






 该博客介绍了如何使用PyTorch搭建一个简单的两层全连接网络来预测姓名的性别。首先,从提供的数据集中读取并处理姓名,创建一个不重复的名称列表。接着,构建了一个两层神经网络模型,然后利用Dataloader加载数据并进行预处理。网络训练选择了均方误差损失函数MSELoss,进行了20个epoch的训练。最后,展示了如何使用训练好的模型对新的姓名进行预测。
该博客介绍了如何使用PyTorch搭建一个简单的两层全连接网络来预测姓名的性别。首先,从提供的数据集中读取并处理姓名,创建一个不重复的名称列表。接着,构建了一个两层神经网络模型,然后利用Dataloader加载数据并进行预处理。网络训练选择了均方误差损失函数MSELoss,进行了20个epoch的训练。最后,展示了如何使用训练好的模型对新的姓名进行预测。
“根据姓名判断性别”实战。
1.数据读入及处理
本次实验数据取自该书提供的数据集,可自 [http://file.hankcs.com/corpus/cnname.zip] 下载
通过pandas读入展示:

1)将200000例训练集中的名字部分建立统计到一个没有重复的列表,并保存至“NameList.txt”。
import pandas as pd
test=pd.read_csv(r'cnname\train.csv',header=None)
name = ""
for i, line in test.iterrows():
name += line[0][1:] # 除去line[0][0]的姓的部分
name_set = set(list(name+'_'))
name_list = list(name_set)
with open('NameList.txt','w') as f:
f.writelines(name_list)# 保存词典 writelines()方法可以直接保存列表
2.网络搭建
本实验基于pytorch框架,搭建两层全连接层:
class Perceptron(nn.Module):
def __init__(self,inputsize,hiddensize,outsize):
super(Perceptron, self).__init__()
self.linear = nn.Linear(inputsize,hiddensize)
self.linear2 = nn.Linear(hiddensize, outsize)
def forward(self,x):
x = torch.reshape(x, (20, -1)) # 20是后面一批数据的数据量(batchsize)
x = self.linear(x)
output = self.linear2(x)
return output
3.使用Dataloader载入数据
使用Dataloader前自建了类(不会创建类的可以借鉴 [https://blog.csdn.net/weixin_42468475/article/details/108714940])
def img_transform(img, label):
label = numpy.array(label)
img = torch.tensor(img)
label = torch.from_numpy(label)
return img, label,
def one_hot(line,t): #编码函数
temp = [0]*len(t)
if len(line[0])==3:
index1 =t.index(line[0][1])
index2 =t.index(line[0][2])
temp[index1]=1
temp[index2]=1
if len(line[0])==2:
index1 = t.index(line[0][1])
index2 = t.index('_')
temp[index1]=1
temp[index2]=1
if line[1]=='男':
label = [0,1]
else:
label = [1,0]
return temp,label
class Name(Dataset):
def __init__(self,train=True,transform=None):
test = pd.read_csv(r'D:\anaconda3\envs\newpytorch1\Lib\sitepackages\pyhanlp\static\data\test\cnname\train.csv',
header=None)
self.train = train
self.traindata =test
if self.train:
self.data = self.traindata
self.transform = transform
with open('NameList.txt', 'r') as f:
for t in f:
self.Namelist = t
def __getitem__(self, index):
data = self.data.iloc[[index]].values
data, label = one_hot(data[0], self.Namelist)
data, label = self.transform(data, label)
sample = {'data': data, 'label': label}
return sample
def __len__(self):
return int(len(self.data))
train_data = Name(True,img_transform)
BATCH_SIZE = 100
train_data = DataLoader(train_data, batch_size=BATCH_SIZE, shuffle=True, num_workers=1)
4.网络训练
损失函数选取均方误差函数MSE(mean squared error),CrossEntropyLoss()与MSELoss()相比
MSELoss()多用于回归问题,也可以用于one_hotted编码形式;CrossEntropyLoss()不用于one_hotted编码形式
MSELoss()要求batch_x与batch_y的tensor都是FloatTensor类型;CrossEntropyLoss()要求batch_x为Float,batch_y为LongTensor类型
net = Perceptron()
net = net.cuda()
criterion = nn.MSELoss().cuda()
optimizer = optim.Adam(net.parameters(), lr=1e-4)
print('-----------------------train-----------------------')
for epoch in range(20):
for i, sample in enumerate(train_data):
imgdata = Variable(sample['data'].float().cuda())
imglabel = Variable(sample['label'].float().cuda())
optimizer.zero_grad()
out = net(imgdata)
loss = criterion(out, imglabel)
loss.backward()
optimizer.step()
torch.save(net.state_dict(),'1.tar')
5.姓名预测
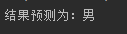
预测实例:“智瑞”
if __name__ == '__main__':
#main()
net = Perceptron()
net.load_state_dict(torch.load('1.tar'))
net = net.cuda()
with open('NameList.txt', 'r') as f:
for t in f:
temp = [0] * len(t)
index1 = t.index('智')
index2 = t.index('瑞')
temp[index1] = 1
temp[index2] = 1
temp = [temp for i in range(100)]
# print(temp,len(temp))
variablex = torch.tensor(temp, dtype=torch.float32)
variablex = variablex.float().cuda()
ans = net(variablex)
ans = ans.max(dim=1)[1].cpu().numpy()
if ans[0]==0:
print('结果预测为:女')
else:
print('结果预测为:男')


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









