







CS231N斯坦福计算机视觉公开课 02 - 损失函数和优化
一、SVM铰链损失函数
分类错误的分数减去分类正确的分数再加1,比较这个数和0的大小关系,取最大值
- 猫猫的SVM loss为:max(0 , 5.1 - 3.2 + 1) + max(0,- 1.7 - 3.2 + 1) = 2.9+0 = 2.9

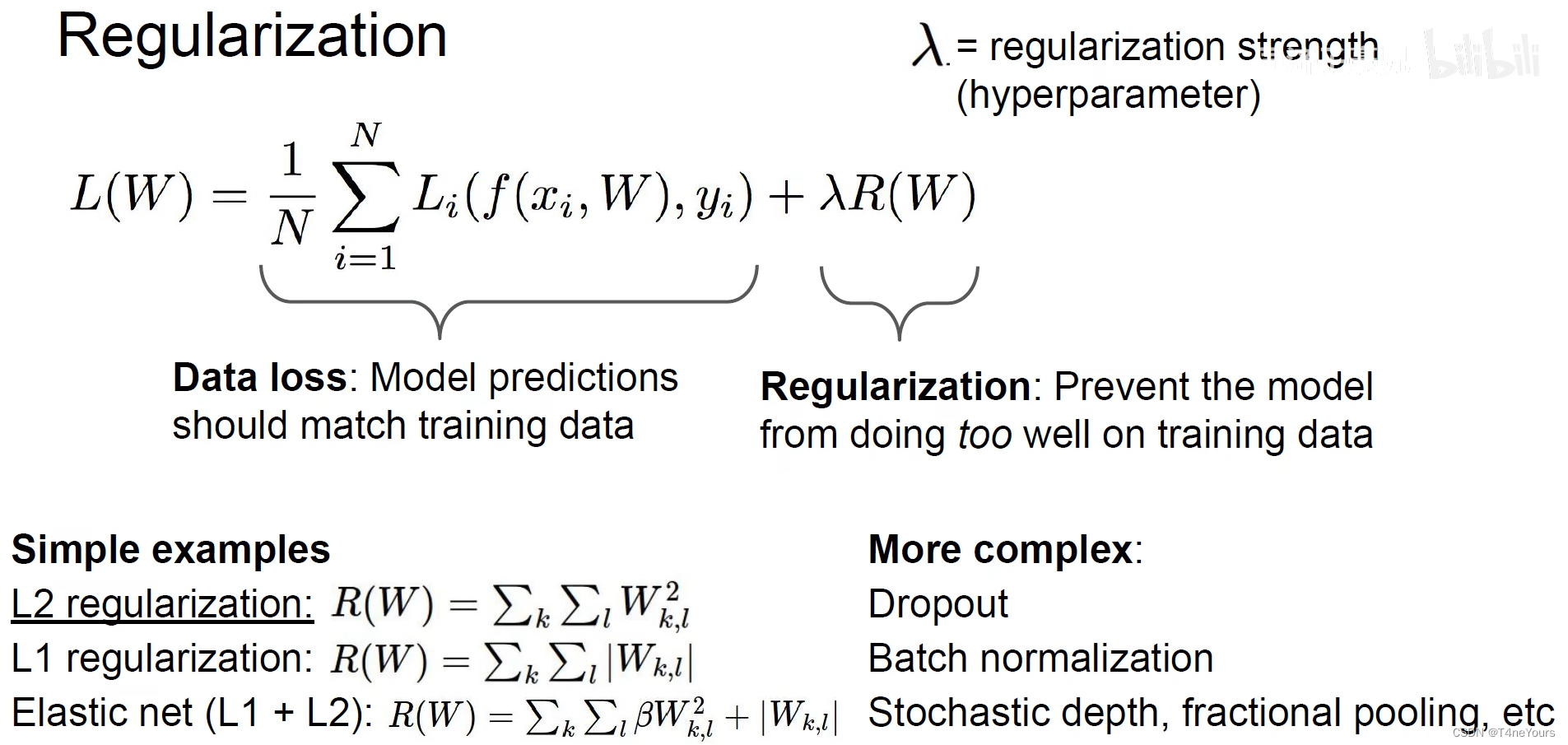
二、正则化
1.引入原因
- 由于同一个损失函数可以有多种变形算法(如将所有分数乘以2后再进行SVM loss计算),但是我们需要的是最简单的计算方法,所以我们引入正则化的概念
- 正则化可以让权重、模型在测试集上更好的泛化
正则化:
- 在常规损失函数的项后添加一个正则化的项,用正则化参数 λ \lambda λ 表示正则化的强度
- 一些正则化方法
- L1、L2正则化,以及它们的线性组合
- Dropout正则化……
举例:
- 我们得到了 w 1 w_1 w1、 w 2 w_2 w2两个权重向量,他们与输入的 x x x的乘积是相同的
- 但是引入L2正则化函数后,计算出来的正则化项中, w 1 w_1 w1对应的正则化项还是1, w 2 w_2 w2对应的正则化项是 0.2 5 2 ∗ 4 0.25^2*4 0.252∗4,明显小于1,所以我们可以选出像 w 2 w_2 w2这样较为平均的权重,而不是像 w 1 w_1 w1这样一家独大的权重

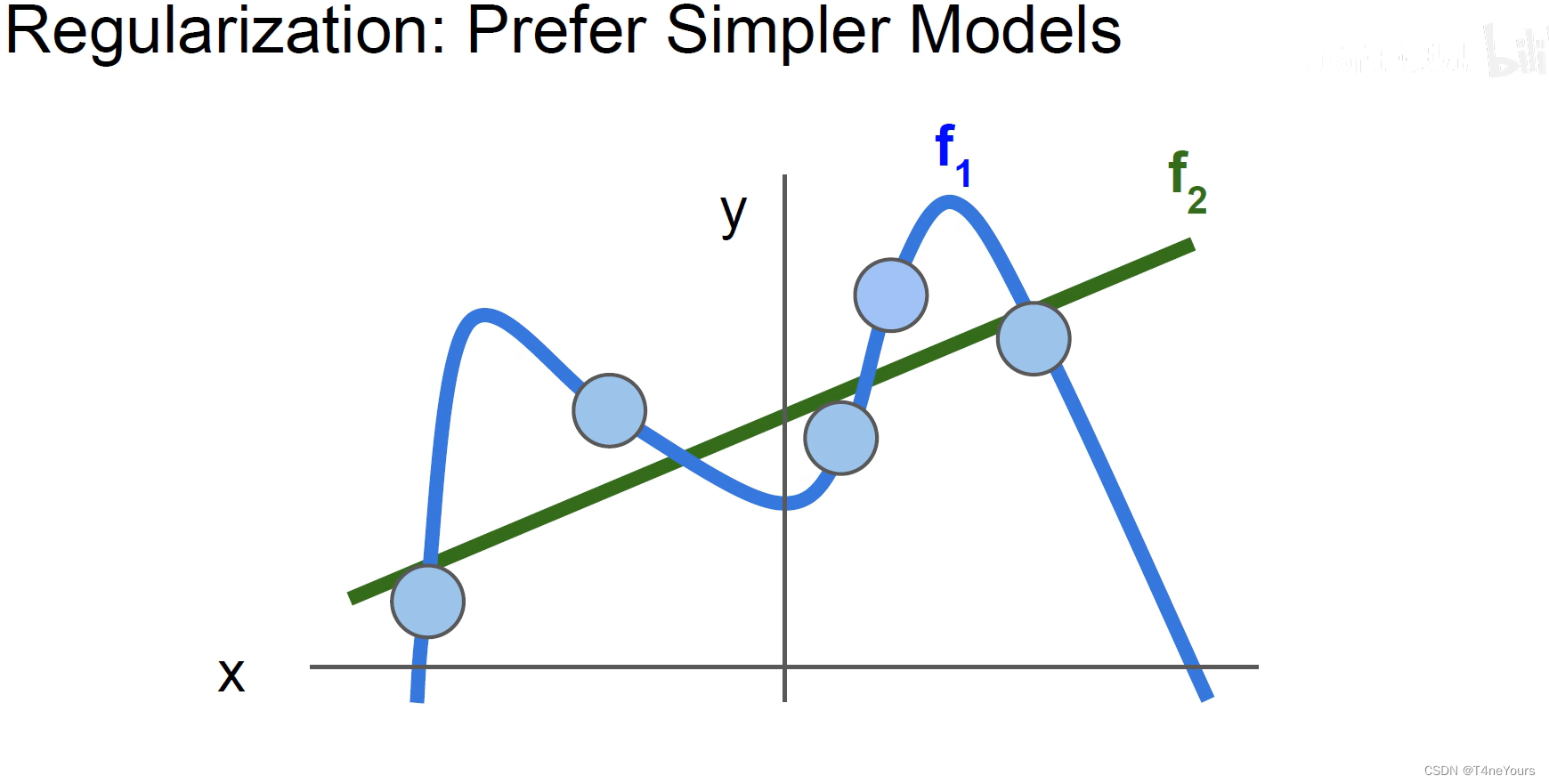
可以把上述的 w 2 w_2 w2看做是下图中的 f 2 f_2 f2,把上述的 w 1 w_1 w1看做是下图汇总的 f 1 f_1 f1,往往更简单的模型的泛化能力更强(此图也可以帮助理解泛化能力的含义),也可以有效的防止过拟合
三、Softmax交叉熵损失函数
工作原理
- 首先将所有的分数作 指数变化
- 然后将变化后的分数做归一化(分子为该分数、分母为所有分数的和)
- 将正确的类别对应的分数作交叉熵损失函数(对数似然损失函数、负对数损失函数,一个意思),即-log(分数),此数值越接近于0,正确类别的分数越高

四、优化过程
1.梯度下降算法
- 求得损失函数对于每一个权重的梯度(偏导数),按照梯度的反方向乘以学习率去更新权重
- “下降”指的是使得损失函数下降,而不是使得梯度本身下降















 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









