






https://blog.csdn.net/qq_15111861/article/details/103025418
ORC官网 https://orc.apache.org/
Parquet官网 https://parquet.apache.org/
Hive数仓建表该选用ORC还是Parquet,压缩选LZO还是Snappy? https://zhuanlan.zhihu.com/p/257917645
1 Parquet
Parquet文件是以二进制方式存储的,是不可以直接读取和修改的,Parquet文件是自解析的,文件中包括该文件的数据和元数据。在HDFS文件系统和Parquet文件中存在如下几个概念:
HDFS块(Block):它是HDFS上的最小的副本单位,HDFS会把一个Block存储在本地的一个文件并且维护分散在不同的机器上的多个副本,通常情况下一个Block的大小为256M、512M等。
HDFS文件(File):一个HDFS的文件,包括数据和元数据,数据分散存储在多个Block中。
行组(Row Group):按照行将数据物理上划分为多个单元,每一个行组包含一定的行数,在一个HDFS文件中至少存储一个行组,Parquet读写的时候会将整个行组缓存在内存中,所以如果每一个行组的大小是由内存大的小决定的。
列块(Column Chunk):在一个行组中每一列保存在一个列块中,行组中的所有列连续的存储在这个行组文件中。不同的列块可能使用不同的算法进行压缩。
页(Page):每一个列块划分为多个页,一个页是最小的编码的单位,在同一个列块的不同页可能使用不同的编码方式。

2. ORC
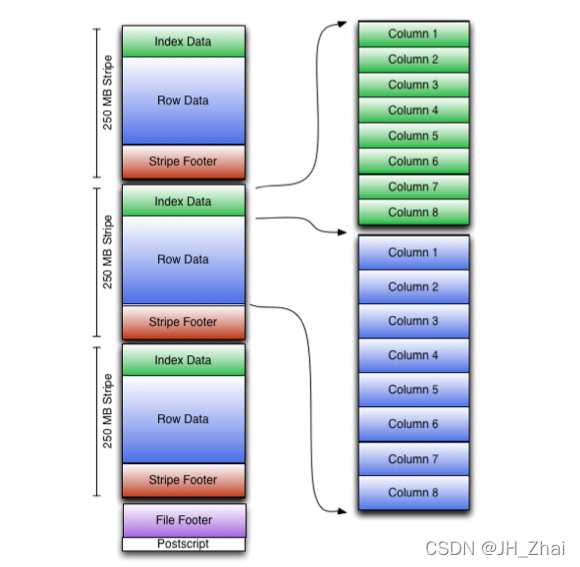
和Parquet类似,ORC文件也是以二进制方式存储的,所以是不可以直接读取,ORC文件也是自解析的,它包含许多的元数据,这些元数据都是同构ProtoBuffer进行序列化的。ORC的文件结构入图6,其中涉及到如下的概念:
ORC文件:保存在文件系统上的普通二进制文件,一个ORC文件中可以包含多个stripe,每一个stripe包含多条记录,这些记录按照列进行独立存储,对应到Parquet中的row group的概念。
文件级元数据:包括文件的描述信息PostScript、文件meta信息(包括整个文件的统计信息)、所有stripe的信息和文件schema信息。
stripe:一组行形成一个stripe,每次读取文件是以行组为单位的,一般为HDFS的块大小,保存了每一列的索引和数据。
stripe元数据:保存stripe的位置、每一个列的在该stripe的统计信息以及所有的stream类型和位置。
row group:索引的最小单位,一个stripe中包含多个row group,默认为10000个值组成。
stream:一个stream表示文件中一段有效的数据,包括索引和数据两类。索引stream保存每一个row group的位置和统计信息,数据stream包括多种类型的数据,具体需要哪几种是由该列类型和编码方式决定。
3 对比
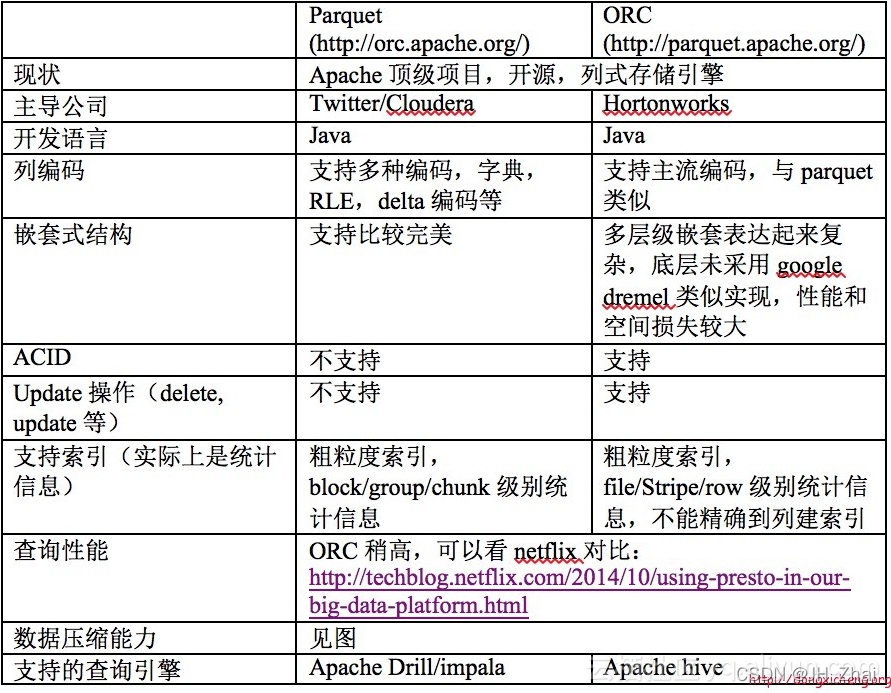

……
-
orc.compress:表示ORC文件的压缩类型,「可选的类型有NONE、ZLB和SNAPPY,默认值是ZLIB(Snappy不支持切片)」—这个配置是最关键的。
-
parquet. compression:默认值为 UNCOMPRESSED,表示页的压缩方式。「可以使用的压缩方式有 UNCOMPRESSED、 SNAPPY、GZP和LZO」。
因为Hive 的SQL会转化为MR任务,如果该文件是用ORC存储,Snappy压缩的,因为Snappy不支持文件分割操作,所以压缩文件「只会被一个任务所读取」,如果该压缩文件很大,那么处理该文件的Map需要花费的时间会远多于读取普通文件的Map时间,这就是常说的「Map读取文件的数据倾斜」。
那么为了避免这种情况的发生,就需要在数据压缩的时候采用bzip2和Zip等支持文件分割的压缩算法。但恰恰ORC不支持刚说到的这些压缩方式,所以这也就成为了大家在可能遇到大文件的情况下不选择ORC的原因,避免数据倾斜。
在Hve on Spark的方式中,也是一样的,Spark作为分布式架构,通常会尝试从多个不同机器上一起读入数据。要实现这种情况,每个工作节点都必须能够找到一条新记录的开端,也就需要该文件可以进行分割,但是有些不可以分割的压缩格式的文件,必须要单个节点来读入所有数据,这就很容易产生性能瓶颈。(下一篇文章详细写Spark读取文件的源码分析)
「所以在实际生产中,使用Parquet存储,lzo压缩的方式更为常见,这种情况下可以避免由于读取不可分割大文件引发的数据倾斜。 但是,如果数据量并不大(预测不会有超大文件,若干G以上)的情况下,使用ORC存储,snappy压缩的效率还是非常高的。」















 1255
1255











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









