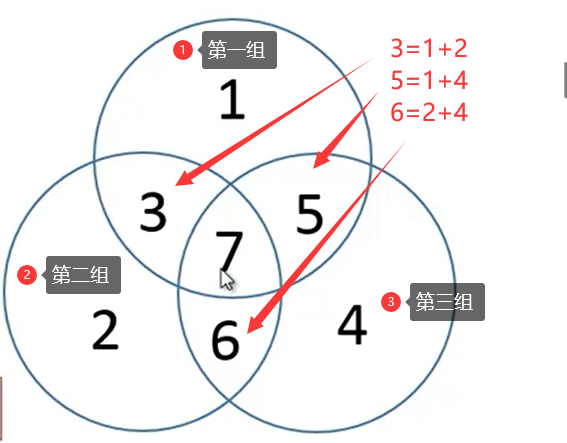
假设现在我们有1234567这7个数据,要分成3组,每组有1位校验位,共包括4位数据位。我们将1、2、4分别分给三个组,它们是各个组所独有的。然后再各个圈交叉的地方填上它们的和,最后将7填到中间的地方。
可以看出:有三组、每组4个数据、采用偶校验(每组数据和为偶数)。

校验出信息出错后是如何进行纠错?
假设现在 P 3 \rm{P3} P3、 P 2 \rm{P2} P2、 P 1 \rm{P1} P1分别代表这3组的校验结果。
如果没有任何差错,这三个结果都是0。
如果校验结果是001,说明第1组出错了,出错的地方就是第一组所特有的那个数据,就是1
如果校验结果是101,说明第3组和第1组出错了,而错1位的概率最大,因此出错的地方就是第3组和第1组公共的地方,就是5
如果校验结果是110,说明第3组和第2组出错了,而错1位的概率最大,因此出错的地方就是第3组和第2组公共的地方,就是6
如果校验结果是111,说明第3组、第2组、第1组出错了,而错1位的概率最大,因此出错的地方就是第3组、第2组、第1组公共的地方,就是7
校验位的位置:
校验位只对这一组校验,绝不会和其它组共有,所以这三组的校验位分别别为1、2、4
一个数据、一个位置应该被分到哪一组呢?
将每组数据转换成二进制数据。对于第1组数据,从右往左第1位就是1。对于第2组数据,从右往左第2位就是1。对于第3组数据,从右往左第3位就是1…以上就是对于每组数据,校验码所在的地方。


汉明码的组成
①汉明码的组成需增添多少位检测位
2 k ≥ n + k + 1 2^k ≥ n + k + 1 2k≥n+k+1,其中 k k k 为检测位的个数,即要分成的组数, n n n 为传输的信息位数
②检测位的位置
检测位放在 2 i ( i = 0 , 1 , 2 , 3 , . . . ) 2^i(i=0,1,2,3,...) 2i(i=0,1,2,3,...)
③检测位的取值
检测位的取值与该位所在的检测小组中承担的奇偶校验任务有关(是奇校验还是偶校验,没有特殊说明默认采用偶校验)
各检测位 C i C_i Ci 所承担的检测小组为
C 1 C_1 C1检测的 g 1 g_1 g1小组包含第 1,3,5,7,9,11, … 位置的二进制编码为X…XXX1
C 2 C_2 C2检测的 g 2 g_2 g2小组包含第 2,3,6,7,10,11,…位置的二进制编码为X…XX1X
C 4 C_4 C4检测的 g 3 g_3 g3小组包含第 4,5,6,7,12,13,…位置的二进制编码为X…X1XX
C 8 C_8 C8检测的 g 4 g_4 g4小组包含第 8,9,10,11,12,13,…位置的二进制编码为X…1XXX
独占和共享情况
g i g_i gi小组独占第 2 i − 1 2^{i-1} 2i−1位,位置的二进制编码为0…10…0
g i g_i gi和 g j g_j gj小组独占第 2 i − 1 + 2 j − 1 2^{i-1}+2^{j-1} 2i−1+2j−1位,位置的二进制编码为0…010…010…0
g i g_i gi和 g j g_j gj和 g l g_l gl小组独占第 2 i − 1 + 2 j − 1 + 2 l − 1 2^{i-1}+2^{j-1}+2^{l-1} 2i−1+2j−1+2l−1位,位置的二进制编码为0…010…010…010…0
例4
题目描述: 求 0101 按偶校验配置的汉明码
思路:
①由于n=4,根据 2 k ≥ n + k + 1 2^k ≥ n + k + 1 2k≥n+k+1得k=3,即需要分3组(3个校验位)
②对汉明码进行排序:
第1组、第2组、第3组的校验码 C 1 C_1 C1、 C 2 C_2 C2、 C 4 C_4 C4分别位于第 2 0 = 1 2^0=1 20=1、 2 1 = 2 2^1=2 21=2、 2 2 = 4 2^2=4 22=4位上
C 1 C_1 C1检测的 g 1 g_1 g1小组包含第 1,3,5,7位,由于是偶校验,357位是011,所以 C 1 C_1 C1是0
C 2 C_2 C2检测的 g 2 g_2 g2小组包含第 2,3,6,7位,由于是偶校验,367位是011,所以 C 2 C_2 C2是1
C 4 C_4 C4检测的 g 3 g_3 g3小组包含第 4,5,6,7位,由于是偶校验,567位是101,所以 C 1 C_1 C1是0
③所以0101的汉明码为0100101
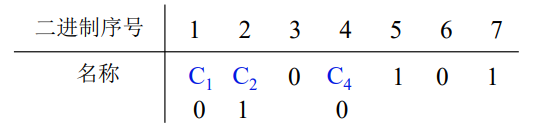
练习
题目描述: 求 0011 按偶校验配置的汉明码
思路:
①由于n=4,根据 2 k ≥ n + k + 1 2^k ≥ n + k + 1 2k≥n+k+1得k=3,即需要分3组(3个校验位)
②对汉明码进行排序:
第1组、第2组、第3组的校验码 C 1 C_1 C1、 C 2 C_2 C2、 C 4 C_4 C4分别位于第 2 0 = 1 2^0=1 20=1、 2 1 = 2 2^1=2 21=2、 2 2 = 4 2^2=4 22=4位上
C 1 C_1 C1检测的 g 1 g_1 g1小组包含第 1,3,5,7位,由于是偶校验,357位是001,所以 C 1 C_1 C1是0⊕0⊕1=1(三个数异或)
C 2 C_2 C2检测的 g 2 g_2 g2小组包含第 2,3,6,7位,由于是偶校验,367位是011,所以 C 2 C_2 C2是0⊕1⊕1=0
C 4 C_4 C4检测的 g 3 g_3 g3小组包含第 4,5,6,7位,由于是偶校验,567位是011,所以 C 1 C_1 C1是0⊕1⊕1=0
③所以0011的汉明码为1000011
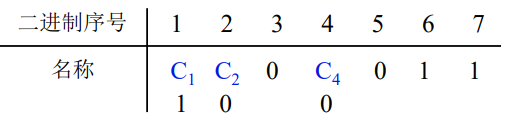
汉明码的纠错过程
接收方接收到数据后要进行纠错的话,发送方和接收方之间就要有协议,告诉接收方是用的汉明码,采用偶校验。在接收端,要形成新的检测位 P i \rm{P_i} Pi,其位数与增添的检测位有关,如增添3位(
k=3),新的检测位为 P 4 \rm{P4} P4 P 2 \rm{P2} P2 P 1 \rm{P1} P1。以k=3为例, P i \rm{P_i} Pi的取值为:
对于按偶校验配置的汉明码,不出错时 P 1 = 0 \rm{P_1}=0 P1=0, P 2 = 0 \rm{P_2}=0 P2=0, P 4 = 0 \rm{P_4}=0 P4=0
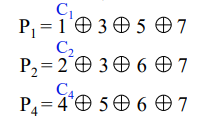
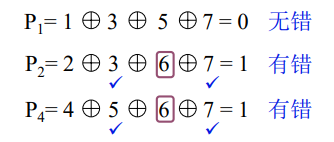
例5
题目描述: 已知接收到的汉明码为 0100111(按配偶原则配置)试问要求传送的信息是什么?
思路
纠错过程如下:新添3个检测位,并计算结果。可以看出 P 1 = 0 \rm{P1=0} P1=0,没有出错。而 P 2 \rm{P2} P2和 P 4 = 1 \rm{P4=1} P4=1,说明 P 2 \rm{P2} P2和 P 4 \rm{P4} P4有错。一般而言只有1位出错,所以 P 2 \rm{P2} P2和 P 4 \rm{P4} P4公共部分出错,所以就是第6位或者第7位。而第7位也属于 P 1 \rm{P1} P1,所以只能是第6位出错。
也可以直接将 P 4 \rm{P4} P4 P 2 \rm{P2} P2 P 1 \rm{P1} P1排在一起,结果为110。将其转换为10进制,结果为6,就是第6位出错。可纠正为0100101,故要求传送的信息为0101
练习
题目描述: 写出按偶校验配置的汉明码0101101的纠错过程
思路
纠错过程如下: 新添3个检测位,并计算结果。可以看出 P 1 = 0 \rm{P1=0} P1=0, P 2 = 0 \rm{P2=0} P2=0,没有出错。只有 P 4 = 1 \rm{P4=1} P4=1,说明 P 4 \rm{P4} P4有错,即第4位出错。(可以将 P 4 \rm{P4} P4 P 2 \rm{P2} P2 P 1 \rm{P1} P1排列,=100,转换成10进制就是4)
可以看出第4位是校验位,不是我们需要的数据,可不纠

练习
题目描述: 按配奇原则配置 0011 的汉明码
思路
①由于n=4,根据 2 k ≥ n + k + 1 2^k ≥ n + k + 1 2k≥n+k+1得k=3,即需要分3组(3个校验位)
②对汉明码进行排序:
C 1 C_1 C1 C 2 C_2 C2 0 C 4 C_4 C4 0 1 1
第1组、第2组、第3组的校验码 C 1 C_1 C1、 C 2 C_2 C2、 C 4 C_4 C4分别位于第 2 0 = 1 2^0=1 20=1、 2 1 = 2 2^1=2 21=2、 2 2 = 4 2^2=4 22=4位上
C 1 C_1 C1检测的 g 1 g_1 g1小组包含第 1,3,5,7位,由于是奇校验,357位是001,所以 C 1 C_1 C1是0
C 2 C_2 C2检测的 g 2 g_2 g2小组包含第 2,3,6,7位,由于是奇校验,367位是011,所以 C 2 C_2 C2是1
C 4 C_4 C4检测的 g 3 g_3 g3小组包含第 4,5,6,7位,由于是奇校验,567位是011,所以 C 4 C_4 C4是1
③所以 0011配奇的汉明码为 0101011
四、提高访存速度的措施
前面我们说过,CPU的计算速度每年增加约50%,而内存的访存速度要10年才能增加50%,所以不管你的CPU多块,只要你的内存访存速度过慢,也无法提高整机的速度。
提高访存速度的措施:
①采用高速器件:采用更高速的器件,让内存速度更快,带宽更大,访问延迟更小。
②采用层次结构,即Cache-主存结构:将最常用的信息放在Cache中,Cache由静态RAM做的,速度快,集成度低,功耗大。
③调整主存结构
这一节我们主要学习如何调整主存结构。在之前我们假设主存中的一个存储字长等于机器字长,也就是说CPU在执行一条指令的时候,一次只能从存储器中取出一条指令。如果是取数据,就只能取出和机器字长相等长度的数据。
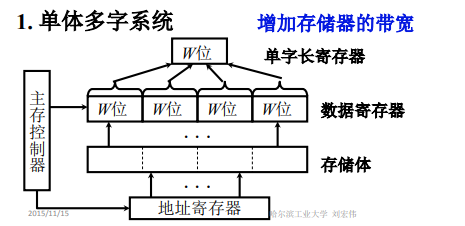
单体多字系统
我们可以将存储器的存储字长进行加长。假设CPU的机器字长是16位,我们可以将存储器的存储字长设置为64位。这样一次就可以取出4条指令或4倍的数据,然后将这些指令和数据放到数据寄存器中,下次需要时就从寄存器中取出。
优点:增加了存储器的带宽
缺点:①CPU如果要向存储器写一个16位的字, 它要将这个字先写到单字长寄存器中,然后再写道4个字长的数据寄存器中,之后再写到存储器中。这就会导致可能我们只需要写16位,但是另外48位也会被写到给定的单元,导致原来的那48位数据被修改掉。②如果我们要取的指令或数据不是连续存放在相邻的地址中,现在我们一次取出4条指令,但是这4条指令中的第1条指令就是跳转指令,而且跳转的范围较大,超出了这4个字的范围,那我们取出来的这4条指令只有1条是有用的。
多体并行系统
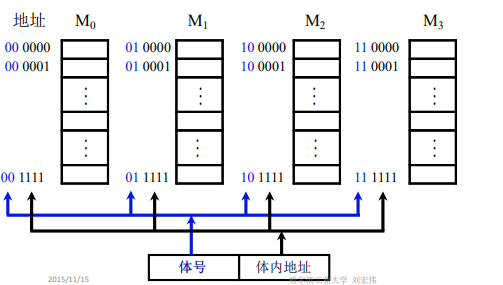
----高位交叉
假设我们现在有4个存储体,我们对4个存储体构成的存储器进行编址。假设每个存储体是16个单元,对于M0,地址就是0000~1111,然后再在前面加上两位00,用于标志是第几个存储体。总结,用6位来表示地址,前面2位是体号,后面4位代表体内地址。如果每一个存储体都有自己的控制电路,如MAR、MDR、地址译码器,那么4个存储体就能进行并行的工作了。
问题:如果用户在使用一个程序,而程序在计算机中是按序存储的,比如现在有15条指令放在00 0000~00 1111。这就会导致CPU会一直去访问第一个存储体,使其非常繁忙,而后面几个存储体没有被并行运用起来。
总结:上面的高位交叉看着很熟悉,实际上就是我们之前学的存储器的容量扩展,所以它适用于容量扩展,不适用于速度扩展
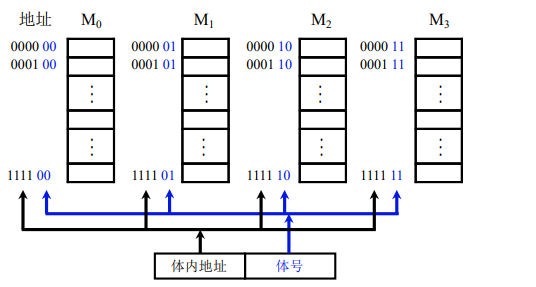
----低位交叉
现在我们改变编码方式,横向进行编码。这样的话,最低的两位就代表体号,高4位就代表体内地址。假设现在我们是执行一段程序,有4条指令,他就是横向存储在4个存储体中,0000 00,0000 01,0000 10,0000 11
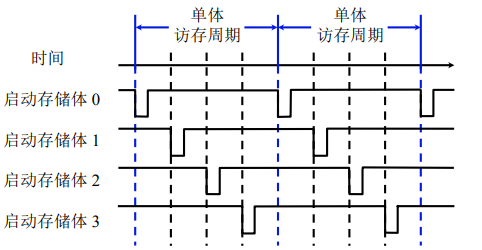
低位交叉的特点
在不改变存取周期的前提下,增加存储器的带宽。在一个访存周期期间,以流水的方式去访问各个存储体。
设四体低位交叉存储器,存取周期为T,总线传输周期为符号τ,为实现流水线方式存取,应满足T=4τ,连续读取4个字所需的时间为T+(4-1)τ
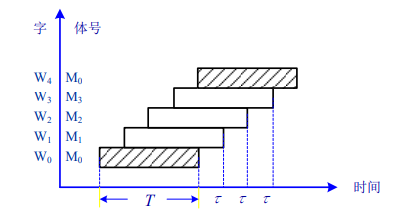
总结
高位交叉用于存储器容量扩展
地位交叉用于存储器带宽和访问速度提高
高性能存储芯片
(1) SDRAM (同步 DRAM)
在系统时钟的控制下进行读出和写入,CPU 无须等待
(2) RDRAM
由 Rambus 开发,主要解决 存储器带宽 问题
(3) 带 Cache 的 DRAM
在 DRAM 的芯片内 集成 了一个由 SRAM 组成的Cache ,有利于 猝发式读取















 5341
5341











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











