







学习获取响应后如何从响应中提取我们需要的数据
响应内容的分类
结构化数据
JSON
可用于解析的模块:
- json模块
- re模块
- jsonpath模块
XML
现在用得比较少了,因为要写开闭标签,传输数据比较大
可用于解析的模块:
- re模块
- lxml模块
非结构化数据
HTML
可用于解析的模块:
- re模块:速度快
- lxml模块:速度中等
- beautifulsoup模块:可以接收xpath,正则,css选择器,速度慢
- pyquery:css选择器
XML与HTML的区别
- html是超文本标记语言,xml是可扩展标记语言,样子和html很像
- xml的标签可以自行定义,而html固定的标签表示固定的意思
- xml专注于数据传输和存储,html专注于显示数据
XPath
Xpath语法
| 语法 | 解释 |
|---|---|
| nodename | 选中该元素 |
| // | 根节点 |
| . | 选取当前节点 |
| … | 选取当前节点的父节点 |
| @ | 选取属性 |
| text() | 选取文本,取标签之间的内容 |
| last() | 选取最后一个 |
选取未知节点的语法:
| 通配符 | 描述 |
|---|---|
| * | 匹配任何一个节点 |
| @* | 匹配任何一个属性值 |
- XPath中第一个元素的索引是1
- XPath中最后一个元素的索引是last()
- XPath中用 / 隔开元素
xpath helper插件
在Chrome中对当前页面测试xpath语法规则
在Chrome网上应用商店上下载
左侧输入了Xpath语法,如果能在源码中找到相关的标签,那么这个标签会被添加上一个特殊的属性class = “xh-highlight”,如果该节点可见,那么可以看到有相应的颜色变化,如果不可见,虽然不可见也会被加上属性
注意右侧的html标签出现了class = "xh highlight"的属性
实践
1. 定位到title:



2. 定位到title 的上一个节点head:
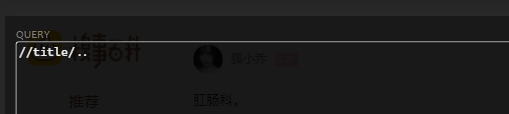

数据提取
text()获取标签之间的数据
这个时候是数据被提取,而不是选中,所以没有自动加highlight属性

@获取属性值

节点修饰语法
通过索引修饰节点

第一条段子在body下的第1个div中的第二个div
RESULTS(25) 说明选中25条
1. 选中每一条段子:

这时可以看到highlight每一条都有

2. 选中倒数第二条段子:
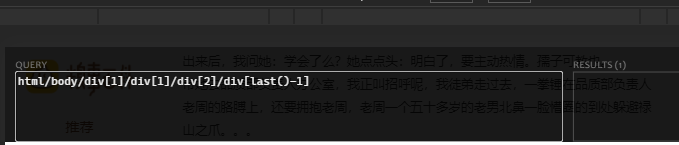

3. 选中前10条以后的:

通过属性值修饰节点
1. 选出特定class的元素:


2. 提取特定class元素的id属性值:
此句中,前面的@是选择,后面的@是从属性中取值

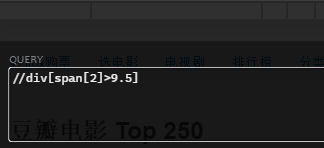
通过子节点的值修饰
1. 找到电影评分 > 9.5 的:

2. 使用contains找到特定元素:


 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3268
3268











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









