



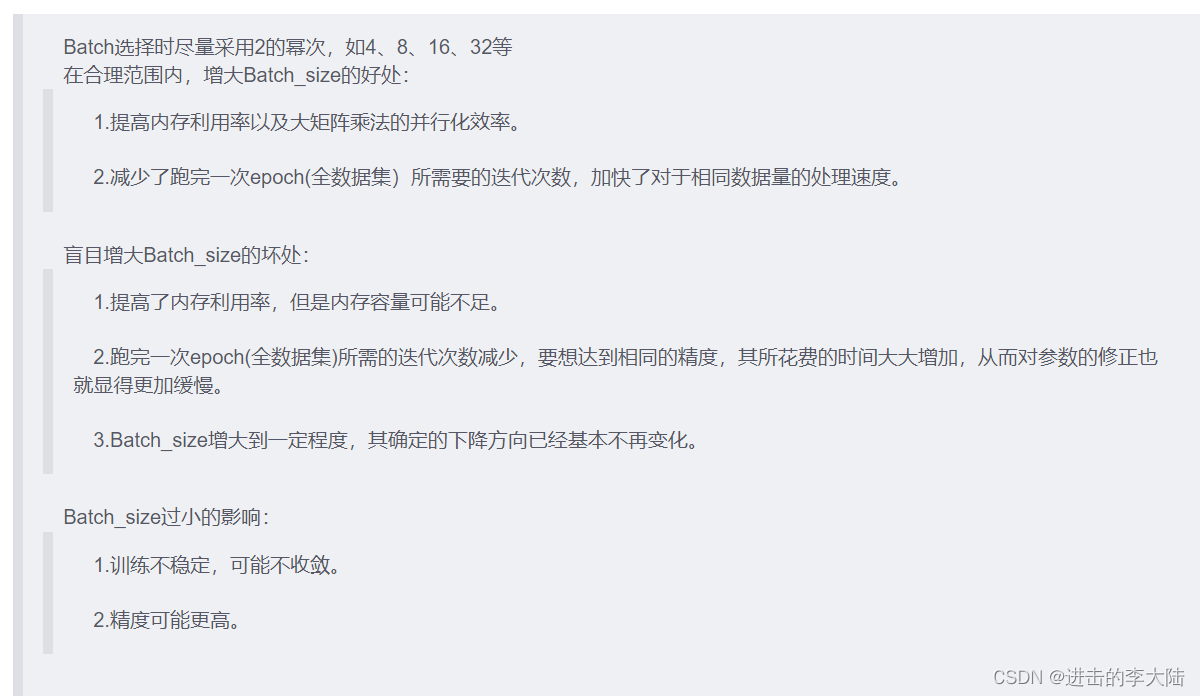
优化算法总结:
1.梯度下降法。
梯度下降法是原始的优化方法,梯度下降的核心思想:负梯度方向是使函数值下降最快的方向,因此我们的目标就是求取目标函数的负梯度。
在梯度下降法中,因为每次都遍历了完整的训练集,其能保证结果为全局最优(优点),但是也因为我们需要对于每个参数求偏导,且在对每个参数求偏导的过程中还需要对训练集遍历一次,当训练集很大时,计算费时(缺点)。

2.批次梯度下降法。
为了解决梯度下降法的耗时问题,批次梯度下降法在计算梯度时,不用遍历整个训练集,而是针对一个批次的数据。

3.随机梯度下降法。
再极端一点,就是随机梯度下降法,即每次从训练集中随机抽取一个数据来计算梯度。因此,其速度较快(优点),但是其每次的优化方向不一定是全局最优的(缺点)。因为误差,所以每一次迭代的梯度受抽样的影响比较大,也就是说梯度含有比较大的噪声,不能很好的反映真实梯度,并且SGD有较高的方差,其波动较大。而且SGD无法逃离鞍点。

4.Momentum随机梯度下降法
Momentum借用了物理中的动量概念,即前一次的梯度也会参与运算。为了表示动量,引入了一阶动量mm(momentum)。mm是之前的梯度的累加,但是每回合都有一定的衰减。
总而言之,momentum能够加速SGD收敛,抑制震荡。并且动量有机会逃脱局部极小值(鞍点)。

5.Nesterov动量型随机梯度下降法
Nesterov动量型随机梯度下降法是在momentum更新梯度时加入对当前梯度的校正,让梯度“多走一步”,可能跳出局部最优解。
相比momentum动量法,Nesterov动量型随机梯度下降法对于凸函数在收敛性证明上有更强的理论保证。
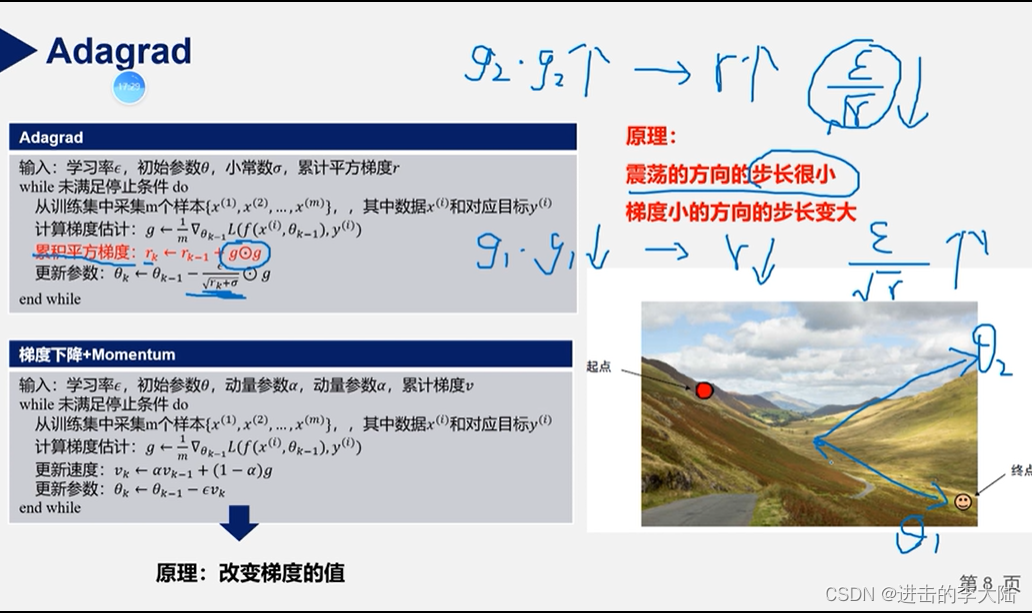
6.Adagrad法
SGD的学习率是线性更新的,每次更新的差值一样。后面的优化法开始围绕自适应学习率进行改进。Adagrad法引入二阶动量,根据训练轮数的不同,对学习率进行了动态调整。(解决稀疏梯度问题)
它能够对每个不同的参数调整不同的学习率,对频繁变化的参数以更小的步长进行更新,而稀疏的参数以更大的步长进行更新。
但缺点是Adagrad法仍然需要人为指定一个合适的全局学习率,同时网络训练到一定轮次后,分母上梯度累加过大使得学习率为0而导致训练提前结束。
7.RMSProp法
AdaGrad算法在迭代后期由于学习率过小,可能较难找到一个有用的解。为了解决这一问题,RMSprop算法对Adagrad算法做了一点小小的修改,RMSprop使用指数衰减只保留过去给定窗口大小的梯度,使其能够在找到凸碗状结构后快速收敛。RMSProp法可以视为Adadelta法的一个特例
RMSProp法缺陷在于依然使用了全局学习率,需要根据实际情况来设定。可以看出分母不再是一味的增加,它会重点考虑距离它较近的梯度(指数衰减的效果)。优点是只用了部分梯度加和而不是所有,这样避免了梯度累加过大使得学习率为0而导致训练提前结束。

8.Adam法
Adam法本质上是带有动量项的RMSProp法,它利用梯度的一阶矩估计和二阶矩估计动态调整每个参数的学习率。Adam法主要的优点在于经过偏置校正后,每一次迭代学习率都有一个确定范围,这样可以使得参数更新比较平稳。

虽然Adam算法目前成为主流的优化算法,不过在很多领域里(如计算机视觉的对象识别、NLP中的机器翻译)的最佳成果仍然是使用带动量(Momentum)的SGD来获取到的。Wilson 等人的论文结果显示,在对象识别、字符级别建模、语法成分分析等方面,自适应学习率方法(包括AdaGrad、AdaDelta、RMSProp、Adam等)通常比Momentum算法效果更差。

















 1647
1647

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









