






回归(Regression)
一,模型假设
有很多因素会决定我们想要的问题的答案。因此我们想要找到一个function,输入已知的影响因素的值(特征input),输出我们想要的数值output。
例:recommendation(ytb,tiktok,etc),self-driving car, stock market forecast…
再例:Combat Power of a pokemon!
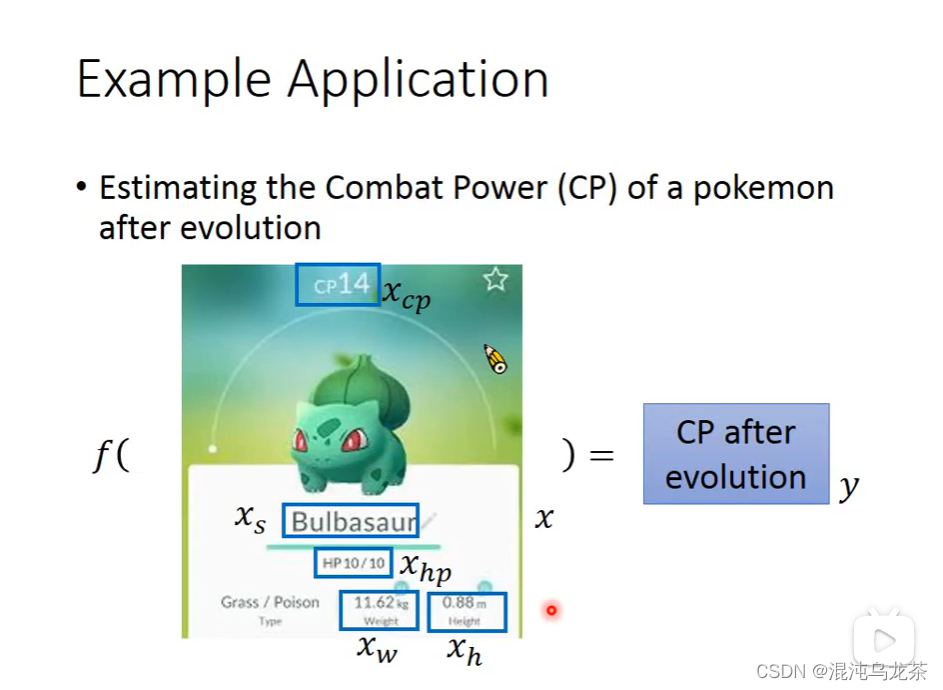
(由图可知,
x
s
x_s
xs,
x
w
x_w
xw 等值可能都会影响y的值。根据我们认为的影响因素的不同,我们可以写出很多function使所有x与y对应。)
二,模型评估
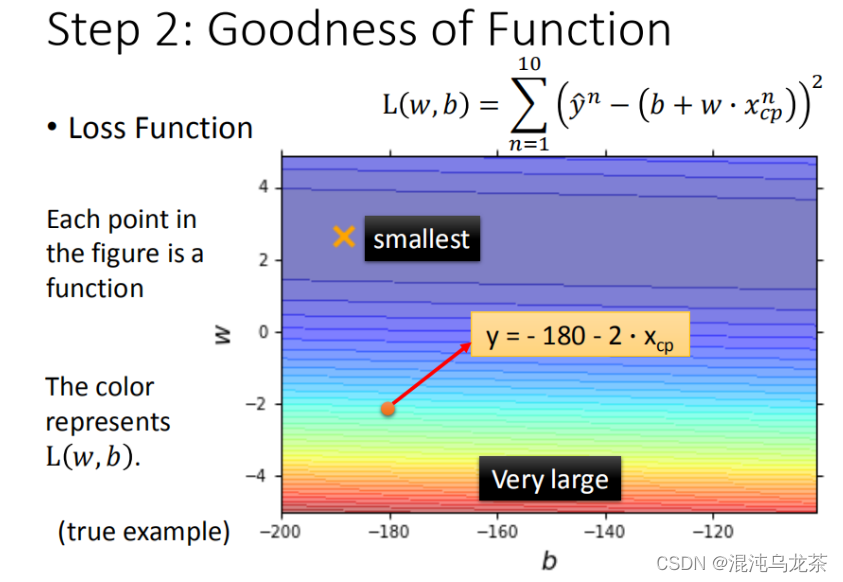
对于function的好坏,可以使用另一个function:loss function 来判断这个function好不好。即:
f
(
x
)
=
y
f(x)=y
f(x)=y
L
(
f
)
=
L
(
w
,
b
)
L(f)=L(w,b)
L(f)=L(w,b)

这里使用最常见的loss function:残差 来进行判断

对于loss function,也可以使用图像更加直接的展示。
三,模型优化
梯度下降(gradient descent)
现在我们相当于对于每一个假定的函数都有了一个评价。 那么如何根据这个评价找到最好的函数? 最暴力的方法是穷举,但是函数千千万,这样做非常没有效率。
因此使用梯度下降的方法进行寻找。只要是可微分的就可以进行gradient descent,这里涉及高等数学时的梯度的知识。
具体步骤
(和计算方法里面的欧拉法的思想有点像?)
当有一个参数时, 首先随机选取w0,(总之就是w0选取不固定),然后计算微分dl/dw(dl/dw:决定了下一步移动距离),根据微分值判断下一步寻找w值的移动方向。移动到w1处后,再重复上述实验步骤。
当有两个或多个参数时, 随机算取w0,b0,再计算出两个偏微分,然后再更新成w1,b1,再计算…
相当于在三维空间中寻找一个最低值 (参考:马同学如何直观形象的理解方向导数与梯度以及它们之间的关系?)
如果不是linear situation:能找到一个local optimal 但是找不到global optimal,但是线性:没事了(不会有local potimal的地方)

衡量error
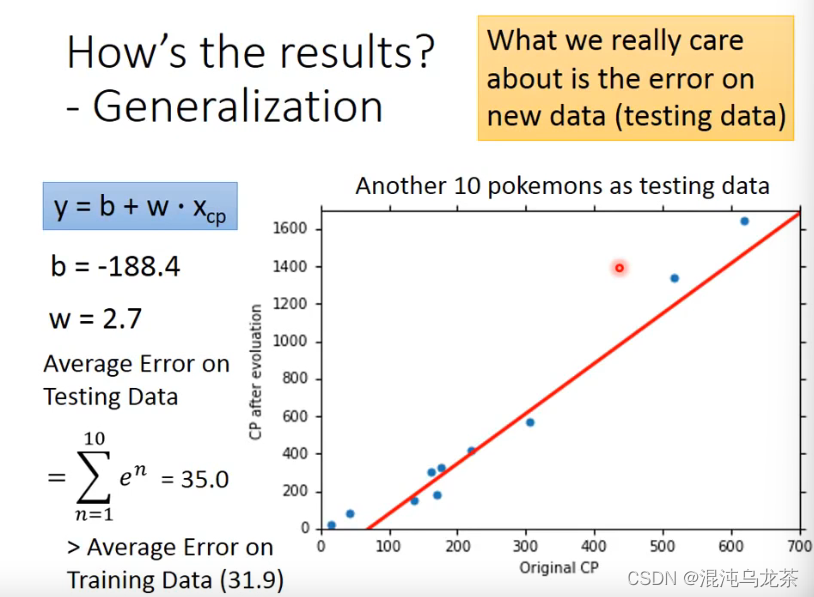
想要减少error:改进模型!
使用2次模型,得到了一个更好的结果(e更小。)
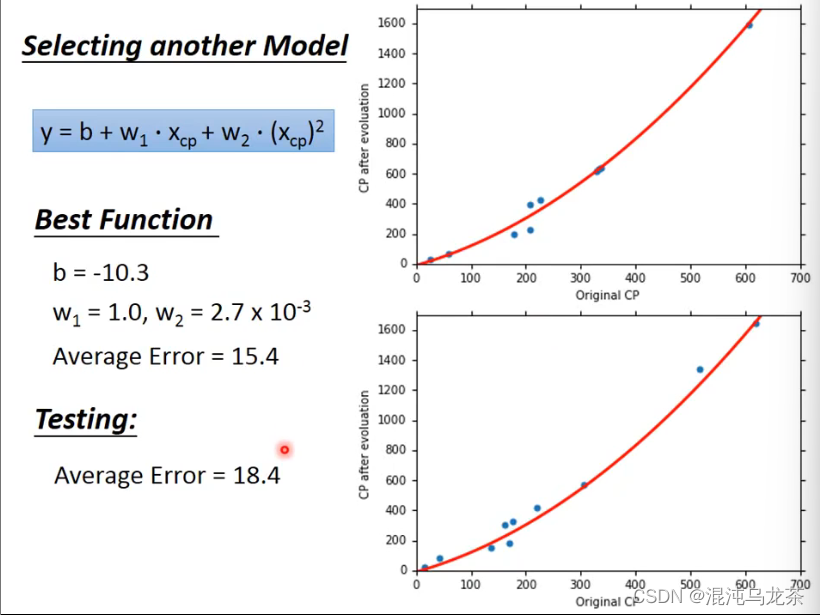
继续更改模型,尝试三次、四次模型…直到找到最好的一个。
过拟合
有的时候,一个非常复杂的model可能在training上结果很好,在testing上可能得不到一个好结果。
(之前我做物理储放能效率分析时多项式拟合到了10的9次方…老师说没有必要,当时我还不理解,其实那样的拟合也是没有什么实际意义的hh)
因此要结合testing和training来选择最好的值。当然也可能是因为数值太少才会导致这样
redesign
最后把一个小的function合成成大的function:(有点像拉格朗日插值法…)

如果不知道多个变量x与y之间的关系,就把所有的影响因素综合在一起尝试列一个特别复杂的式子。
但是复杂的model可能得到一个糟糕的testing error。
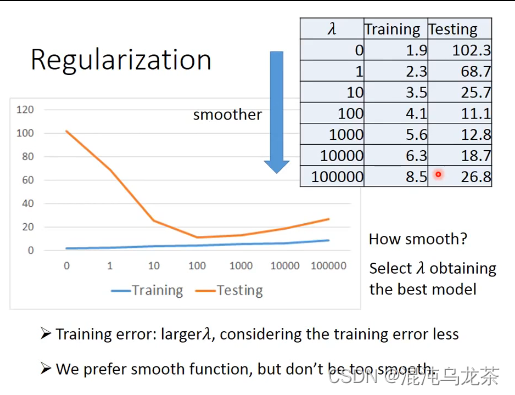
regularization

重新设计model function,更平滑的function对于输入数值的影响更小。
总结
决定一个函数时,考虑:
1 更smooth
2 error更小

3 我是鸽子(给我振作啊kora,)















 157
157











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









