







什么是负载?
负载是服务器运行是否正常的一个风向标,当服务器软件异常时,大部分都会排查线上服务器的负载状况。那么到底什么是负载呢?
在Linux内核调度中,负载的评估指标不是CPU使用率,而是进程处于runnable的平均时间。Linux内核调度包含调度实体负载、CPU负载和系统负载等3个级别的负载计算方式的。其中CPU负载是用来体现当前CPU的工作任务loading情况,和CPU繁忙程度的,其主要通过统计CPU rq上task处于runnable的平均时间。而我们在服务治理中经常提到的负载实际指的是系统负载。
系统负载
我们先通过uptime、top、cat /proc/loadavg等命令查看系统级的平均负载表现
% uptime
23:44 up 11 days, 2:07, 2 users, load averages: 2.54 2.99 3.32
$ top
Processes: 419 total, 2 running, 417 sleeping, 3043 threads 23:43:30
Load Avg: 2.78, 3.11, 3.38 CPU usage: 6.48% user, 5.0% sys, 88.50% idle
$ cat /proc/loadavg
25.72 23.19 23.35 42/3411 43603
“load average:”后面的3个数字分别表示1分钟、5分钟、15分钟的load average。可以从几方面去解析load average:
If the averages are 0.0, then your system is idle.
If the 1 minute average is higher than the 5 or 15 minute averages, then load is increasing.
If the 1 minute average is lower than the 5 or 15 minute averages, then load is decreasing.
If they are higher than your CPU count, then you might have a performance problem (it depends).
关于负载的一种解释:一段时间内处于可运行状态和不可中断状态的进程平均数量。(可运行分为正在运行进程和正在等待CPU的进程,状态为R;不可中断则是它正在做某些工作不能被中断比如等待磁盘IO等,其状态为D),它是从另外一个角度体现CPU的使用状态。
对于可运行状态进程数量,很好理解,CPU使用率高,自然负载升高。但是为什么不可中断状态的进程数也会影响系统负载呢?
在1993的一封邮件中,Linux的设计者觉得这些看似短暂的uninterruptible sleep也要算在runnable中,他举了个例子,如果你把磁盘从快的换成慢的,然后你的系统负载一定是会下降的,但是你在用cpu load的统计方式就很不直观。所以加入了不可中断io的统计,这个指标其实已经在此时从cpu负载变成系统负载了。
实战中如何排查系统负载问题呢
第一步,如何判断负载高低?
使用uptime、top或者查看/proc/loadavg都可以看到CPU的load统计,这里有三个值,分别代表1分钟、5分钟和15分钟的CPU Load情况。大部分人认为这三个数值越小说明比较好,如果越高说明系统可能存在问题或负载过高了。
这几个指标中,偶尔的1分钟内CPU load高,而5-15分钟的load正常,一定程度上是正常的;如果最近15分钟内都很高,就需要关注了。
那怎么样才算高呢?该数值与总核数(即物理CPU个数*每物理CPU的核心数)有关,比如对于总核数为4的机器,CPU load=2就表示系统负载是50%,系统负载就是健康的;如果超过4,就表示已经超过了系统负载了。
第二步,哪些原因导致负载升高?
通过系统负载的定义也可以看出影响系统负载的几个原因:
第一是CPU资源不够,此时一般是可运行状态进程增多;
第二种不可中断状态进程增多,一般是因为大量读请求导致IO成为瓶颈,此时CPU利用率可能不高,但是进程在等待IO过程是不可中断状态,仍然会参与负载计算,从而导致负载升高。
第三步,如何解决负载过高?
通过top查看哪个进程使用率较高,直接杀死这个进程。
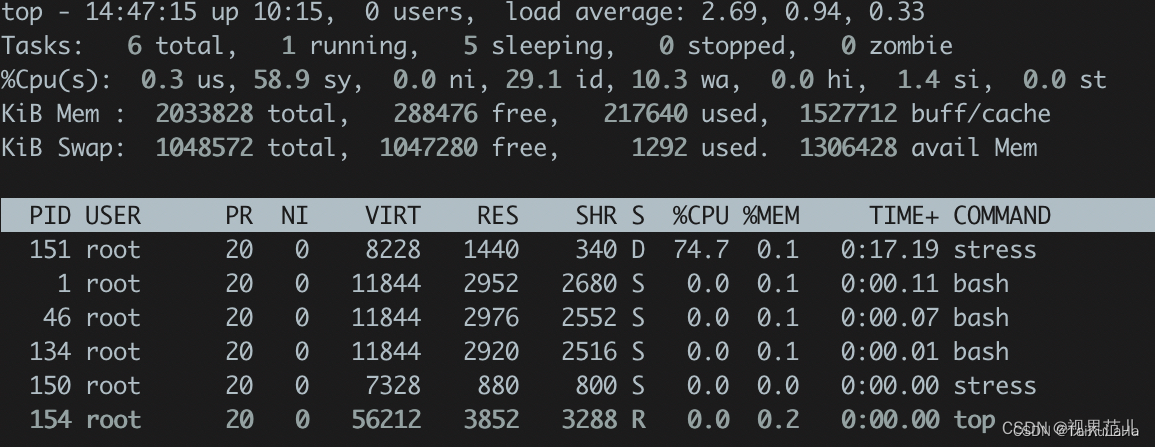
如下图,通过stress测试,其中一个进程CPU使用率攀升。直接kill掉这个进程,load就下来了。
————————————————
版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。
原文链接:https://blog.csdn.net/u010451334/article/details/131446728















 231
231











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









