







 本文详细介绍了决策树的三种构建算法:ID3、C4.5和CART,包括各自的分裂依据、处理连续数据的方式以及剪枝策略。接着,文章深入探讨了随机森林的概念、训练过程、预测过程及其特点,阐述了随机森林与GBDT、xgboost的区别。
本文详细介绍了决策树的三种构建算法:ID3、C4.5和CART,包括各自的分裂依据、处理连续数据的方式以及剪枝策略。接着,文章深入探讨了随机森林的概念、训练过程、预测过程及其特点,阐述了随机森林与GBDT、xgboost的区别。
1.决策树
决策树:从根节点开始一步步走到叶子节点(决策),所有的数据最终都会落在叶子节点,既可以做分类也可以做回归。根据决策树的输出结果,决策树可以分为分类树和回归树,分类树输出的结果为离散值(具体的类别),而回归树输出的结果为连续值(一个确定的数值)。决策树的构建算法主要有三种ID3,C4.5,CART三种,其中ID3和C4.5是分类树,CART是分类回归树,ID3是决策树最基本的构建算法,而C4.5和CART是在ID3的基础上进行优化的算法。下面介绍常见的三种决策树算法。
1.1 ID3
(1)熵 熵是表示随机变量不确定性的度量,直观理解是物体内部的混乱程度。公式如下:
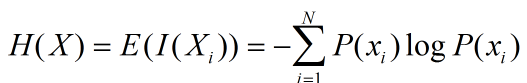
其实就是随机变量的自信息量I(x)的数学期望。
(2)信息增益
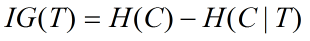
其中C为类别,这个变量可能的取值为C1,C2... Cn, T为特征。信息增益可以理解为先验熵(系统原本的熵)与固定特征T之后的条件熵之差。
(3)决策树的构建
数据分割。对于离散型数据,直接按照离散数据的取值进行分裂,每一个取值对应一个子节点。对于连续型数据,ID3原本是没有能力处理的,只有通过离散化将连续性数据转化为离散型数据再进行处理。
选择最优分裂属性。ID3采用信息增益作为选择最优的分裂属性的方法,选择熵作为衡量节点纯度的标准,信息增益的公式如上,分别计算每一个属性的信息增益,选择信息增益最大的属性进行分裂。
停止分裂的条件。①最小节点数,当节点的数据量小于一个指定的数量时,不继续分裂。为了防止噪声的影响和降低复杂度,有利于降低过拟合的影响。②熵或者基尼值小于阀值。熵和基尼值的大小表示数据的复杂程度,当熵或者基尼值过小时,表示数据的纯度比较大,如果熵或者基尼值小于一定程度时,节点停止分裂。③决策树的深度达到指定的条件。④所有特征已经使用完毕,不能继续进行分裂。
(4)总结
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 598
598

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









