







If we compare the result of both ( “groupByKey” and “reduceByKey”) transformations, we have got the same results. I am sure you must be wondering what is the difference in both transformations. The “reduceByKey” transformations first combined the values for each key in all partition, so each partition will have only one value for a key then after shuffling, in reduce phase executors will apply operation for example, in my case sum(lambda x: x+y).
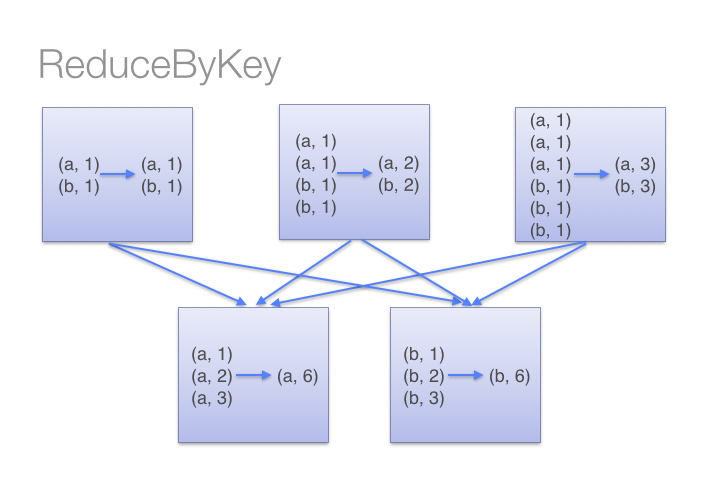
Source: Databricks
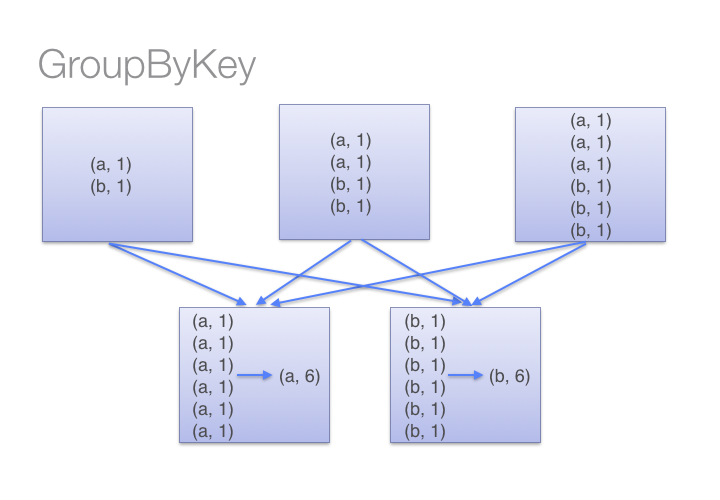
But in case of “groupByKey” transformation, it will not combine the values in each key in all partition it directly shuffle the data then merge the values for each key. Here in “groupByKey” transformation lot of shuffling in the data is required to get the answer, so it is better to use “reduceByKey” in case of large shuffling of data.















 983
983

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









