







 本文基于《大数据与机器学习经典案例》探讨Ames房价预测,通过数据读取、变量分析、相关矩阵、缺失值处理、离群值删除等步骤,揭示GrLivArea、TotalBsmtSF、OverallQual、YearBuilt等变量与SalePrice的关系,为后续回归模型建立奠定基础。
本文基于《大数据与机器学习经典案例》探讨Ames房价预测,通过数据读取、变量分析、相关矩阵、缺失值处理、离群值删除等步骤,揭示GrLivArea、TotalBsmtSF、OverallQual、YearBuilt等变量与SalePrice的关系,为后续回归模型建立奠定基础。
2021.9.17 自学机器学习的日子,在图书馆摸了本《大数据与机器学习经典案例》 ,
第一章,讲讲房价预测和回归问题。
本文用到的是爱荷华州艾姆斯市房价数据集,由杜鲁门州立大学统计学教授DeCock整理,可移步公众号 当代巴别塔 回复【房价数据集】获取。
1. 导入库
首先,我们将数据集保存于chapter1\dataset中。启动Jupyter Notebook,在chapter1目录下新建一个.ipy程序。
导入库:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from scipy import stats
from scipy.stats import norm
%matplotlib inline
2. 读取数据集
现在我们读入训练集,并显示列变量名称。
df_train=pd.read_csv('./dataset/train.csv')
df_train.columns
这其中,列变量SalePrice代表房价,我们执行以下程序段并观察SalePrice的统计特征。
运行代码如下:
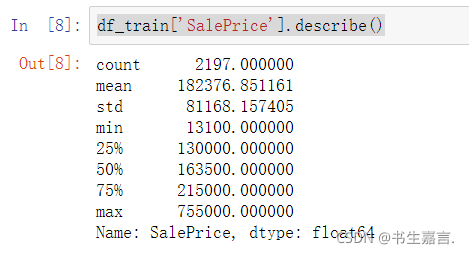
可以看到,50%房屋价格集中于16万美元左右,均价为18万美元,房价最小值大于0,标准差在可接受范围内,意味着SalePrice数据可用。
执行以下程序段,绘制SalePrice直方图,观察到SalePrice呈右偏正态分布,如图。
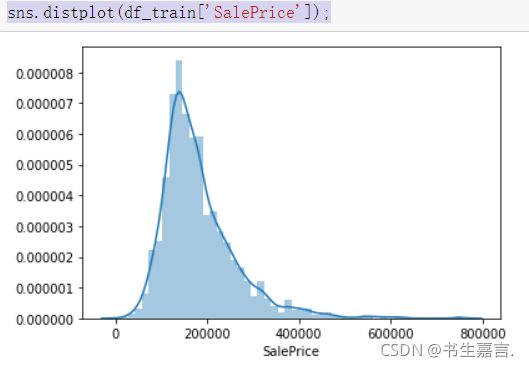
接下来计算一下峰度和偏度。

偏度值1.78进一步印证了SalePrice的右偏分布特征,峰度值5.50则显示SalePrice存在陡峭尖峰。
3. 分析变量与SalePrice间的关系(四个例子)
列变量GrLivArea表示居住面积,执行下列程序段,GrLivArea与SalePrice的关系如图所示。
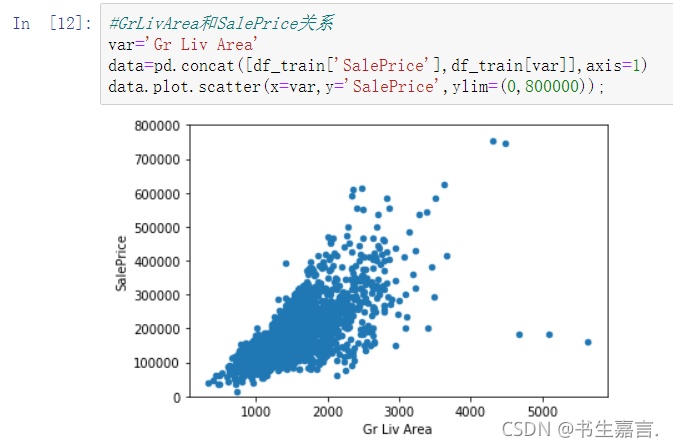
可见,列变量GrLivArea与SalePrice密切相关,呈现近似线性关系。
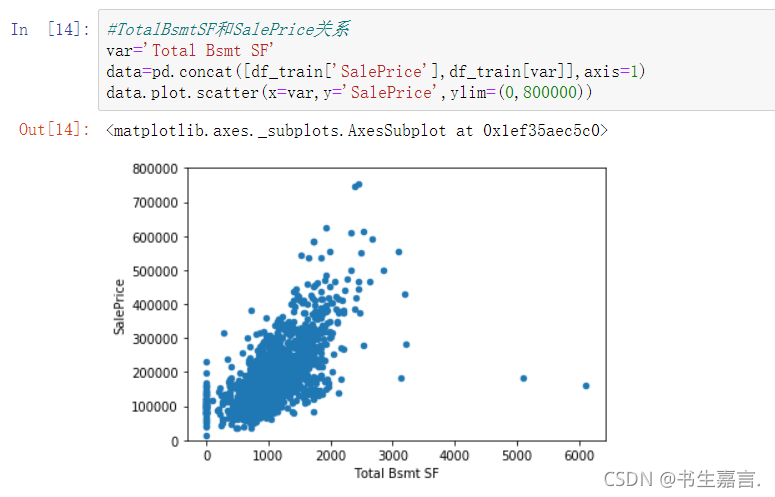
列变量TotalBsmtSF表示地下室面积,执行下列程序段,得出TotalBsmtSF与SalePrice关系
列变量OverallQual 表示房屋装修质量,分为10个级别,用1~10表示,含义是:10表示特别好,9示非常好,8表示很好,7表示好,6表示高于平均水平,5表示平均水平4表示低于平均水平,3表示合格水平,2表示一般差,1表示非常差。执行程序段, 列变量OrvrllQual与SalePrice 的关系如图。
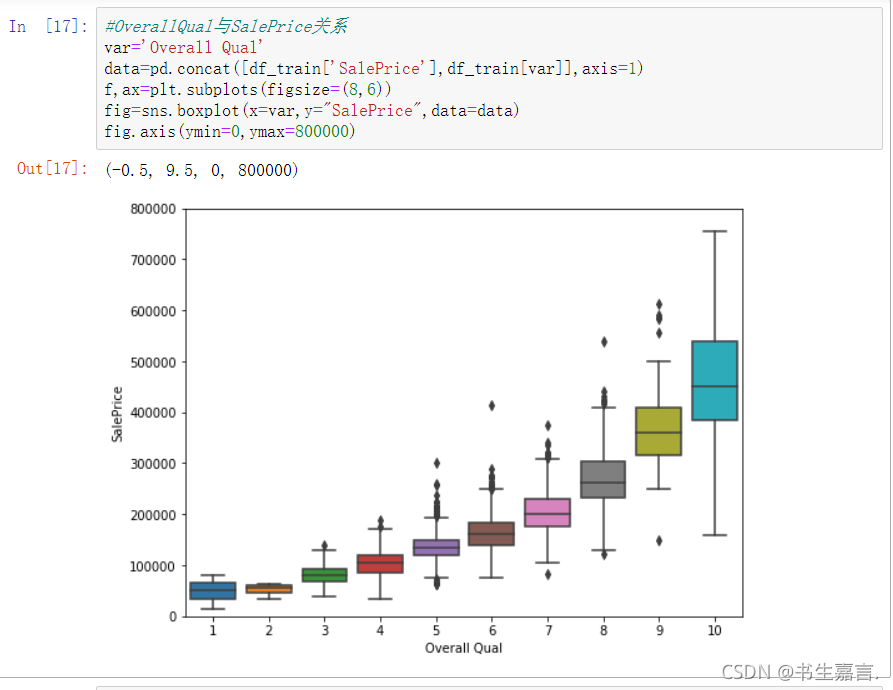
显然,装修质量与房价密切相关。1、2 两个档次的数据过少,导致箱形图不够完整。其他八种装修质量的房价近似正态分布,不同装修质量对房价的影响较为显著。
列变量YearBuilt 表示房屋建筑年代,执行程序段,观察列变量YearBuilt 与SalePrice的关系如图.
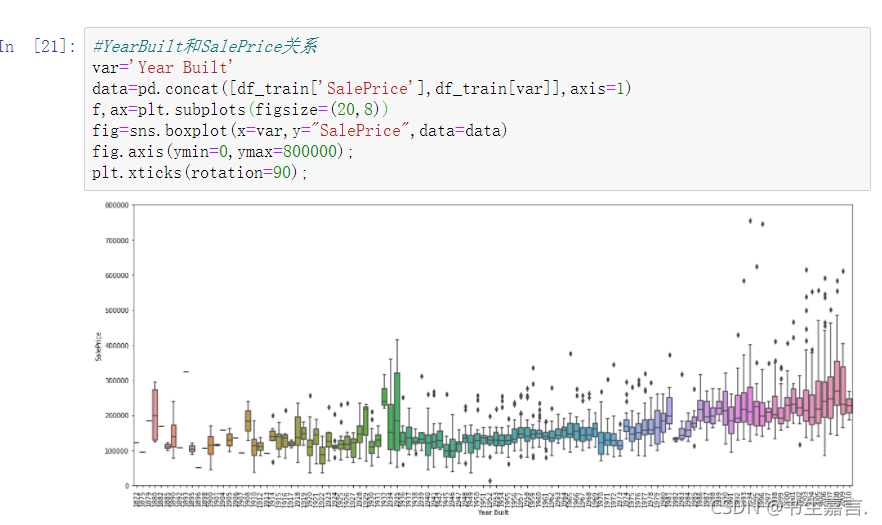
不难看出,同一年代的房屋,房价近似正态分布。但是从1872年到2010年,138年的跨度,如果以50年为一个窗口期,会发现房价的平均波动并不大,从长期趋势看.房价总体呈现缓慢的上升趋势,新建房屋的房价相对高一些。
综上所述,GrLivArea、TotalBsmtSF与SalePrice呈正线性相关,TotalBsmtSF的斜 率更大。OverallQual、 YearBuilt也与SalePrice 相关。不同的OverallQual 差别更为明显,YearBuilt则相对弱一些。
限于篇幅,这里只分析了四个变量。这些分析都是基于直觉观察,主观色彩较浓,接下来介绍一种更为客观的方法:相关矩阵。
4. 相关矩阵
相关系数是度量两个变量间的线性关系的统计量,一般用字母ρ来表示。
公式如下:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 5593
5593

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









