







参考文献:Zhang X, Zhang C, Li X, et al. A survey of protocol fuzzing[J]. ACM Computing
Surveys, 2024, 57(2): 1-36.
注:本阅读笔记仅为个人记录,如有侵犯,联系作者删除
文章类型:协议模糊测试综述
Abstract
- 通信协议为互联网的基石,其中存在的漏洞构成了巨大的安全威胁
- 当前仍然缺乏对协议模糊测试有系统描述,如需要解决的问题和挑战
- 研究现有工作进行分类和概述,讨论未来潜在研究方向
1 Introduction
- 介绍通信协议和fuzzing技术的定义和作用
- 研究动机:1、协议无处不在至关重要,针对协议进行模糊测试有价值
2、通信协议本身错综复杂,协议模糊测试区别一般模糊测试。首先,需要遵守严格的规则,不仅规定了信息的结构,还规定了信息的顺序和上下文。其次,还需要考虑多种因素,例如时间和多个信息或操作如何同时发生。第三,协议在多个层面的广泛使用又增加一层复杂性。
3、对现有研究进行回顾,系统概述现状和未来方向。 - 第2节介绍协议模糊的背景知识,第3节介绍一般模糊目标和协议之间的主要区别,然后总结现有协议模糊器的主要改进。接下来的三节详细介绍了协议模糊每个关键部分的现有技术。第4节讨论了输入生成器组件的进展,第5节介绍了改进执行器组件的技术,第6节展示了用于错误检测器组件的谕令分类法,第7节介绍了未来的发展方向。
2 Background
2.1 Communication Protocols
- 通信协议是一套规则,可使通信系统中的两个或多个实体之间利用任何形式的物理量变化交换信息。通信协议的实施一般涉及多个阶段。
- 首先,对协议进行概念设计,包括根据协议的需要确定规则、行为和功能,同时考虑到效率、可靠性、可扩展性和安全性等因素。设计阶段的成果是一套规范。
- 然后,在开发阶段,将协议设计转化为具体实现。实现的形式可以是软件、硬件或两者的结合。开发完成后,协议要经过严格的测试,以确认其符合协议规范,并满足性能和可靠性要求。
- 最终,协议实施将被部署到实际环境中。
- 除了数据交换任务外,还包括路由选择、传输错误检测、超时和重试管理、确认、低控制和顺序控制等任务。
2.2 Types of Protocols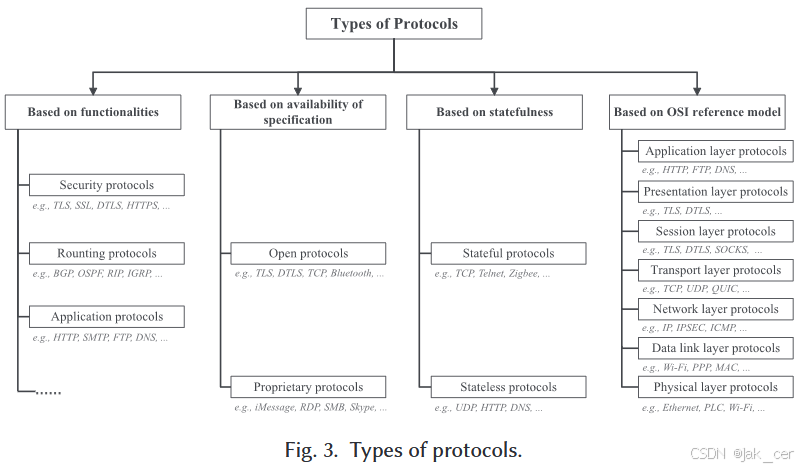
从不同角度对协议进行分类,分为基于功能、协议规范的可访问性、有无状态、OSI网络参考模型如图3分类
3 Protocol Fuzzing Overview
- 表现出更高的通信复杂性
- 测试环境相对更受限制
3.1 Differences between protocol fuzzing and traditional fuzzing
3.1.1 High communication complexity
- 在通信过程中符合语义限制,需要按照标准化的信息交换规则进行通信,涉及多轮过程,按照顺序执行才能成功交换,此类协议本质上通过有状态实现,每一个状态的通信建立在前一个状态的基础上。在真实环境中,在之前的约束条件没有得到满足之前,便不能对深层协议状态进行测试,这就是通信协议的固有的语义约束。语义约束又分为信息内约束和信息间约束,消息内约束设计单个消息的结构和内容,确保数据字段在该消息的上下文中语法正确、语义清晰。另一方面,报文间限制管理多个报文之间的关系和顺序。在通信过程中,违反任一类型的约束都会导致模糊处理无法进行。
- 测试通信过程中的不同性能,除了基本的信息交互功能外,协议还需要保证一系列附加功能协议还需要保证一系列附加功能,以形成更安全或更可靠的通信,如时间要求、身份验证、保密性和并发性。要有效测试实现中的这些属性,需要一种更复杂的测试形式,它超越了典型的应用程序模糊测试,后者主要侧重于改变结构化输入以发现问题。每个属性都可能需要对模糊框架进行重大修改甚至重新设计,包括开发专门的输入生成器、反馈机制和工具,以促进有效测试。例如检测协议实现中的 "放大攻击"(traic ampliication attacks)时,需要用数据库来识别不成比例的请求-响应数据量比率,这表明存在放大因子。目前,需要对输入生成器进行巧妙的重新设计,以生成协议信息的特定变化,从而最大限度地提高潜在的放大系数。此外,放大系数还可作为一种反馈,引导模糊器更有效地探索输入空间。
3.1.2 ConstrainedTesting Environment
- 由于协议与硬件之间的紧密耦合,协议模糊测试通常面临着一个受限的测试环境。首先,许多协议都是为低层物理设备之间的通信或专业领域的通信而设计的,如位于 OSI 参考模型低层(即物理层和数据链路层)的协议,或为汽车、工业控制系统(ICS)等专业领域设计的协议、电网和航空系统。在这些情况下,测试吞吐量将受到硬件依赖性的限制,如缺乏auotmation、可扩展模糊测试的瓶颈等。此外,这些物理依赖性也限制了高级模糊技术的应用。这是因为许多高级模糊技术需要测试目标提供灰盒或白盒测试信息,而由于这些特定硬件上缺乏程序分析框架,这些信息无法得到满足。
3.2 Summary of Existing Protocol Fuzzers
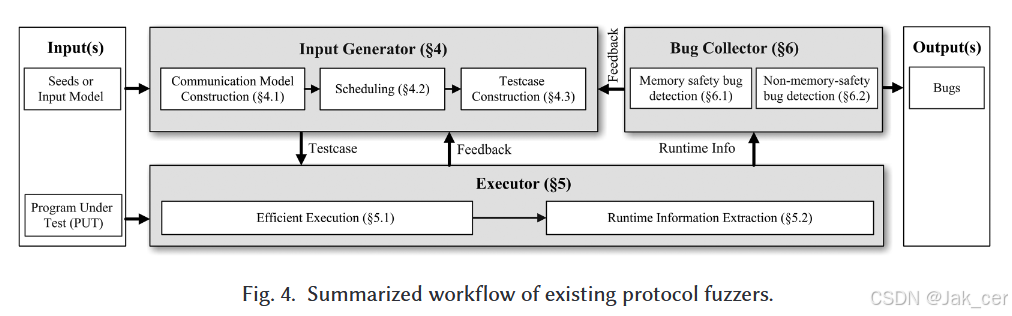
- 一般模糊器由三个基本组件组成,即输入生成器、执行器和错误收集器。
在一次模糊迭代中,输入生成器首先为执行器生成测试输入。
然后,执行器用给定的输入执行 被测程序,并为其他两个组件收集运行时信息。
最后,漏洞收集器检查运行时信息,以确定输入是否触发了漏洞。 - Input generator组件负责生成输入,以尽可能有效地暴露被测程序内部的漏洞,协议模糊器通常通过三个主要子阶段实现输入生成器,包括通信模型构建、调度和测试用例构建。
- Executor为了寻求理想的协议模糊执行器,当代研究主要集中在两个关键方面:高效执行和运行时信息提取。前者探索开发一种高效、自动化和可扩展的测试环境,以增强协议测试的执行能力。后者侧重于创建一个分析环境,以提取重要的运行时信息。
- Bug collector组件的主要目标有两个:增加其可检测漏洞类型的多样性,并提高这些检测的准确性。该组件经过精心调整,可以细致地识别各种漏洞,从 bufer 重叠等内存安全漏洞到逻辑错误和违反规范等更微妙的非内存安全漏洞。
4 Input Generator
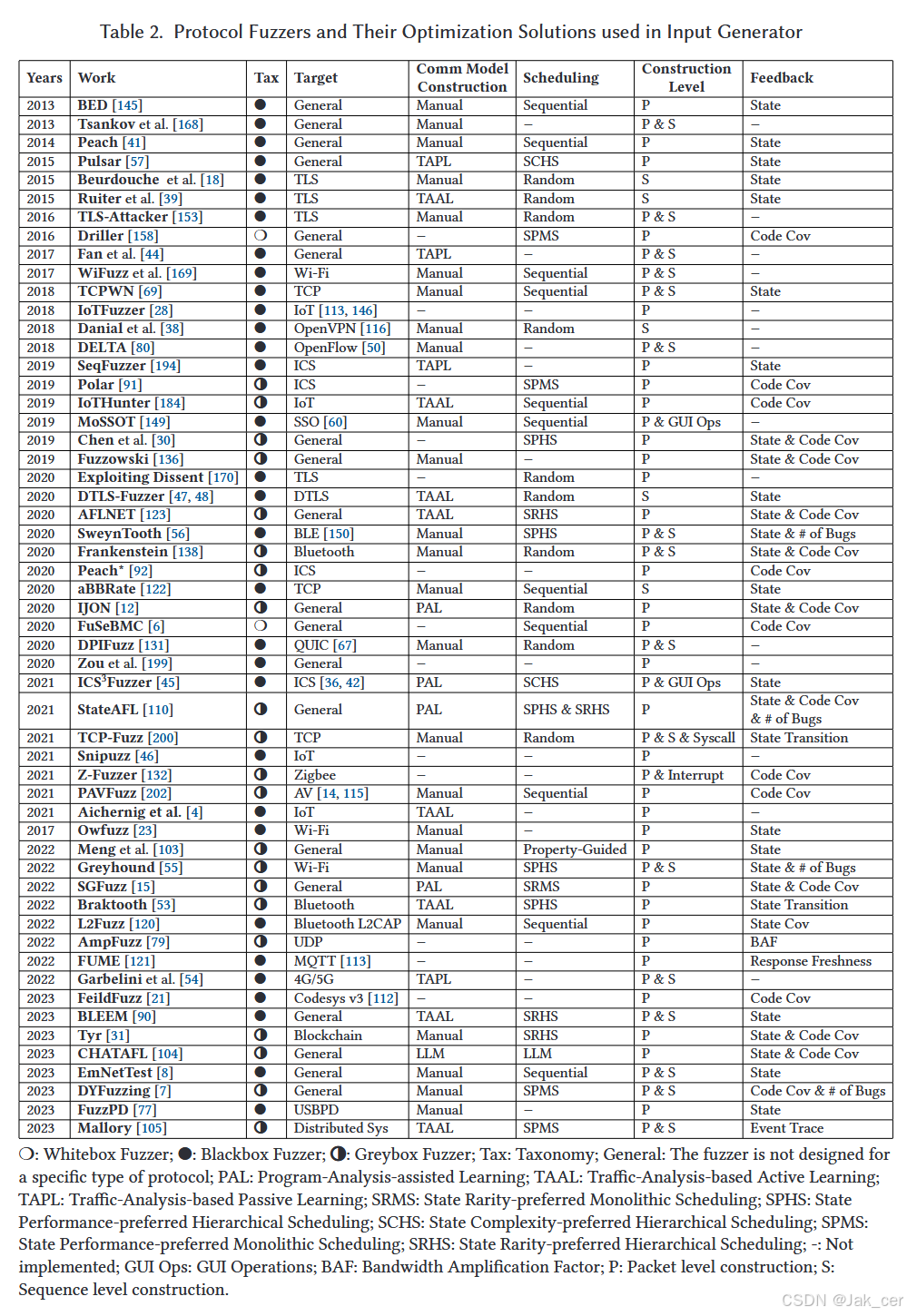
表2总结了在设计输入生成器的三个关键阶段的现有工作中使用的技术
4.1 Communication Model Construction
- 要利用语义约束增强传统模糊器,需要开发一个协议通信模型来指导模糊过程。这种通信模型包括状态模型和数据模型。状态模型详细说明了不同协议状态之间的转换,而数据模型则规定了驱动这些状态转换的信息格式和结构。
- 现有研究将协议的通信模型表示为状态机或其变体。状态机是描述协议实现的内部状态转换的数据结构。状态机可以用有向图来表示,如确定性现场自动机(DFA)或 Mealy 机器。在这些图中,节点代表实体的内部状态,而边则代表接收或发送特定类型消息所引起的状态转换。通过参考通信模型,协议模糊器可以了解当前的目标状态,并根据当前状态下可接受的消息类型数据模型生成测试用例,从而提高测试用例的有效性。一个协议实现可能有多个通信模型,因为它的行为可能因其工作模式或配置而不同。
例如,Wi-Fi 设备可配置为以 AP 模式、STA 模式或 P2P 模式运行,SIP 实现可配置为客户端、服务器或代理,它们对请求的反应各不相同,因此具有不同的通信模型。大多数现有工作都将这些以不同配置运行的实现视为不同的目标:他们为一个给定配置构建一个通信模型。 - 根据通信模型的构建方法对现有工作进行分类。如图 5 所示,分为两类:(i) 自上而下的方法和 (ii) 自下而上的方法。
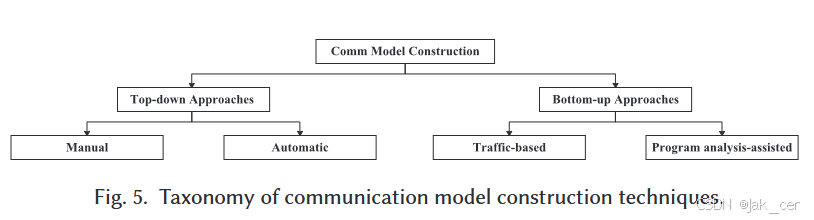
4.1.1 Top-Down Approaches
- 自顶向下方法通过学习协议的文本描述(如规范或文档)来构建协议通信模型。该方法需要协议规范作为输入,因此多用于开放式协议。得益于规范中的全局协议知识以及精确定义的状态和转换,自顶向下方法构建的通信模型相对完整和准确。值得注意的是,构建的通信模型仍可能与实现的通信模型不同。因为开发人员可能会根据实际情况定制或扩展规范中描述的设计。这种差异可能会影响最终的模糊性能。在方法上,从协议文档中构建通信模型有手工和自动两种方法。
- Manual Construction
- 大多数现有作品都是通过大量领域专业知识手动构建通信模型。
例如,Garbelini 等人和 GREYHOUND参照协议规范的核心设计,构建了蓝牙低功耗(BLE)和 Wi-Fi 的整体状态机,以指导模糊测试。虽然手动构建状态机是一项容易出错且劳动密集型的任务,但它的好处在于人类专家可以对状态机进行灵活定制(裁剪或扩展),以最大限度地提高其对工作目标的影响。
例如,为了检测不同协议模式(如不同的协议版本、扩展、认证模式或密钥交换方法)之间不正确的复用所导致的状态机错误,Beurdouche 等人手动构建了一个复合状态机,其中包括跨协议模式的所有有效状态转换。然后使用该复合状态机生成偏差跟踪,作为发现无效状态转换的测试用例。
同样,FuzzPD经过精心设计,以适应 USB 电源传输协议(USBPD)固有的独特双角色特性,即每个设备同时充当电源和电源槽。通过整合这两种角色的状态机,FuzzBD 能够在模糊处理过程中支持电源角色的无缝切换。 - 与上述工作不同,有些工作选择学习状态机的部分信息作为指导。
Zou 等人提出的 TCP-Fuzz 是一种从 RFC 文档中手动提取 15 条依赖规则的新方法。这些规则包含各种依赖关系,包括数据包到数据包、系统调用到数据包以及系统调用到系统调用的交互。利用这些规则,TCP-Fuzz 可以同时生成相互依赖的数据包和系统调用,从而巧妙地生成测试用例。
另一个例子是 L2Fuzz。作者构建了一个映射,划定了与协议中确定的 19 种状态中每种状态相关的有效命令。这种映射有助于生成专门定制的测试用例,以产生当前状态下可接受的命令,从而提高测试过程的相关性和有效性。 - 一些研究还解决了规范与实现之间的通信模型不完全相同的问题。
以异构单点登录(SSO)平台为例,MoSSOT 首先构建了常规 SSO 流程的状态机,然后分析不同 SSO 平台的实际 SSO 网络痕迹,以了解实现细节,如每个动作中的关键参数。这些实现细节决定了不同 SSO 平台状态机中的状态转换条件。
- 大多数现有作品都是通过大量领域专业知识手动构建通信模型。
- Automatic Construction
- 为了将手动构建通信模型这一容易出错且耗费大量人力的过程自动化,一些研究成果自动从协议规范中获取语义约束。
例如,RESTler根据 Swagger 规范中的返回类型学习消息依赖关系,Swagger 是一种描述 RESTful API 端点、方法、参数和返回类型的结构规范格式。
Pacheco 等人建议使用自然语言处理(NLP)技术从协议规范中提取内部状态机(FSM)。
随着大语言模型(LLM)技术的发展,许多研究开始采用 LLM 技术来自动学习和理解协议规范,如 mGPTFuzz、CHATAFL 和 LLMIF。这些方法的目的是在模糊过程中提供指导,特别是在推断当前协议状态和生成适当的测试消息方面。LLMs 的集成为提高协议模糊的效率和有效性提供了一条大有可为的途径,它可以利用 LLMs 复杂的语言理解能力来解释复杂的协议规范,并相应地指导测试策略。
- 为了将手动构建通信模型这一容易出错且耗费大量人力的过程自动化,一些研究成果自动从协议规范中获取语义约束。
4.1.2 Botom-Up Approaches
- 这些方法利用协议实现的可观测信息来重建通信模型。由于这些方法不依赖文本文档或规范,因此适用于私有协议。自上而下的方法在文档中对协议状态有明确的定义,而自下而上的方法则不同,它对状态的定义是特定目的的,在不同的用例、方法和实现中可能会有所不同。
例如,AFLNET 根据 被测程序响应的状态代码确定协议状态。
另一个例子是 StateAFL,它将长寿命内存的内存布局分组为不同的状态。 - 从学习源的角度来看,这些方法可分为两类,即基于流量分析的方法和基于程序分析的方法。
- Traffic-Analysis-Based Approaches:基于流量分析的方法主要是通过观测到的网络轨迹重建协议通信模型。这种方法易于操作,在无法跟踪程序执行(如无法获得包含目标程序的软件)的情况下也很有效。基于流量分析的通信模型构建方法分为主动和被动两个方法。
- Passive learning:主要依靠一组预先收集的 被测程序与其他实体的网络流量来推断通信模型。现有研究提出的学习算法可分为两类:基于统计的算法和基于神经网络的算法。对于前一类算法,Pulsar通过计算网络流量语料库中相邻消息的出现概率建立二阶马尔可夫模型,然后将该马尔可夫模型最小化为 DFA。收到消息后,Pulsar 会将其与推断出的 DFA 中的一个状态进行匹配,以选择一个有效的响应模板来构建新的测试用例。
对于后一类情况,Fan 等人和 SeqFuzzer使用 LSTM 学习有状态协议的语法和时间特征。具体来说,他们使用长短期记忆(LSTM)作为序列到序列(seq2seq)模型的编码器和解码器。Seq2seq 模型是一种编码器-解码器模型结构,可以处理不同长度的输入和输出序列。编码器 LSTM 模型通过捕获的网络流量学习协议特征,而解码器 LSTM 模型则用于生成模糊输入。
基于被动网络流量的状态机学习方法操作简单,运行速度快。但是,构建的状态机的质量取决于捕获流量的覆盖范围。在实践中,很难捕获全面的消息类型和序列,导致构建的通信模型缺少部分流量的状态或状态转换。 - Active learning:涉及在模糊过程中学习通信模型。该方法根据是否预先确定全局状态集进行分类。
第一类不预先确定全局状态集,即不预先确定状态机中可能状态的数量和性质。这种方法采用自动机主动学习算法来识别目标的状态机。学习算法基于用户定义的输入/输出字母以及字母与具体信息之间的映射器。这些算法从一个空的状态机开始,通过与目标协议实现交互,迭代地提出并重新定义模型,只有在没有发现所学状态机的反例时才停止。
这一类中的大多数研究都采用了 Angluin 的 ∗ 算法,根据协议规范确定输入字母,并使用消息模板将其转化为实际消息。
DYNPRE采用自适应消息重写技术,在与服务器交互时管理会话特定标识符。它利用字节级的突变和服务器反馈来推断信息的含义,并将其转化为实际信息。它利用字节级突变和服务器反馈来推断信息的含义和格式,识别不同的信息类型,并根据观察到的信息模式创建精确而简约的协议状态机。
第二类则通过基于规则的方法预先确定状态集,以规避自动学习算法的复杂性,并通过突变已知报文来学习状态之间的转换。
AFLNET使用响应信息状态代码来推断当前协议状态,通过改变真实信息序列来揭示转换。
Bleem 利用 Scapy 库解析消息,并通过保留枚举类型的所有字段将其抽象为各种消息类型。这一策略基于 Scapy 支持的 50 多个协议的经验观察,其中不同的枚举字段值通常代表不同的数据包或帧类型。然后,Bleem 利用这些抽象化的消息轨迹来构建用于模糊测试的指导图。
另一个例子是 Braktooth,它根据消息特征制定了八条将消息映射到状态的规则。它作为 PUT 和标准协议栈之间的代理,通过改变通信来探索更多的状态转换。
同样,Garbelini 等人建立了映射规则来识别状态,并利用捕获轨迹(即 pcap files)学习状态机。
- Passive learning:主要依靠一组预先收集的 被测程序与其他实体的网络流量来推断通信模型。现有研究提出的学习算法可分为两类:基于统计的算法和基于神经网络的算法。对于前一类算法,Pulsar通过计算网络流量语料库中相邻消息的出现概率建立二阶马尔可夫模型,然后将该马尔可夫模型最小化为 DFA。收到消息后,Pulsar 会将其与推断出的 DFA 中的一个状态进行匹配,以选择一个有效的响应模板来构建新的测试用例。
- Program-Analysis-Assisted Approaches
- 程序分析方法会额外使用内部执行信息来构建通信模型。内部执行信息包括静态和动态程序分析的结果,这不仅需要访问程序,还需要使用程序工具等分析框架。根据所使用的内部执行信息类型,现有工作可分为基于执行轨迹的方法和基于状态变量的方法。
- 基于执行轨迹的方法根据目标程序的执行轨迹识别不同的内部执行状态。
例如,ICS3Fuzzer通过动态检测目标监控软件来收集执行轨迹。通过比较执行轨迹的特性,ICS3Fuzzer 可以区分 PUT 是否处于不同的状态。 - 基于状态变量的方法通过跟踪输入处理过程中状态变量值的变化来检测协议状态转换。该方法基于简单的观察,即大多数协议实现都使用某些变量来存储当前状态。因此,它们将这些变量识别为状态变量,并使用它们的值来区分不同的状态。
例如,StateAFL通过识别内存快照中的长寿命数据结构来确定可能的状态变量。
STATEINSPECTOR通过定位堆内存中在每个消息序列执行过程中保持相同值的内存区域来识别状态变量。
SGFuzz通过正则表达式自动提取至少赋值一次的所有枚举类型变量来识别状态变量。这种方法背后的洞察力基于对大多数协议实现使用枚举类型状态变量的调查。STATELIFTER 将协议解析器中的循环视为状态机的核心。通过静态分析,它可以遍历代码中的循环结构,并将每个循环迭代可能执行的不同路径映射到不同的状态。循环迭代之间的依赖关系被视为状态机中的状态转换。
ParDif 使用静态符号分析从协议实现中提取有限状态机(FSM),方法是识别相关的消息解析约束并将其转换为有序的状态转换。
- 基于执行轨迹的方法根据目标程序的执行轨迹识别不同的内部执行状态。
- 程序分析方法会额外使用内部执行信息来构建通信模型。内部执行信息包括静态和动态程序分析的结果,这不仅需要访问程序,还需要使用程序工具等分析框架。根据所使用的内部执行信息类型,现有工作可分为基于执行轨迹的方法和基于状态变量的方法。
- 一些研究还利用程序分析辅助方法来构建协议实现的数据模型。
Polyglot利用动态二进制分析,通过密切监控程序如何处理网络数据来提取协议信息,从而揭示复杂的协议语义和结构,而无需依赖源代码。
最新研究成果 Netlifter利用静态分析直接从源代码中提取精确的协议规范,采用抽象格式图 (AFG) 捕捉复杂的数据结构关系和依赖关系,并将其可视化,准确度极高。
Spenny将动态分析与符号执行相结合,精确地逆向工程了工业控制系统协议。
4.2 Task Scheduling
- 根据处理状态相关复杂性所采用的方法,对调度阶段进行了明确的分类。这种分类主要分为两类:分层方法和整体方法。
- Hierarchical Approaches:分层方法将调度分为两个独立的阶段:
- (1)状态间调度:该阶段包括根据状态的优先级或相关性,使用状态调度算法选择要模糊的状态。
- (2)状态内调度:一旦选择了目标状态,就会应用一般调度算法来优化该状态内的模糊处理。通过分离这些阶段,分层方法可以对模糊过程进行更细致的控制。
例如,如果我们想在握手完成后测试协议,那么状态间调度阶段将首先优先处理该状态。然后,状态内调度阶段将使用传统调度方法(如种子调度、字节调度、突变策略调度)生成特定测试用例,并在握手后状态下执行。- 在这一范例中,调度过程使用的启发式方法主要分为三类:
- 稀有性优先:稀有性优先启发式将更多资源分配给很少使用的状态,假设这些状态蕴藏着更多未被发现的相邻状态或代码逻辑。
- 性能优先:性能优先启发式则优先考虑代码覆盖率或错误发现率较高的状态。
- 复杂性优先:优先考虑复杂性较高(即与更多基本模块相连)或较深(即离初始状态较远)的状态 。
- 例如,ICS3Fuzzer 倾向于选择更深的状态和那些使用更多基本模块的状态。
- 作为一种基于生成的模糊器,Pulsar 计算从当前状态可以到达的所有状态的权重,然后选择权重最大的状态进行下一步测试。具体来说,一个状态的权重是按一定次数的转换中所有可变项的总和来计算的。然而,由于所有这些状态选择算法都是在不同的平台和目标上分别实现和评估的,因此很难进行公平的比较和得出结论性的结论。
- Liu 等人评估了 AFLNet现有的三种状态选择算法,包括稀有性优先算法、随机选择状态的算法和顺序状态选择算法。他们发现,这些算法在代码覆盖率方面取得了非常相似的结果。他们将原因归结为 AFLNET 的粗粒度状态抽象和对状态生产率的估计不准确。因此,他们提出了 AFLNETLEGION 算法来解决这些问题,该算法基于蒙特卡罗树搜索算法的一个变体。
- 在这一范例中,调度过程使用的启发式方法主要分为三类:
- Monolithic approaches:采用单一、统一的调度阶段,将状态相关信息直接整合到调度算法中。这意味着调度器在决策过程中会考虑不同状态下种子的性能,而不是将状态转换和测试用例生成视为单独的步骤。
例如,SGFuzz根据行使时间将状态分为罕见状态和正常状态。在为种子分配能量时,它会计算每个种子行使的稀有状态比例,并在原始功率调度算法的基础上将该比例作为参数之一添加进去。类似地,SGFuzz 会为包含与预期协议行为相对应的状态转换的种子分配更多能量。这是因为 SGFuzz 预计这些有效的状态转换更容易突变为其他无效的状态转换,从而产生错误处理逻辑。
类似地,LTL-Fuzzer 也会对整个种子进行调度,在执行过程中优先考虑更接近目标代码位置的种子。
4.3 Testcase Construction
- 协议模糊中使用的构建策略可分为数据包级和序列级。
4.3.1 Packet-Level Construction Strategy
- 协议模糊器的数据包级构建策略基本上继承了一般模糊器的常用策略。例如,Peach Fuzzer中的 relation、fixup 和 transform 等元素通常用于描述长度、校验和及编码转换等协议项之间的关系。比特翻转和置零等一般突变方法也常用于生成数据包级测试用例。本段将更多地考虑利用协议特性来减少输入空间或提高错误触发效率的构建策略。
对于前一个目的(即减少输入空间),SPIDER利用了特定领域的洞察力,即大多数 Openlow 消息都会触发现有 SDN 控制器中影响状态计算和资源足迹的新系统事件。基于这种洞察力,SPIDER 可以直接生成事件序列,而不是生成 Openlow 消息,从而显著减少了输入空间。
L2Fuzz 将 L2CAP 数据包格式分为可变异的字段和保持不变的其他字段,以生成不太可能被拒绝的测试用例。
IPSpex结合网络跟踪和网络数据包构建的执行跟踪来提取 ICS 协议的信息字段语义。
针对后一种目的(即提高诱导错误的有效性)的策略主要是从实践中总结出来的启发式方法。例如,EmNetTest系统地生成了带有无效报文头或截断报文头的有效数据包。这一策略背后的洞察力来自对嵌入式网络协议栈(ENS)中 61 个已报告漏洞的全面研究。许多行业会议著作中也提到了类似的策略。
BadMesher采用了几种针对特定领域的策略,如将长度字段设置为余量值、随机删除某些字段等,以提高在 Wi-Fi 网状设备中触发漏洞的效率。
Yen等人发现,将ID ield变为不存在的ID、将端口号或长度ield变为边界值(如0xFF/0x00)以及将IP变为一些随机地址等策略,在模糊数据分发服务(DDS)协议时相当有效。
BrokenMesh在模糊蓝牙网格协议时也采用了一些策略,如改变数据包计数或长度字段。TaintBFuzz采用静态污点分析来识别 Zigbee 协议字段与 Zigbee 实现中用于路径决策的变量之间的联系,从而优先考虑预计会揭示更多代码路径的突变,并提高测试的易用性。
MPFuzz使用全局同步机制在不同模糊实例之间共享关键域信息,并根据这些域的语义特征执行有针对性的突变,从而更容易发现潜在漏洞。
4.3.2 Sequence-Level Construction Strategy
- 协议模糊器可能会采用一些序列级构造策略。这些策略会主动构建偏离常规协议状态机的消息序列,期望触发更多被测程序的非内存安全性错误。基于生成的模糊器和基于突变的模糊器在序列级构造中的操作方式不同。
- Generation-Based Fuzzers:这些模糊器利用既定的协议知识(如标准状态机和消息间的依赖关系)构建消息序列。著名的研究过在标准状态机的有效序列上添加或删除随机协议消息等策略,生成异常消息轨迹。
Sweyntooth、Greyhound和 Braktooth等项目根据状态机模型,仔细监控被测程序的状态转换,并在不正确的状态下有策略地注入有效数据包,以诱发异常。
Fiterau-Brostean 等人的最新研究提出了一种检测状态机漏洞的新方法,即输入能显示特定类型状态机漏洞的无限自动机目录以及被测程序的模型。然后,它可以对模型进行分析,并生成暴露错误的测试用例。 - Mutation-Based Fuzzers: 这些模糊器主要采用简单而有效的策略来改变种子的信息序列。这包括数据包分层、随机插入或删除等技术。
例如,AFLNET通过维护一个网络跟踪信息池来构建信息序列,这些信息可以集成到现有种子中或替代现有种子。AFLNET 还混合使用了字节级和序列级运算符,包括替换、插入、复制和删除报文,以构建报文序列。
DYFuzzing对种子进行了变异,并应用了Dolev-Yao(DY)攻击者策略。
Frankenstein对已知信息序列进行重组,以提高代码覆盖率。
He 等人针对 5G 非访问层(NAS)协议提出了一种独特的模糊器,可将数据包从捕获中提取到结构化的消息表中。然后,该模糊器针对协议信息中的关键字段类型应用不同的突变技术,显著提高了信息突变过程的智能性和精确性。例如,长度字段的突变结合了边界值和中间值,包括 0、最大值、最小值和随机中间值。
值得注意的是,基于突变的模糊器必须明智地管理消息序列中特定字段的相关性,如会话号、计数器或时间戳。不加区分地对这些字段进行突变,可能会导致输入无效,从而被提前拒绝。为了应对这一挑战,AFLNET修改了被测程序的代码,使用一个固定的会话编号 1,从而确保模糊处理的有效性。
- Generation-Based Fuzzers:这些模糊器利用既定的协议知识(如标准状态机和消息间的依赖关系)构建消息序列。著名的研究过在标准状态机的有效序列上添加或删除随机协议消息等策略,生成异常消息轨迹。
5 Executor
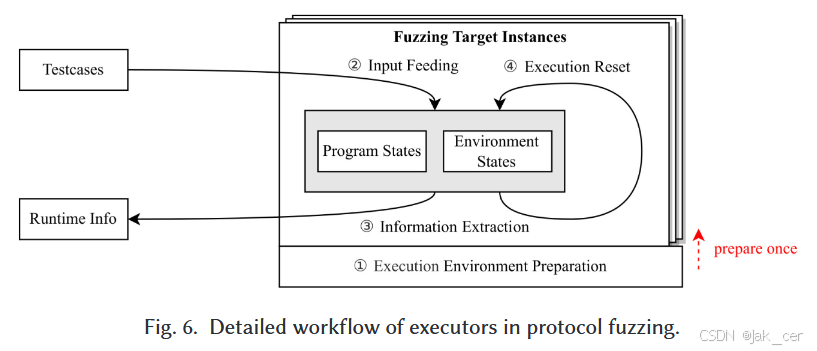
如图 6 所示,协议模糊中的执行器通常包括四个关键过程。首先,执行器需要为被测程序准备一个可执行的执行环境(①.执行环境准备),然后通过输入馈送机制向被测程序发送输入(②.输入馈送),在输入处理过程中提取运行时信息(③.信息提取),并在当前迭代执行完成后将执行状态和环境状态重置为特定状态(④.执行重置)。
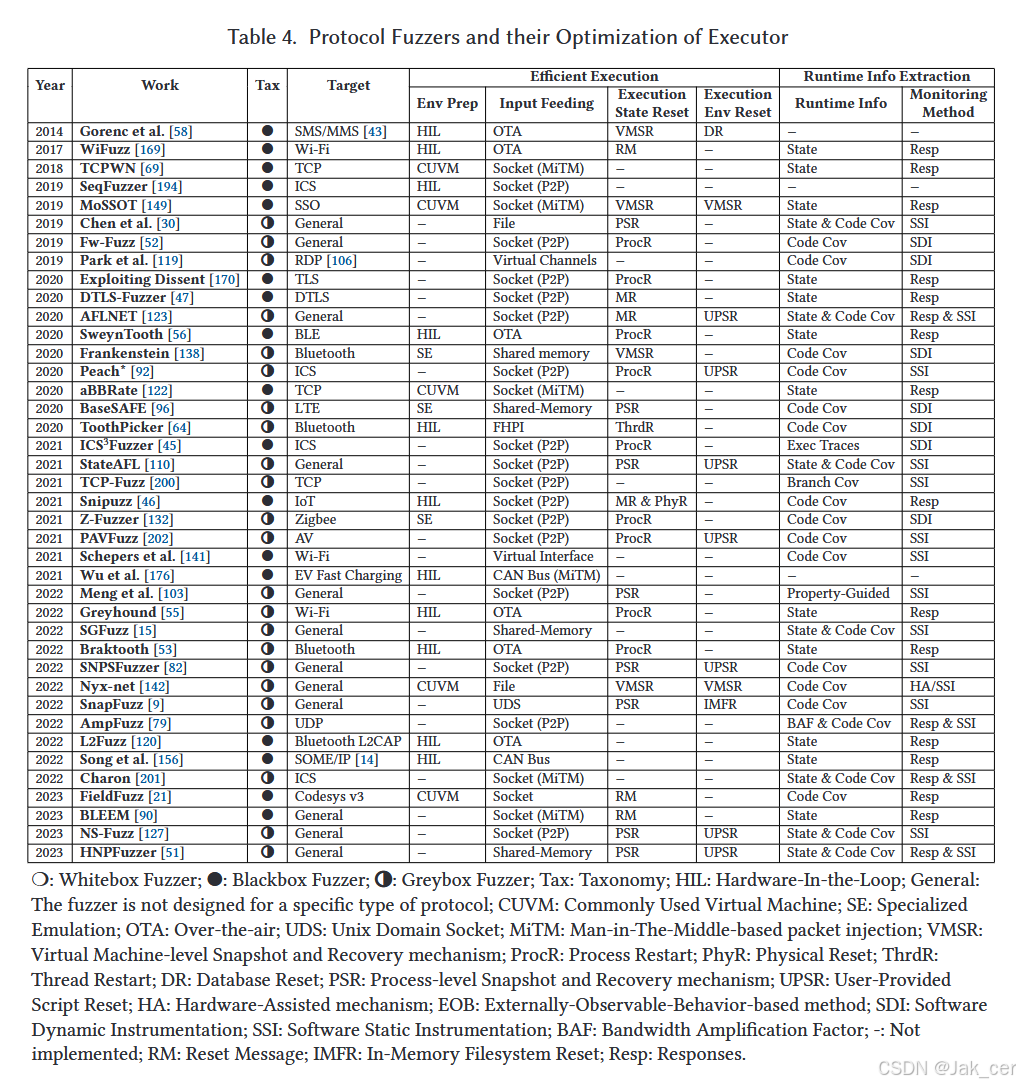
表在表 4 中,我们总结了现有协议模糊工作在有效执行(包括①、②、④)和运行时信息提取(③)方面的关键技术和改进。表中的研究是从论文集中选取的,因为它们与执行器直接相关。
5.1 Eficient Execution
- 在协议模糊测试中,提高模糊测试效率通常有两个方向:
1)建立可实现并行测试的执行环境,以提高可扩展性(图 6 中的①);
2)降低每次测试迭代的执行成本(图 6 中的②和④)。
5.1.1 Scalability Improvement.
- 可扩展模糊是指为并行模糊创建多个测试环境的能力。这在协议模糊测试中至关重要,因为许多模糊目标都与硬件密切相关。传统的并行测试方法是购买多台物理设备,这种方法既经济又不划算。在协议模糊测试中,由于许多模糊目标依赖于专门的执行环境,对这些目标的并行测试只能通过购买多个物理设备来进行,从而导致高昂的经济成本和浪费。
- 仿真是可扩展模糊测试的关键解决方案。它为被测程序提供了虚拟执行环境,减少了对专用硬件的依赖,便于创建大量并行测试实例。这种功能大大增强了可扩展性,允许在多个环境中进行广泛的模糊操作。一些协议模糊器利用现有的仿真解决方案来扩展模糊过程。
- 然而,在协议模糊测试中使用仿真技术有两个困难。首先是协议实现二进制文件的可用性,因为许多软件镜像并不公开。其次,与硬件的多样性相比,现有的仿真器只能支持其中的一小部分。这些困难导致大量工作仍在以硬件在环方式执行模糊测试。
- 一些研究根据不同设备的特点解决了这些问题、。对于第一个挑战,现有工作通过拦截空中下载(OTA)设备更新获取目标二进制文件,或使用供应商指定的命令或调试端口进行提取。例如,Frankenstein利用Patchram机制(一种可用于临时修补ROM断点的Broadcom厂商专用命令)获取物理蓝牙芯片的内存快照,并在未修改版本的QEMU中对其进行仿真。为应对第二个挑战,现有工作通常使用一种称为重托管(rehosting)的方法来部分模拟物理硬件的功能 。例如,BaseSafe[96]利用流行的 CPU 仿真器 Unicorn 引擎,有选择地重新托管了几个信令消息解析器函数。
5.1.2 Execution Cost Reduction.
- 提高模糊处理效率的另一个方向是优化每次迭代的中间执行步骤。下面,我们将介绍现有工作在这一方向上的进展,主要集中在两个子过程:输入反馈(图 6 中的②)和执行重置(图 6 中的④)。
- Input Feeding:输入馈送机制作为输入生成器与被测程序之间的管道,将测试用例传递给 被测程序进行解析和执行。根据模糊器和被测程序之间的通信所依赖的进程间通信(IPC)机制,现有方法大致可分为四类,即基于OTA的方法、基于套接字的方法、基于共享内存的方法和基于文件的方法。基于OTA和基于套接字的方法主要用于模糊器和 被测程序无法部署在同一物理设备上的情况。当被测程序和模糊器可以部署在同一设备上时,后两种方法可用于加快输入。
- OTA-Based Input Feeding:一般来说,基于OTA的输入反馈机制多用于模糊协议的实现,这些协议通常具有封闭性,并与硬件组件紧密集成,如 Wi-Fi 、蓝牙(包括传统蓝牙和 BLE)、LTE , Zigbee , 4G/5G和 SMS/MMS 等。在这种方法中,被测程序和模糊器需要部署在相邻的物理空间,并在特定频段上相互通信。因此,基于OTA的模糊器需要使用具有接收和发送功能的无线电频率收发器设备,如软件定义无线电(SDR),以处理宽调谐范围内的信号。基于OTA的模糊测试能够测试包括物理层在内的整个协议栈。不过,在上述方法中,基于OTA的方法速度最慢。因此,许多无线协议模糊器尝试使用其他输入馈送机制来获得更好的性能。
- Socket-based Input Feeding:在基于TCP/IP基础架构的协议实现中,大多使用基于套接字的输入馈送机制。在这些方法的常见情况下,模糊器和被测程序通过 IP 地址、套接字机制(包括 TCP 套接字和 UDP 套接字)相互通信。基于套接字的方法包括两种部署模式,一种是模糊器和被测程序之间的点对点(P2P)通信 。模糊器可以扮演客户端或服务器的角色,具体取决于被测程序的角色。另一种部署模式是 "中间人"(MiTM)模式,即模糊器充当通信双方之间的代理,对正常通信路径进行突变或注入。基于 MiTM 的输入反馈主要用于协议涉及某些上下文信息(校验和、数据包序列等)的情况,这些信息无法通过改变静态种子来保持有效。然而,这两种模式都需要应对两个挑战。
- 首先,套接字通信相当繁重,涉及大量上下文切换。现有研究通过避免使用这些昂贵的网络功能,提高了基于套接字的输入反馈机制的效率。
例如,SnapFuzz用 UNIX 域套接字取代了原来的互联网套接字,这是一种轻量级的 IPC 机制,没有 IP 套接字所具有的路由、校验和计算操作。 - 其次,模糊器很难确定被测程序是否已经处理完上一条信息,并准备好接收下一条信息。当目标尚未准备就绪时,被测程序可能会过早地拒绝接收信息,从而导致模糊器与其状态机不同步。
为了解决这个问题,Fiterau-Brostean 等人和 AFLNET设置了静态时间间隔,以等待被测程序初始化、处理请求和发送响应。不过,静态计时器的粒度太粗,可能会浪费大量时间等待超时,从而减慢模糊处理速度。
SnapFuzz和 AMPFuzz开发了一种粒度更小的方法来检查套接字的状态。具体来说,它们将对相关网络系统调用recv()、recvfrom()等函数的调用作为准备接收下一条信息的标志。他们通过二进制重写和编译时代码工具监控所有这些函数调用,然后通知模糊器发送下一迭代输入。
- 首先,套接字通信相当繁重,涉及大量上下文切换。现有研究通过避免使用这些昂贵的网络功能,提高了基于套接字的输入反馈机制的效率。
- File-Based Input Feeding:基于文件的输入反馈利用静态或动态插桩技术,以文件 操作取代繁重的网络操作,从而实现性能提升。
例如,Yurong 等人在无法获得被测程序源代码的情况下,使用预加载定制库将套接字通信转换为文件操作。
同样,Nyx-net向目标注入了一个库,以挂钩目标连接的网络功能,从而获得其相关的文件描述符,并将模糊输入注入到正确的位置。 - Share-Memory-Based Input Feeding:基于共享内存的输入反馈将模糊输入写入共享内存地址,并hook相关函数从共享内存读取测试用例。
例如,BaseSafe在目标进程的分叉副本中执行每个生成的测试用例,每次运行的输入都被复制到相应子进程的适当地址。
同样,Frankenstein创建了一个虚拟调制解调器,用于注入自定义数据包。模糊输入被写入 RAM 中的接收 buffer,RAM 通过直接内存访问 (DMA) 映射到硬件接收 bufer。
此外,HNPFuzzer还基于共享内存模拟网络功能,以减少模糊器和被测程序之间的信息传输时间消耗。 - Others:还有一些研究依靠专门的通信通道来提供模糊输入。
例如,为了模糊远程桌面协议(RDP)的客户端,Park 等人利用 RDP 中用于传输数据的抽象层--虚拟通道,主动将模糊输入从服务器发送到客户端。
Song 等人使用媒体转换器在汽车以太网和标准千兆以太网之间转换数据,并对电子控制单元(ECU)的 SOME/IP 协议栈(ECU 之间的控制通信协议)进行模糊处理。
- Execution Reset:
- 每次迭代执行后,都有必要将被测程序重置到指定状态,然后等待下一次迭代模糊。这是因为每个测试用例都可能影响被测程序的内部执行状态(如全局变量)或执行环境(如文件系统、数据库)。在不重置的情况下执行,会使被测程序的行为更加非确定,从而增加重现错误的难度。
例如,在模糊 FTP 服务器时,测试用例可能会导致在共享文件夹下创建一个文件。如果共享文件夹没有重置,那么如果接下来的测试用例试图创建同名的文件,FTP 服务器就会报错,这意味着相同的测试用例会导致不同的被测程序行为。 - 根据对现有工作执行重置方法的分析,该过程主要涉及三个关键子阶段,分别是:1.重置时间选择;2.执行状态重置;3.执行环境重置。
首先,在重置时间选择阶段,执行者会评估当前迭代是否已经结束。这一判断先于任何重置执行的操作。一旦确认当前执行周期已完成,流程将继续进行执行状态重置和执行环境重置,分别重置被测程序和相关外部执行环境的运行时状态。下面我们将分别总结这三个关键阶段的现有工作进展。- 1、Reset Strategy Selection:重置策略主要用于确定执行重置的适当时间或执行点,这对模糊测试的性能有重大影响。过早重置可能会导致目标在执行某些可能存在漏洞的任务时终止,而过晚重置可能会影响测试的效率。
一种常见的方法是在重置执行前设定一个固定的时间间隔。例如,AFLNET允许用户手动设置重启被测程序前的时间延迟。不过,这种方法的粒度相对较粗,很难确定合适的时间间隔。
为了精确控制重置执行的时间,一些研究利用程序分析来确定表示迭代执行结束的位置,并在这些代码位置终止目标程序。例如,AMPFuzz会执行静态分析,并在不包含消息发送 API 的代码分支中注入终止调用。
此外,为了提高性能,有些研究选择在每次模糊迭代后不执行执行重置。例如,Charon利用程序状态推断模块来推断被测程序完成处理数据包的时间点,从而检测特定输入的覆盖范围,避免重复重启被测程序以收集反馈。同样,SGFuzz 也不会在每次迭代中重新启动被测程序。相反,它会进行后分析,以确定输入与目标程序行为之间的关系。具体来说,它收集被测程序已执行的所有输入,并将输入列表最小化为可触发错误的最小信息序列。 - 2、Execution State Reset:执行状态复位负责将正在运行的被测程序进程的上下文复位到指定状态,包括寄存器和内存中的数据等。现有的执行状态复位机制可分为三类,即基于消息的复位、进程重启和快照与恢复。
- Message-based reset:通过发送特定类型的消息,迫使被测程序终止正在进行的会话,并恢复到初始状态。
例如,在对 Wi-Fi 接入点(AP)进行模糊测试时,WiFuzz 会使用去验证消息重置其状态。基于消息的重置很容易使用,但它只支持有限的协议集,因为并非每个协议都设计有重置消息。此外,虽然它能重置被测程序的显式协议状态,却不能重置测试目标的隐式状态,如全局变量和已分配但未用重置消息释放的内存。 - Kill the target process and restart:这对模糊测试来说是一个相对繁重的操作,因为程序的重启涉及多个昂贵的预处理步骤,如将程序加载到内存、动态链接等,导致效率低下。
- Snapshot & recovery mechanism:这种方法是在被测程序特定的运行时状态检查点,然后在每次模糊迭代后将其重置回该检查点。这种方法有效地绕过了重复执行资源密集型初始化操作的过程,从而提高了模糊测试的效率。协议模糊尤其能从快照技术中获得巨大收益。协议主要是有状态的,这意味着输入通常由多个前缀信息组成,在引入伪造信息之前,这些信息会引导被测程序进入指定状态。测试用例共享相同的前缀信息序列是很常见的,尤其是当特定状态需要反复探索时。在协议模糊处理过程中采用快照技术可以消除与解析这些共享数据包序列相关的冗余执行,从而显著提高模糊处理效率。目前协议模糊研究中使用的快照方法可大致分为两类:进程级快照和虚拟机级快照。
- Process-Level snapshot mechanisms:这些方法依赖操作系统提供的系统调用功能来实现其功能。一般来说,根据所使用的 API,现有方法可分为两类:基于 fork 和基于 ptrace。
基于fork的快照机制广泛应用于几种著名的通用模糊器,包括 AFL。具体来说,AFL 在被测程序二进制文件中插入一段 fork 服务器代码,在 main() 函数之前执行。根据 AFL 模糊器发出的信号,fork-server 通过fork()函数生成一个子进程,这个子进程继续执行main()函数。由于 fork 服务器已经加载了各种资源,因此每个子进程只需执行主函数的代码,从而绕过了代价高昂的预处理步骤,提高了效率。
许多协议模糊器都采用了这种机制进行状态重置。此外,一些研究还扩展了 AFL 中原有的 fork-server 机制,允许在不同代码点进行有条件的多重初始化,使模糊器能够方便地在协议的不同状态之间切换,从而提高模糊过程的效率[9, 30]。
基于ptrace的快照机制(如 CRIU 和 DMTCP)利用调试 API ptrace()收集所有进程上下文信息,并将其保存为图像文件。在还原过程中,这些快照机制读取转储的映像文件,并使用fork()或clone()等系统调用重新创建进程。基于 fork 的快照需要在执行前预先确定快照条件(即 fork 服务器调用的位置),而基于 ptrace 的快照则不同,它可以在运行时的任何状态进行检查点。 - Virtual-Machine-Level snapshot mechanisms:利用虚拟机管理程序的功能,在特定时间点捕捉整个虚拟机的快照,通常通过超级调用来实现 。调用超级调用时,在虚拟机中运行的程序会退出虚拟机上下文,并将控制权转移到管理程序。虽然基于管理程序的方法对用户友好,不需要任何工具,但由于其粒度较大,因此效率较低,而且更耗费空间。
为了提高在协议模糊测试中使用虚拟机级快照的实用性,Nyx-net采用了一种增量快照方法,以减少创建和删除快照的相关开销。具体来说,Nyx-net 在原始状态下建立一个根快照,每次执行迭代都从这个根快照开始。在随后的模糊迭代中,Nyx-net 会在执行输入信息后根据根快照生成增量快照。因此,Nyx-net 在共享相同前缀信息序列的测试用例中性能大增。
- Process-Level snapshot mechanisms:这些方法依赖操作系统提供的系统调用功能来实现其功能。一般来说,根据所使用的 API,现有方法可分为两类:基于 fork 和基于 ptrace。
- Message-based reset:通过发送特定类型的消息,迫使被测程序终止正在进行的会话,并恢复到初始状态。
- 3、Execution Environmnet Reset:执行环境的重置主要涉及重置可能受到被测程序的系统或数据库影响。许多模糊器都要求用户提供一个清理脚本来还原所有更改,这就需要大量的手动操作来分析被测程序对外部环境的潜在影响。
为解决这一问题,Snapfuzz利用定制的内存快照系统,在模糊迭代完成后自动丢弃修改。此外,还有基于管理程序的快照机制。此外,基于管理程序的快照机制(表 4 列 7 中的 VMSR)可以捕获整个虚拟机的状态,同时重置执行状态和环境。
- 1、Reset Strategy Selection:重置策略主要用于确定执行重置的适当时间或执行点,这对模糊测试的性能有重大影响。过早重置可能会导致目标在执行某些可能存在漏洞的任务时终止,而过晚重置可能会影响测试的效率。
- 每次迭代执行后,都有必要将被测程序重置到指定状态,然后等待下一次迭代模糊。这是因为每个测试用例都可能影响被测程序的内部执行状态(如全局变量)或执行环境(如文件系统、数据库)。在不重置的情况下执行,会使被测程序的行为更加非确定,从而增加重现错误的难度。
- Input Feeding:输入馈送机制作为输入生成器与被测程序之间的管道,将测试用例传递给 被测程序进行解析和执行。根据模糊器和被测程序之间的通信所依赖的进程间通信(IPC)机制,现有方法大致可分为四类,即基于OTA的方法、基于套接字的方法、基于共享内存的方法和基于文件的方法。基于OTA和基于套接字的方法主要用于模糊器和 被测程序无法部署在同一物理设备上的情况。当被测程序和模糊器可以部署在同一设备上时,后两种方法可用于加快输入。
5.2 Runtime Information Extraction
- 现有研究中使用的运行时信息提取方法按其通用性可分为三类。
- Hardware-Assisted methods:利用某些专用硬件设备固有的独特功能来收集运行时信息。
Nyx-net就是这种方法的一个典型例子,它采用了英特尔处理器跟踪(Intel PT)技术。该功能是某些高端英特尔 CPU 独有的功能,可详细记录软件执行方面的信息,如控制低路径,从而全面收集深度覆盖信息。 - Software-Based method:利用软件执行环境(如编译器、操作系统、虚拟机管理程序等)的能力来获取运行时信息。插桩是实现运行时信息提取最常用的方法,它在程序的特定代码点插入信息收集函数调用。程序插桩可以是静态的,也可以是动态的。前者发生在 被测程序运行之前,可以在编译时执行或直接重写二进制。后者在被测程序运行时进行,利用 DynamoRIO或 Frida等工具在特定代码点注入hook函数,收集运行时信息。
- Externally-Observable-Behavior-Based methods:是最通用的一类方法,因为它不依赖于执行环境的任何支持,可以黑盒方式使用。有多种外部可观测行为,如程序输出以及功耗和响应时间等侧信道信息。这些基于可观察行为的方法背后的启发式原理是,这些行为的差异可以代表被测程序处于不同的状态或经历了不同的执行路径。
具体来说,AFLNET 和 Fieldfuzz可根据响应信息中的状态代码识别不同的协议状态。Snipuzz 和 FUME 采用的启发式方法是,不同的响应信息意味着不同的执行路径。因此,它们将可能导致不同响应的输入作为种子,用于随后的突变测试,以期望提高覆盖率。
Aafer 等人和 Logos 使用执行日志作为反馈来调整输入生成语法,因为开发人员通常会添加日志语句来说明输入验证的详细信息。
Flowfuzz通过观察系统状态、功耗和响应时间等侧信道信息,确定硬件开关是否经过了不同的执行路径。
- Hardware-Assisted methods:利用某些专用硬件设备固有的独特功能来收集运行时信息。
6 Bug Collector
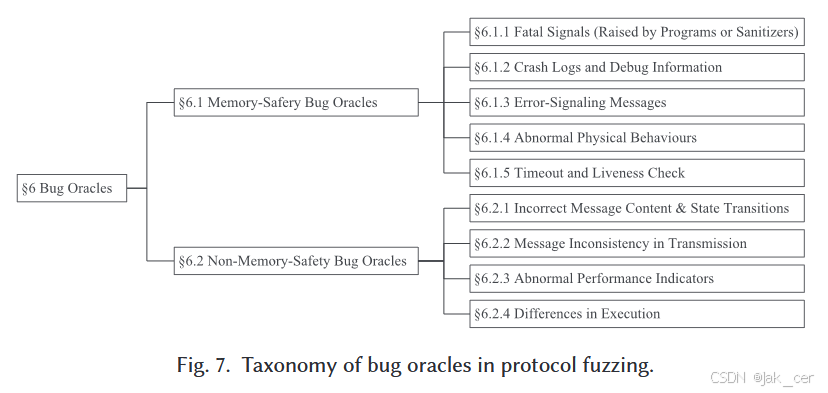
为应对协议模糊的挑战,现有工作根据不同的信息源设计了内存安全漏洞陷阱和非内存安全漏洞陷阱,如图 7 所示。
6.1 Memory-Safety Bug Oracles
6.1.1 Fatal Signals (Raised by Programs or Sanitizers).
- 在大量当代研究中,内存安全漏洞已被广泛用作漏洞检测的关键机制。内存安全漏洞主要表现为以无效值覆盖数据或代码指针,导致关键进程中断,如分段故障或进程终止,从而产生 SIGSEGV、SIGABRT 等致命信号。模糊器可以通过检查被测程序进程是否因这些信号而死亡来检测故障。针对不会立即导致程序崩溃的内存安全漏洞子集,Fuzzers 使用了sanitizers。sanitizers 是一种错误检测工具,专门用于识别和突出不安全或不理想的内存访问模式。一旦识别到此类异常, sanitizers 就会终止被测程序,从而提示潜在错误的存在。sanitizers 可在编译时启用,也可在运行时动态启用。
6.1.2 Crash Logs and Debug Information.
- 一些研究通过分析系统日志或调试信息来确定被测程序是否崩溃。这些系统日志和调试信息可以通过各种渠道获取。具体来说,ICS3 Fuzzer 使用 Windows 事件日志服务来检测 Windows 系统上的崩溃事件 。Swentooth和 Braktooth建议使用各自蓝牙开发板暴露的调试端口收集系统日志中的启动信息或崩溃信息。启动信息是程序崩溃的一个指标,因为蓝牙设备有一个看门狗程序,当发现蓝牙 SoC 无响应时会重置它。Wang 等人利用 NLP 技术处理日志,检测 被测程序的意外行为。与其他来源不同,L2Fuzz 和 FieldFuzz通过检查是否生成了崩溃转储来识别崩溃。
6.1.3 Error-Signaling Messages.
- 许多协议使用特殊响应或状态代码来指示内部错误,因此可用于漏洞检测。例如,L2Fuzz 通过检查接收到的数据包是否包含错误信号信息(如连接失败、连接中止、连接重置和连接拒绝)来检测蓝牙 L2CAP 漏洞。这些错误信息表明被测程序可能会崩溃。在对 Wi-Fi 协议栈进行模糊测试时,OWFuzz 使用 Deauth / Disassoc 帧(Wi-Fi 协议终止通信的管理帧)作为异常指标。
6.1.4 Abnormal Physical Behaviors .
- 目标设备的异常物理行为(如启动声音)也可用作错误预兆。例如,在对蓝牙声音设备进行模糊测试时,Braktooth 将重复的启动声音事件用作错误先验。这是因为蓝牙设备在发生错误时会被看门狗程序重启,而启动过程中会播放启动声音。不同的是,PCFuzzer利用示波器收集输出模块的物理信号来监控目标的状态。
6.1.5 Timeout and Liveness Checks.
- 超时和有效性检查通过检查目标的无响应性来识别崩溃或无限循环。检查目标进程无响应的常用方法是为响应设置静态超时。如果超时后仍未收到目标进程的响应信息,则判定目标进程已死亡或进入无限循环。这种方法适用于调试技术有限的环境,例如无法获取进程信号或调试日志。不过,设置一个固定超时时间是一种相对粗粒度的方法,可能会因网络波动或目标进程负载过大而产生误报。一些研究提出了几种主动有效性检查方法,以缓解误报问题。例如,Snipuzz会多次重新发送输入序列,以减少误报。IoTFuzzer、OWFuzz 和 BadMesher使用心跳消息(如 ICMP 消息)来推断被测程序的状态。
6.2 Non-Memory-Safety Bug Oracles
非内存安全错误是由非内存访问原因引起的错误,它们违反了某些预期属性,如逻辑错误、违反 RFC 或影响性能的错误。由于非内存安全漏洞没有统一的可观察行为,因此很难识别。检测非内存安全漏洞通常需要用户根据目标破坏的属性来定义神谕。根据检查的属性,这些缺陷可大致分为四类,即信息内容和状态转换不正确、传输不一致、性能指标异常和执行差异。我们将在下面的小节中详细介绍这些技术。值得注意的是,虽然有多种方法可以识别可能的非内存安全漏洞,但这些方法大多只能报告被测程序的可疑行为,仍需要专家手动验证以确定其影响和可利用性。
6.2.1 Incorrect Message Content & State Transitions.
- 信息内容不正确会检查响应内容是否违反某些语义限制。不正确的状态转换会检验状态转换是否有效或允许。在大多数情况下,这些规则是从协议规范中提取的,或者是利用专家知识设计的。这些规则可以是不同的形式,如典型状态机 、线性-时间属性、响应信息约束等。例如,Beurdouche 等人根据规范手动构建了一个标准状态机,然后使用该状态机作为基本事实来识别被测程序的异常行为。利用这种方法,在 TLS 实现 JSSE中发现了一个逻辑错误。该漏洞允许攻击者绕过所有与密钥交换和身份验证相关的信息,从而启动未加密通信。
- 给定协议实现需要满足的线性时间时间逻辑属性,LTL-Fuzzer利用定向灰盒模糊,将模糊导向可能影响该属性的特定位置,并在每次执行迭代中检查该属性是否成立。此外,Sweyntooth 和 Greyhound检查收到的响应数据包是否符合当前协议状态的预期类型集。任何不匹配的信息类型都会被标记为异常。Loki 从 PBFT 共识协议论文[25]中提取规则,用作检测区块链实现中的非内存安全漏洞的谕令。例如,Loki 发现了 Hyperledger Fabric中的一个漏洞,该漏洞可用于确认非法交易。
6.2.2 Message Inconsistency in Transmission.
- 有些工作会检查是否存在会导致协议完整性破坏的非内存安全漏洞。具体来说,由于正确的数据传输是 TCP 协议的基本属性之一,TCP-Fuzz在发送方和接收方都设计了一个数据检查器来检查是否违反了这一属性。每当发送或接收一条信息时,数据检查器都会检查发送的信息和接收的信息是否相同。
6.2.3 Abnormal Performance Indicators.
- 一些研究旨在找出能够影响 被测程序性能的网络攻击策略,这些研究通过监测被测程序的某些性能指标是否超出正常范围来判断攻击策略的有效性。例如,AMPFuzz使用每对请求和响应的带宽放大系数(BAF)(即所有响应报文长度之和与攻击请求长度之比)作为指标,来确定能够最大限度消耗吞吐量的报文,从而确定 UDP 服务中的放大 DDoS 攻击策略。TCPWN和ABBrate的目标是针对TCP拥塞控制的实现提出攻击策略,这些策略可以在模型指导下增加或减少拥塞窗口。为了检测输入是否确实影响了拥塞控制机制,TCPWN 从系统日志中获取窗口大小,并将其与预期基线进行比较。
6.2.4 Differences in Execution.
- 差异测试包括比较同一协议的不同实现的执行行为,以调查潜在的安全影响。由于这种方法独立于代码工具,因此具有可扩展性。例如,TCP-Fuzz比较了多个 TCP 实现的输出,以识别差异。Yang等人利用差异测试发现了以太坊中可能导致分叉攻击的共识漏洞。他们生成一系列交易作为输入,并观察两个以太坊客户端的响应,这两个客户端分别用 Golang 和 Rust 具体实现。同样,IcyChecker通过生成突变的 DApp 交易序列并验证最终状态的一致性来识别区块链状态不一致漏洞。ParDif 利用 bisimulation 算法比较不同协议实现的 FSM,并通过分析状态转换条件的差异来识别差异。然而,该领域的一个重大挑战是确定哪种实现偏离了协议的预期行为,以及确定观察到的行为差异是否源于协议 RFC 中的错误或规范不足。因此,大多数采用差异测试的工作都整合了后续的人工检查阶段
- 为了提高发现错误的效率,一些研究将被测程序与已经过良好测试或正式验证的实现(称为 "参考堆栈")进行比较。例如,TCP-Fuzz采用经典的、经过广泛测试的内核级 TCP 栈(如 Linux TCP 或 FreeBSD TCP)作为测试较新 TCP 栈的参考。在这种情况下,如果报告出现不一致,则强烈暗示较新的协议实现中存在漏洞。这种方法不仅可以识别差异,还提供了一个评估各种协议实现正确性的框架。
7 Directions of Future Research
到目前为止,我们已经讨论了最先进的协议模糊器。在本节中,我们将根据调查内容讨论模糊技术的研究趋势和当前挑战。
7.1 Towards Perfect Communication Model Construction
- 目前构建通信模型的方法远非完美,往往导致知识获取不完整或不准确,或需要大量人工操作。具体来说,如第 4 节所述,现有的通信模型构建方法可大致分为自上而下和自下而上两种方法。自下而上的方法是为了学习特定协议实现的通信模型,而不是协议本身的典型通信模型。然而,对于自上而下的方法,大多数现有研究仍严重依赖人工根据协议规范构建状态机。这种人工构建不仅耗费大量人力,而且容易出错。
- 现有研究已开始探索使用 NLP 技术从协议规范中自动提取部分 FSM。这一探索初步验证了自动提取协议通信模型的可行性。然而,由于规范中的歧义和未指明的行为,这种方法目前还无法从协议规范中提取典型的通信模型,因此无法在文本和通信模型之间实现完全的一对一转换。
- 为了解决这个问题,可以探索基于机器学习模型的方法来更好地构建模型。考虑到 LLM(大型语言模型)最近取得的显著进展,一个有前途的方向是开发基于 LLM 的解决方案,以更精确地构建模型。另一个可能的方向是结合其他信息源(如协议实现的代码、开发过程中的代码提交或注释信息、程序分析结果等)来帮助更好地理解规范的内容。
7.2 Towards Multi-Dimension Testing Perspectives
- 现有研究更多地侧重于改变数据包的内容或数据包序列的顺序。这种方法虽然在一定程度上是有效的,但却忽视了协议具有多维测试视角的事实,例如第 3.1 节中强调的消息延迟、缓存状态、配置和并发水平等变量。这些属性对决定目标系统的行为起着至关重要的作用。为了在协议实现中有效地测试这些属性,有必要创建能准确表示每个属性的详细模型,包括消息延迟、缓存状态、配置参数和并发水平。此外,还可以设计特定的通告和突变器,以评估协议行为在包含这些多维方面的各种情况下的正确性。这个方向非常有趣,有助于对协议的弹性和鲁棒性进行更全面的评估。
7.3 Fuzzing Characterized Protocol Targets
未来一个重要且未充分探索的研究方向是对特征协议目标进行模糊处理。目前的研究还没有完全覆盖各种协议,特别是那些具有明显特征和重要性的协议。以下三个领域尤其值得注意:
- 1. Domain-Speciic Protocols.专有领域协议,如卫星通信、无人驾驶飞行器 (UAV) 通信和机器人操作系统 (ROS)中使用的协议,通常具有较高的知识门槛和相对封闭的性质。这些协议在许多基础设施中发挥着重要作用,因此其安全性研究至关重要。目前,针对这些协议的模糊研究相对较少,这为学术界提供了通过开发新的模糊技术和工具来提高测试效率和安全性的机会。
- 2. Hardware-Implemented Protocols.另一个方向是设计模糊器,用于测试在 FPGA 等硬件上实现的协议。与软件层面的错误特征相比,这些硬件实现往往表现出不同的错误特征,因此有必要开发新的方法,以便更有效地识别和利用潜在漏洞。
- 3. Multi-Party Protocols.协议模糊的另一个可能方向是支持多方协议。一般来说,协议有多种通信模式,如点对点模式、服务器-客户端(主从)模式和多方模式。现有的协议模糊器更侧重于前两种模式,即作为客户端/服务器测试另一种模式,或作为对等节点测试被测程序。多方协议尚未研究。例如,在区块链网络中,节点可以扮演计算节点、共识节点或管理节点的角色,每个节点负责不同的任务。智能合约协议的正确执行需要这些角色的合作。如何有效地测试这些多方协议是一个有趣但具有挑战性的问题。
7.4 Combining with Other Vulnerability-Finding Techniques
- 除模糊技术外,还有多种漏洞挖掘技术,如符号执行和模型检查。虽然这些技术与模糊技术的结合已在一般情况下进行了探索,但它们在协议模糊中的应用仍相对欠缺。这为未来的研究指明了方向,特别是考虑到对于协议中定义的复杂通信,组合方法仍然面临着独特的测试挑战。直观地说,未来的研究可以改进现有的漏洞挖掘技术,以更好地解决协议特有的挑战。此外,许多协议都附有高质量的学习资源,如详细的说明书。未来的研究可以探索有效利用这些宝贵资源的方法,为综合方法提供信息并加以改进。
7.5 Shit-Let Protocol Fuzzing
- 尽管有一些研究致力于将通用模糊技术整合到开发周期中,例如libFuzzer、OSS-Fuzz等工具,以及CI/CD集成测试中的模糊研究,但很少有研究专门致力于缩小协议模糊与开发流程之间的差距。协议模糊测试有别于一般的软件模糊测试;它涉及对允许不同软件系统和组件之间进行通信和数据交换的各种协议进行严格测试。与一般软件相比,协议目标的开发工作流程通常更为复杂。这种复杂性源于它们需要精确地遵循既定的标准和规范,以确保不同系统之间的互操作性,从而给集成和测试带来独特的挑战。要应对这些挑战,就必须采用量身定制的模糊测试方法,以了解和适应协议开发的复杂性。因此,需要一种左移式的协议模糊测试方法,在软件开发生命周期的早期阶段就集成协议专用模糊测试技术。这可能涉及从开发人员的角度探索设计技术,必要时还可以考虑 HCI(人机交互)技术。这样做可以在更早的阶段发现漏洞和问题,从而更容易、更经济地解决这些问题,确保为协议实施提供更稳健、更安全的软件生态系统。

















 1364
1364

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









