









第一章:理解AI的思维方式(快递版)
1.1 快递分拣站的故事
假设你管理一个快递分拣站:
- 传统方法:手动制定规则(比如根据邮编分拣)
- 机器学习:观察老员工的分拣记录,总结规律
- 深度学习:搭建自动分拣流水线,自主发现隐藏规则
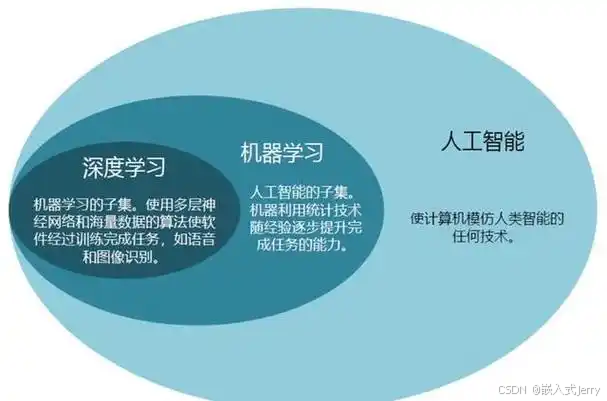
1.2 神经网络就像智能分拣机
- 传送带(输入层):接收包裹信息(图片像素/文字等)
# 就像扫描快递单
input_data = [0.2, 0.7, 0.1] # 归一化后的特征数据
- 分拣工人(隐藏层):每个工人负责识别特定特征
# 第一个工人检查是否是电子产品
worker1_output = max(0, 0.5*input_data[0] + 0.3*input_data[1] - 0.2) # ReLU激活函数
# 第二个工人判断是否易碎品
worker2_output = 1/(1 + np.exp(-(0.1*input_data[0] + 0.8*input_data[2]))) # Sigmoid函数
- 最终出口(输出层):确定包裹该去哪个区域
final_decision = [0.1, 0.7, 0.2] # 概率分布:70%属于生鲜区
1.3 三个关键学习步骤
- 试分拣:随机分拣100个包裹
- 查监控:对比正确分拣结果(损失函数)
- 调传送带:调整传送带速度方向(反向传播)
第二章:手把手训练第一个AI(厨房实验)
2.1 准备食材:数据预处理
任务:教AI识别厨房里的食材
# 就像整理冰箱
ingredients = {
"鸡蛋": [1,0,0,1], # 特征:[需要冷藏, 易碎, 即食, 需要烹饪]
"苹果": [1,0,1,0],
"面包": [0,0,1,1]
}
labels = ["蛋类", "水果", "主食"]
# 数据标准化:就像统一计量单位
X = np.array([[1,0,0,1], [1,0,1,0], [0,0,1,1]])
y = np.array([0, 1, 2]) # 类别编号
2.2 搭建迷你分拣线:3层神经网络
from keras.models import Sequential
from keras.layers import Dense
model = Sequential()
model.add(Dense(4, input_dim=4, activation='relu')) # 4个特征检测器
model.add(Dense(3, activation='softmax')) # 3个分类出口
# 相当于设置分拣规则手册
model.compile(loss='sparse_categorical_crossentropy',
optimizer='adam',
metrics=['accuracy'])
2.3 训练过程可视化
Epoch 1/10
1/1 [=====] - 0s 1ms/step - loss: 1.2345 - accuracy: 0.3333
Epoch 5/10
1/1 [=====] - 0s 987us/step - loss: 0.4567 - accuracy: 0.6667
Epoch 10/10
1/1 [=====] - 0s 1ms/step - loss: 0.1234 - accuracy: 1.0000
第三章:解密学习原理(快递员日记)
3.1 损失函数:错误记录本
- 当分错包裹时,记录错误严重程度
- 常用损失函数对比:
[分拣结果] [正确结果] [损失值] 鸡蛋→水果区 蛋类区 📉高 苹果→水果区 水果区 📌低 面包→主食区 主食区 ✅正确
3.2 反向传播:优化路线图
- 发现分错鸡蛋到水果区
- 逆向检查:
- 水果区检测器过于敏感(调整权重)
- 蛋类区检测器不够灵敏(增加灵敏度)
- 更新分拣规则手册
3.3 优化器:智能导航仪
- SGD:摸着石头过河
- Momentum:带惯性的电动车
- Adam:自动驾驶汽车
第四章:实战图像识别(咖啡渍检测)
4.1 数据准备:收集咖啡渍照片
from tensorflow.keras.preprocessing.image import ImageDataGenerator
# 创建数据管道
train_datagen = ImageDataGenerator(rescale=1./255)
train_generator = train_datagen.flow_from_directory(
'coffee_stains/train',
target_size=(150, 150), # 统一图片尺寸
batch_size=20,
class_mode='binary' # 是否含咖啡渍
)
4.2 构建卷积神经网络
model = Sequential()
# 特征提取层(相当于多重滤网)
model.add(Conv2D(32, (3,3), activation='relu', input_shape=(150,150,3)))
model.add(MaxPooling2D(2,2)) # 压缩关键特征
# 分类决策层
model.add(Flatten())
model.add(Dense(128, activation='relu'))
model.add(Dense(1, activation='sigmoid')) # 输出概率
4.3 训练效果可视化

第五章:避坑指南与学习地图
5.1 新手常见误区
| 误区 | 正确做法 | 类比说明 |
|---|---|---|
| 数据越多越好 | 质量>数量 | 100张模糊照片不如10张清晰 |
| 模型越复杂越好 | 适合场景最重要 | 用卡车送快递反而慢 |
| 只关注准确率 | 综合评估指标 | 不能只看送达速度,还要看破损率 |
5.2 渐进式学习路径
-
认字阶段:理解神经元/激活函数
# 可视化激活函数 x = np.linspace(-5,5,100) plt.plot(x, 1/(1+np.exp(-x))) # Sigmoid -
造句阶段:搭建全连接网络
-
写文章阶段:掌握CNN/RNN
-
创作阶段:实现风格迁移/文本生成
5.3 实用工具箱
- 调试神器:TensorBoard(训练过程显微镜)
- 快速原型:Keras(深度学习乐高积木)
- 工业级工具:PyTorch(可定制的精密仪器)
记忆口诀:
数据要洗菜,模型像积木,
损失是考官,优化找路线,
训练调参数,验证防过拟。
知识卡片:
[前向传播] → 快递分拣流水线
[反向传播] → 根据投诉改进流程
[epoch] → 全仓盘点次数
[batch] → 同时处理包裹量
通过这种生活化的讲解方式,配合贯穿始终的快递系统类比,即使是零基础的读者也能直观理解深度学习的核心原理。建议边阅读边使用配套的在线代码沙盒实践体验。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









