









系列文章目录
- 初识推荐系统——基于Spark平台的协同过滤实时电影推荐系统项目系列博客(一)
- 利用用户行为数据——基于Spark平台的协同过滤实时电影推荐系统项目系列博客(二)
- 项目主要效果展示——基于Spark平台的协同过滤实时电影推荐系统项目系列博客(三)
- 项目体系架构设计——基于Spark平台的协同过滤实时电影推荐系统项目系列博客(四)
- 基础环境搭建——基于Spark平台的协同过滤实时电影推荐系统项目系列博客(五)
- 创建项目并初始化业务数据——基于Spark平台的协同过滤实时电影推荐系统项目系列博客(六)
- 离线推荐服务建设——基于Spark平台的协同过滤实时电影推荐系统项目系列博客(七)
- 实时推荐服务建设——基于Spark平台的协同过滤实时电影推荐系统项目系列博客(八)
- 综合业务服务与用户可视化建设——基于Spark平台的协同过滤实时电影推荐系统项目系列博客(九)
- 程序部署与运行——基于Spark平台的协同过滤实时电影推荐系统项目系列博客(十)
项目资源下载
- 电影推荐系统网站项目源码Github地址(可Fork可Clone)
- 电影推荐系统网站项目源码Gitee地址(可Fork可Clone)
- 电影推荐系统网站项目源码压缩包下载(直接使用)
- 电影推荐系统网站项目源码所需全部工具合集打包下载(spark、kafka、flume、tomcat、azkaban、elasticsearch、zookeeper)
- 电影推荐系统网站项目源数据(可直接使用)
- 电影推荐系统网站项目个人原创论文
- 电影推荐系统网站项目前端代码
- 电影推荐系统网站项目前端css代码
文章目录
前言
由于前面的博客已经将系统的核心内容编写完毕,后面的任务就比较简单了,当然,这个系列的重点不在于后台与前端内容的编写,读者可以使用我的源码进行个性化修改,如果感兴趣可以增加或修改功能,针对这两部分内容,我只做简要说明,具体内容请参照源码。下面就开始今天的学习吧!
一、综合业务服务
1.1 后台架构
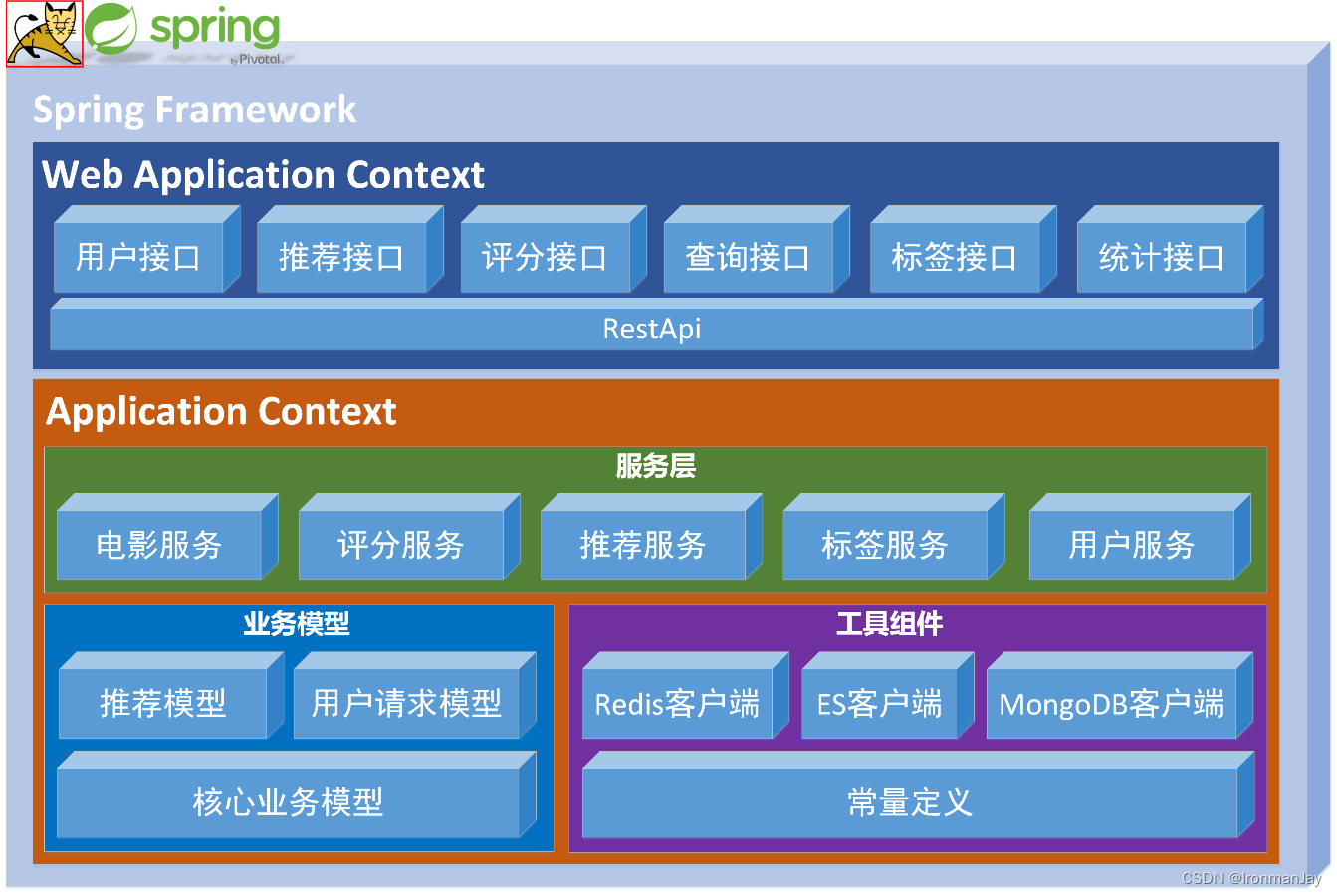
- 后台服务通过Spring框架进行创建,主要负责后台数据和前端业务的交互。项目主要分为REST接口服务层、业务服务层、业务模型以及工具组件等组成
- REST接口服务层,主要通过Spring MVC为UI提供了通讯接口,主要包括用户接口、推荐接口、评分接口、查询接口、标签接口以及统计接口
- 服务层主要实现了整体系统的业务逻辑,提供了包含电影相对应操作的服务、评分页面的服务、推荐层面的服务、标签层面的服务以及用户层面的服务
- 业务模型方面,将推荐、业务请求以及具体业务数据进行模型创建
- 工具组件层面,提供了对Redis、ES、MongoDB的客户端以及项目常量定义
二、用户可视化建设
2.1 前端架构
- AngularJS框架:
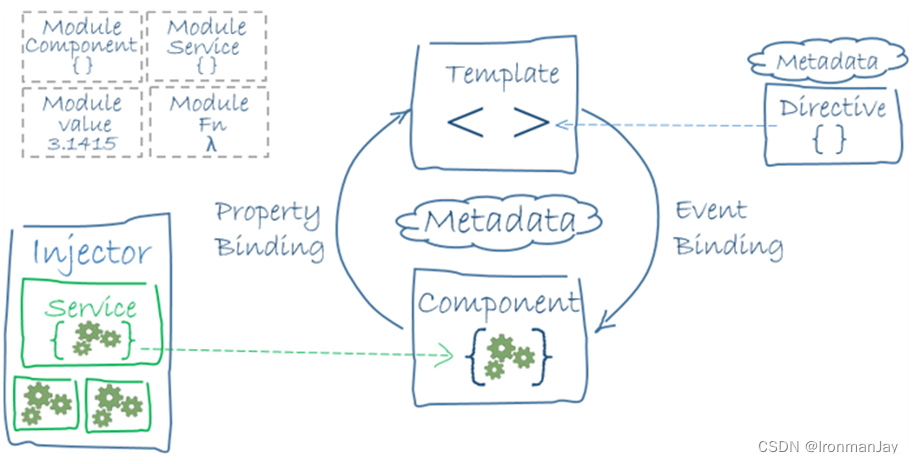
- 电影推荐系统前端框架:
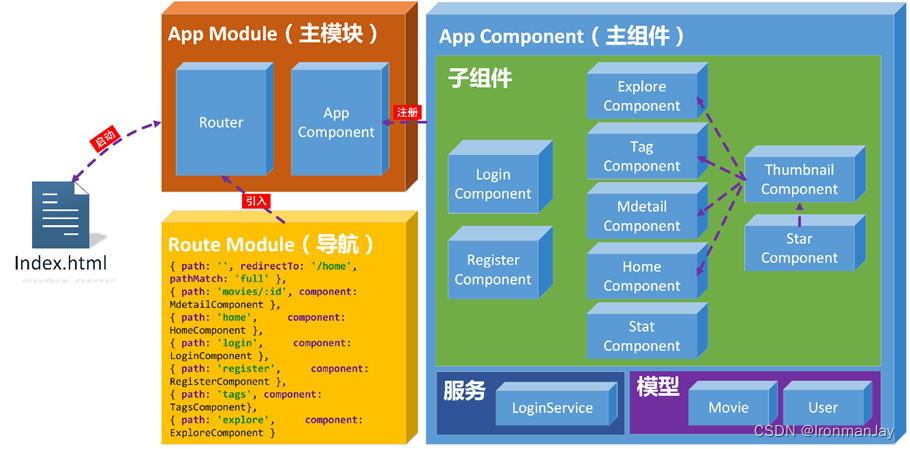
2.2 创建与运行项目
详细文档可参考:官方文档
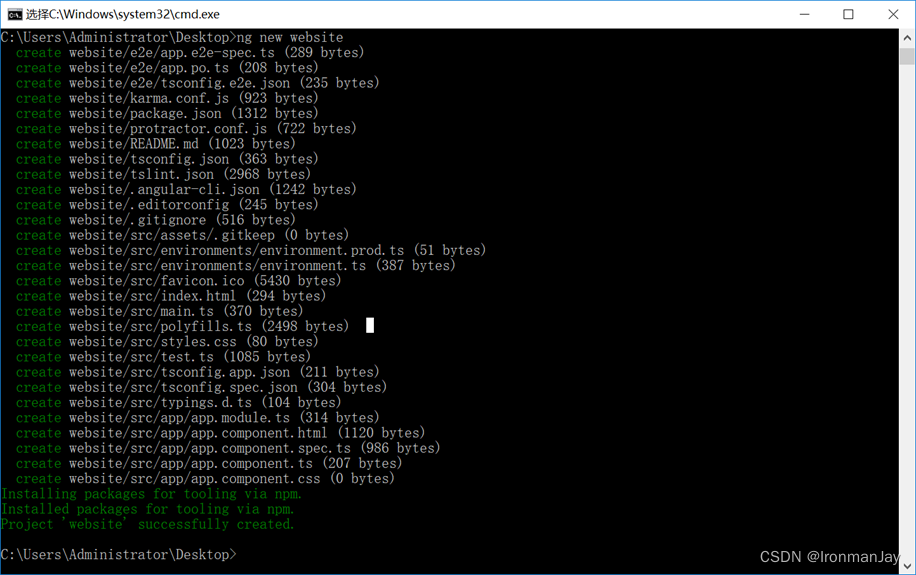
2.2.1 创建项目骨架
在CMD中相对应的目录中执行:ng new my-app,my-app 为项目的名称:
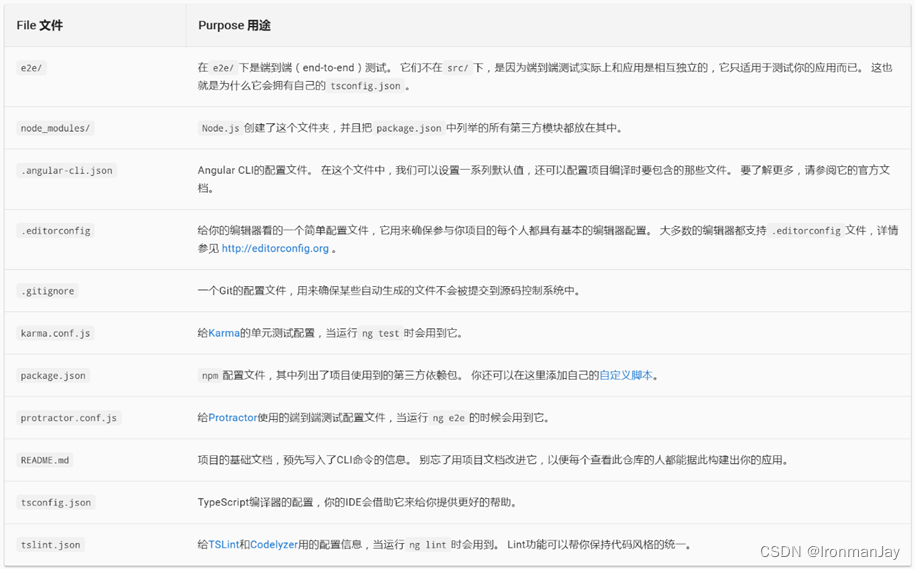
- Src主文件夹
你的应用代码位于src文件夹中。所有的Angular组件、模板、样式、图片以及你的应用所需的任何东西都在那里。这个文件夹之外的文件都是为构建应用提供支持用的


- 根目录文件夹
src/文件夹是项目的根文件夹之一。其它文件是用来帮助你构建、测试、维护、文档化和发布应用的。他们放在根目录下,和src/平级

2.2.2 添加项目依赖
- 在CMD的项目目录中执行:
npm install bootstrap --save,添加bootstrap依赖

- 在CMD的项目目录中执行:
npm install jquery --save,添加jquery依赖

- 在CMD的项目目录中执行:
npm install systemjs --save,添加systemjs依赖

2.2.3 创建模块、组件与服务
- 在CMD的项目目录中执行:
ng g module AppRouting,创建新模块

- 在CMD中项目目录中执行:
ng g component home,创建新组件

- 在CMD的项目目录中执行:
ng g service service/login,创建新服务器组件

2.2.4 调试项目
- 在CMD的项目目录中执行:
ng serve –p 3000,启动整个应用程序
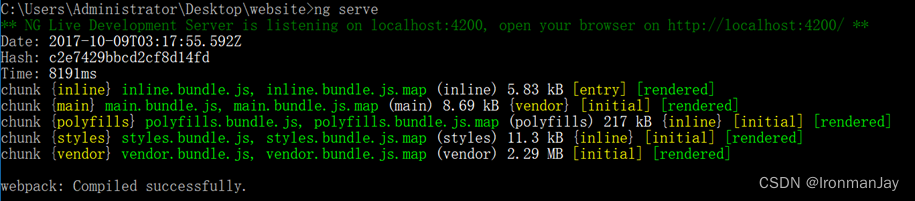
- 访问http://localhost:4200

当你修改了后台代码的时候,浏览器自动Reload
2.2.5 发布项目
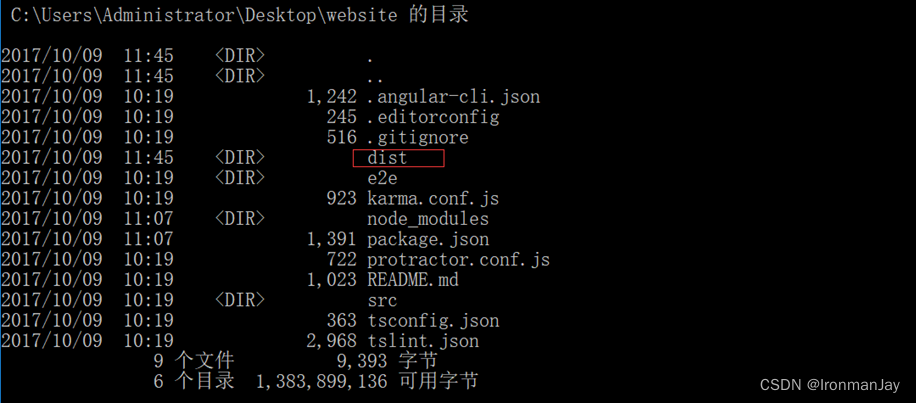
- 在CMD的项目目录中执行:
ng build,打包发布整个应用程序

- 会在目录下生成dist文件夹,该文件夹就是最终的发布程序
总结
这篇博文的结束也标志着这个系列博文也到了尾声,此篇博文我并没有详细讲解代码的编写,只是讲解了以下后台以及前端架构,并简单说了一下各种操作,因为本系列博文的重点不在于这部分,所以读者可根据自身需求斟酌使用源码即可。下篇博文将给大家带来本系列的最后一篇博文:程序部署与运行。那就下篇博文见啦!















 1542
1542











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











