






[SlowFast]—ava数据集制作以及训练自己的数据集
1.1、[Ubuntu 安装FFmpeg]
1.2、安装:yasm ,sdl1.2 和 sdl2.0
1.3、测试安装成功与否
二、安装完成之后开始对视频进行处理
2.1、视频准备
2.2、切割视频为图片
三、使用faster rcnn自动框人
3.1、detectron2安装
3.2 via的安装
3.3、新建python脚本
3.4 、图片上传
3.5、运行myvia.py以及修改csv文件
四、via自动标注
4.1、进入via
4.2 导入图片
4.3 导入detection.csv
4.4、快捷键
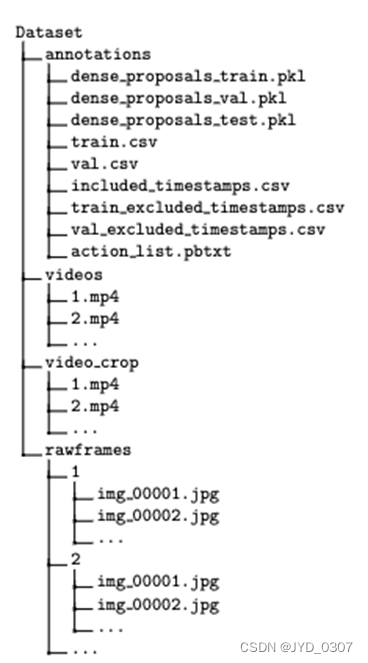
五、数据集文件
5.1、数据集文件总览
5.2、annotations
5.3 frame_lists
5.4 frames
六、slowfast 训练自己的数据集
6.1 预训练模型
6.2 配置文件
6.3、训练过程
前言
本文章借鉴CV-杨帆前辈,主要记录一下自己的复现历程及总结,原文章参考链接如下:
前辈里边有好多都是关于slowfast的博客,觉得本章写的不好的可以看原文章
数据集制作的总流程图:

数据集文件结构如下:
一、安装FFmpeg
原文章链接:
1.1、Ubuntu 18.04 安装FFmpeg
必要安装软件:Anaconda、Pycharm、Cuda、ffmpeg、Via
Anaconda、Pycharm、Cuda这三个软件就不做详细介绍了,大家自己安装就是。
ffmpeg官网链接
下载的同时我们可以先安装这三个必要的库:
1.2、安装:yasm ,sdl1.2 和 sdl2.0
安装yasm
sudo apt-get install yasm
安装
sdl1.2
sudo apt-get install libsdl1.2-dev
安装sdl2.0
sudo apt-get install libstdl2-dev
如果sdl2.0 安装出现错误的话可以选择编译安装方式:
官网下载最新版本:
sdl2.0
解压后进入到目录中,依次执行以下命令:
./configure
make
sudo make install
下载完成之后编译安装FFmpeg
进入到解压之后的 ffmpeg文件夹,依次执行以下命令:
./configure
make
sudo make install
1.3、测试安装成功与否
输入以下命令查看输出:
ffmpeg -version
ffplay -version
二、安装完成之后开始对视频进行处理
【slowfast 训练自己的数据集】自定义动作,制作自己的数据集,使用预训练模型进行训练,并检测其结果
2.1、视频准备
准备2个3秒的视频,最好里面人少一点,减少标注的难度。
下面是使用ffmpeg将一段长视频裁剪为3秒视频的命令。
ffmpeg -ss 00:00:00.0 -to 00:00:3.0 -i "../cutVideo2/1/1.mp4" "../shortVideoTrain/A.mp4"
ffmpeg -ss 00:00:03.0 -to 00:00:06.0 -i "../cutVideo2/1/1.mp4" "../shortVideoTrain/B.mp4"
00:00:00.0为截取视频起始时间
00:00:3.0 为截取视频结束时间
…/cutVideo2/1/1.mp4 为截取该视频的路径
…/shortVideoTrain/A.mp4 为截取完视频后保存的路径
截取完效果如下:

2.2、切割视频为图片
Linux 常用知识点(一):.sh 文件的创建与打开
这里需要把3秒的视频按2种方式切割
第一种是,把视频按照每秒1帧来裁剪,这样裁剪的目的是用来标注,因为ava数据集就是1秒1帧的标志。
命令如下:
首先创建.sh文件
进入到该文件夹路径下,打开终端 依次输入以下内容即可创建并执行 .sh 文件:
创建sh文件(名字自取即可)
touch xxx.sh
对该sh文件进行编辑
gedit xxx.sh
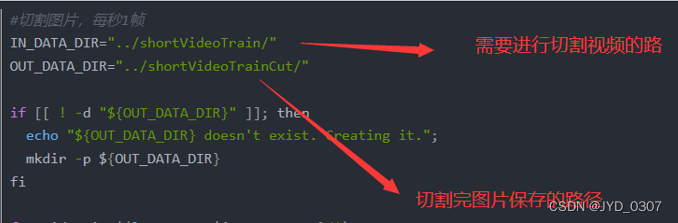
此时会弹出一个可编辑页面,在此可编辑页面中输入:
#切割图片,每秒1帧
IN_DATA_DIR="../shortVideoTrain/"
OUT_DATA_DIR="../shortVideoTrainCut/"
if [[ ! -d "${OUT_DATA_DIR}" ]]; then
echo "${OUT_DATA_DIR} doesn't exist. Creating it.";
mkdir -p ${OUT_DATA_DIR}
fi
for video in $(ls -A1 -U ${IN_DATA_DIR}/*)
do
video_name=${video##*/}
if [[ $video_name = *".webm" ]]; then
video_name=${video_name::-5}
else
video_name=${video_name::-4}
fi
out_video_dir=${OUT_DATA_DIR}/${video_name}/
mkdir -p "${out_video_dir}"
out_name="${out_video_dir}/${video_name}_%06d.jpg"
ffmpeg -i "${video}" -r 1 -q:v 1 "${out_name}"
done
保存上述可编辑页面,然后继续在刚才的终端中输入:
chmod +x xxx.sh
bash xxx.sh
切割结果如下(3秒的视频被切割为5张):

第二种是,把视频按照每秒30帧来裁剪,这样裁剪的目的是,用于slowfast的训练,因为slowfast,在slow流里,1秒会采集到15帧,在fast流里,1秒会采集到2帧。
命令如下:
#切割图片,每秒30帧
IN_DATA_DIR="../shortVideoTrain/"
OUT_DATA_DIR="../shortVideoFrames/"
if [[ ! -d "${OUT_DATA_DIR}" ]]; then
echo "${OUT_DATA_DIR} doesn't exist. Creating it.";
mkdir -p ${OUT_DATA_DIR}
fi
for video in $(ls -A1 -U ${IN_DATA_DIR}/*)
do
video_name=${video##*/}
if [[ $video_name = *".webm" ]]; then
video_name=${video_name::-5}
else
video_name=${video_name::-4}
fi
out_video_dir=${OUT_DATA_DIR}/${video_name}/
mkdir -p "${out_video_dir}"
out_name="${out_video_dir}/${video_name}_%06d.jpg"
ffmpeg -i "${video}" -r 30 -q:v 1 "${out_name}"
done
切割结果如下(3秒的视频被切割为90张):

三、使用faster rcnn自动框人
原文章链接如下:
【faster rcnn 实现via的自动框人】使用detectron2中faster rcnn 算法生成人的坐标,将坐标导入via(VGG Image Annotator)中,实现自动框选出人的区域
【ffmpeg裁剪视频faster rcnn自动检测 via】全自动实现ffmpeg将视频切割为图片帧,再使用faster rcnn将图片中的人检测出来,最后将检测结果转化为via可识别的csv格式
3.1、detectron2安装
detectron2项目地址
detectron2文档
3.2 via的安装
下载及使用指南:via官网
3.3、新建python脚本
在目录/detectron2_repo/demo/下新建一个python脚本,名字为:myvia.py
将下面的代码复制到myvia.py中:
#Copyright (c) Facebook, Inc. and its affiliates.
import argparse
import glob
import multiprocessing as mp
import os
import time
import cv2
import tqdm
import os
from detectron2.config import get_cfg
from detectron2.data.detection_utils import read_image
from detectron2.utils.logger import setup_logger
from predictor import VisualizationDemo
import csv
import pandas as pd #导入pandas包
import re
# constants
WINDOW_NAME = "COCO detections"
def setup_cfg(args):
# load config from file and command-line arguments
cfg = get_cfg()
# To use demo for Panoptic-DeepLab, please uncomment the following two lines.
# from detectron2.projects.panoptic_deeplab import add_panoptic_deeplab_config # noqa
# add_panoptic_deeplab_config(cfg)
cfg.merge_from_file(args.config_file)
cfg.merge_from_list(args.opts)
# Set score_threshold for builtin models
cfg.MODEL.RETINANET.SCORE_THRESH_TEST = args.confidence_threshold
cfg.MODEL.ROI_HEADS.SCORE_THRESH_TEST = args.confidence_threshold
cfg.MODEL.PANOPTIC_FPN.COMBINE.INSTANCES_CONFIDENCE_THRESH = args.confidence_threshold
cfg.freeze()
return cfg
def get_parser():
parser = argparse.ArgumentParser(description="Detectron2 demo for builtin configs")
parser.add_argument(
"--config-file",
default="configs/quick_schedules/mask_rcnn_R_50_FPN_inference_acc_test.yaml",
metavar="FILE",
help="path to config file",
)
parser.add_argument("--webcam", action="store_true", help="Take inputs from webcam.")
parser.add_argument("--video-input", help="Path to video file.")
parser.add_argument(
"--input",
nargs="+",
help="A list of space separated input images; "
"or a single glob pattern such as 'directory/*.jpg'",
)
parser.add_argument(
"--output",
help="A file or directory to save output visualizations. "
"If not given, will show output in an OpenCV window.",
)
parser.add_argument(
"--confidence-threshold",
type=float,
default=0.5,
help="Minimum score for instance predictions to be shown",
)
parser.add_argument(
"--opts",
help="Modify config options using the command-line 'KEY VALUE' pairs",
default=[],
nargs=argparse.REMAINDER,
)
return parser
if __name__ == "__main__":
mp.set_start_method("spawn", force=True)
args = get_parser().parse_args()
setup_logger(name="fvcore")
logger = setup_logger()
logger.info("Arguments: " + str(args))
#图片的输入和输出文件夹
imgOriginalPath = './img/original/'
imgDetectionPath= './img/detection'
# 读取文件下的图片名字
for i,j,k in os.walk(imgOriginalPath):
# k 存储了图片的名字
#imgInputPaths用于存储图片完整地址
imgInputPaths = k
countI=0
for namek in k:
#循环将图片的完整地址加入imgInputPaths中
imgInputPath = imgOriginalPath + namek
imgInputPaths[countI]=imgInputPath
countI = countI + 1
break
#修改args里输入图片的里路径
args.input = imgInputPaths
#修改args里输出图片的路径
args.output = imgDetectionPath
cfg = setup_cfg(args)
demo = VisualizationDemo(cfg)
#创建csv
csvFile = open("./img/detection.csv", "w+",encoding="gbk")
#创建写的对象
CSVwriter = csv.writer(csvFile)
#先写入columns_name
#写入列的名称
CSVwriter.writerow(["filename","file_size","file_attributes","region_count","region_id","region_shape_attributes","region_attributes"])
#写入多行用CSVwriter
#写入多行
#CSVwriter.writerows([[1,a,b],[2,c,d],[3,d,e]])
#csvFile.close()
#https://blog.csdn.net/xz1308579340/article/details/81106310?utm_medium=distribute.pc_relevant.none-task-blog-2%7Edefault%7EBlogCommendFromMachineLearnPai2%7Edefault-3.control&dist_request_id=&depth_1-utm_source=distribute.pc_relevant.none-task-blog-2%7Edefault%7EBlogCommendFromMachineLearnPai2%7Edefault-3.control
if args.input:
if len(args.input) == 1:
args.input = glob.glob(os.path.expanduser(args.input[0]))
assert args.input, "The input path(s) was not found"
for path in tqdm.tqdm(args.input, disable=not args.output):
# use PIL, to be consistent with evaluation
img = read_image(path, format="BGR")
start_time = time.time()
predictions,visualized_output = demo.run_on_image(img)
#只要检测结果是人的目标结果
mask = predictions["instances"].pred_classes == 0
pred_boxes = predictions["instances"].pred_boxes.tensor[mask]
#在路径中正则匹配图片的名称
ImgNameT = re.findall(r'[^\\/:*?"<>|\r\n]+$', path)
ImgName = ImgNameT[0]
#获取图片大小(字节)
ImgSize = os.path.getsize(path)
#下面的为空(属性不管)
img_file_attributes="{"+"}"
#每张图片检测出多少人
img_region_count = len(pred_boxes)
#region_id表示在这张图中,这是第几个人,从0开始数
region_id = 0
#region_attributes 为空
img_region_attributes = "{"+"}"
#循环图中检测出的人的坐标,然后做修改,以适应via
for i in pred_boxes:
#将i中的数据类型转化为可以用的数据类型(list)
iList = i.cpu().numpy().tolist()
#数据取整,并将坐标数据放入到
img_region_shape_attributes = {"\"name\"" : "\"rect\"" , "\"x\"" : int(iList[0]) , "\"y\"" : int(iList[1]) ,"\"width\"" : int(iList[2]-iList[0]) , "\"height\"" : int(iList[3]-iList[1]) }
#将信息写入csv中
CSVwriter.writerow([ImgName,ImgSize,'"{}"',img_region_count,region_id,str(img_region_shape_attributes),'"{}"'])
region_id = region_id + 1
logger.info(
"{}: {} in {:.2f}s".format(
path,
"detected {} instances".format(len(predictions["instances"]))
if "instances" in predictions
else "finished",
time.time() - start_time,
)
)
if args.output:
if os.path.isdir(args.output):
assert os.path.isdir(args.output), args.output
out_filename = os.path.join(args.output, os.path.basename(path))
else:
assert len(args.input) == 1, "Please specify a directory with args.output"
out_filename = args.output
visualized_output.save(out_filename)
else:
cv2.namedWindow(WINDOW_NAME, cv2.WINDOW_NORMAL)
cv2.imshow(WINDOW_NAME, visualized_output.get_image()[:, :, ::-1])
if cv2.waitKey(0) == 27:
break # esc to quit
#关闭csv
csvFile.close()
3.3.1、相关文件
3.3.2 img
在detectron2_repo/目录下新建img文件,这个文件用来存储输入和输出图片

3.3.3、 original、detection、detection.csv
在img文件夹下创建original、detection、detection.csv
original用于存放输入的图片
detection用于存放检测后的图片
detection.csv是faster rcnn算法计算出来的人的坐标数据,然后转换为via可识别的csv文档

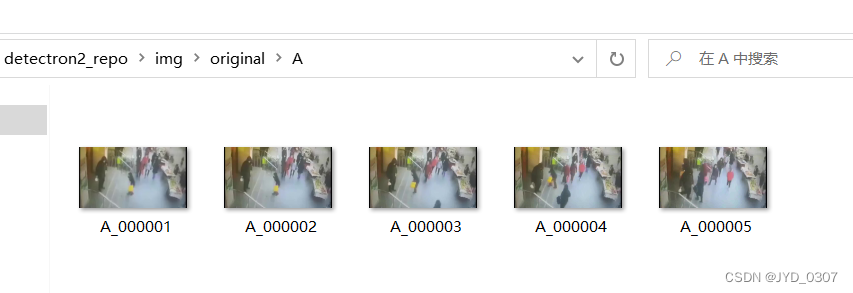
3.4 、图片上传
在original文件夹中上传图片,注意顺序,这个顺序要和后面via图片顺序一致
3.5、运行myvia.py以及修改csv文件
准备好上面的后,就可以运行myvia.py了,将45行的路径改成自己的就可以了,训练结束之后会得到faster rcnn的检测结果以及detection.csv。
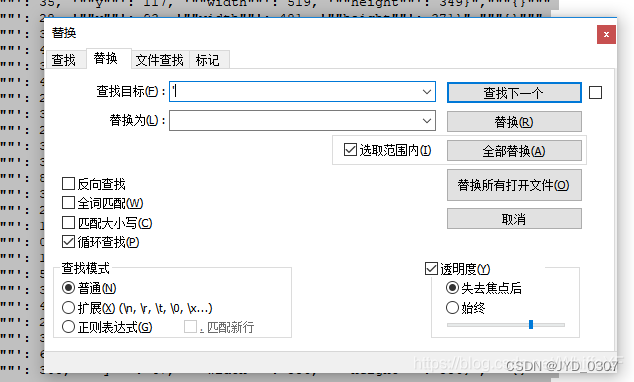
使用文本编辑器打开该csv文件,使用替换功能,把全文的单引号全部删除(使用替换功能,把 ’ 替换为 空),如下图所示:
四、via自动标注
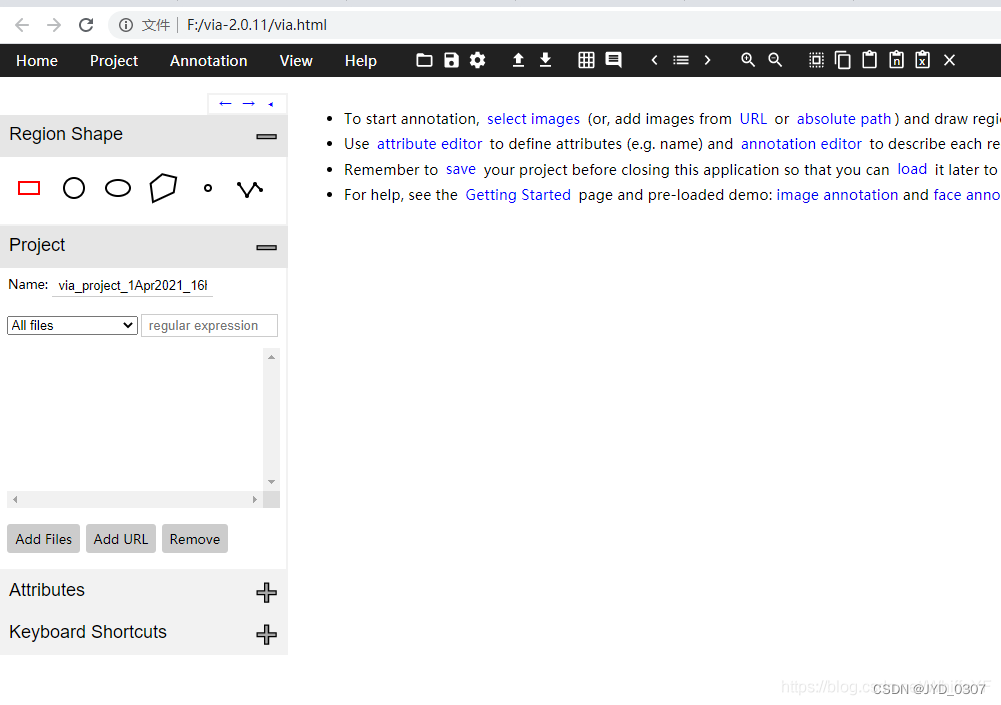
4.1、进入via
进入上述3.2中的via.html中,下图是进入via后的样子
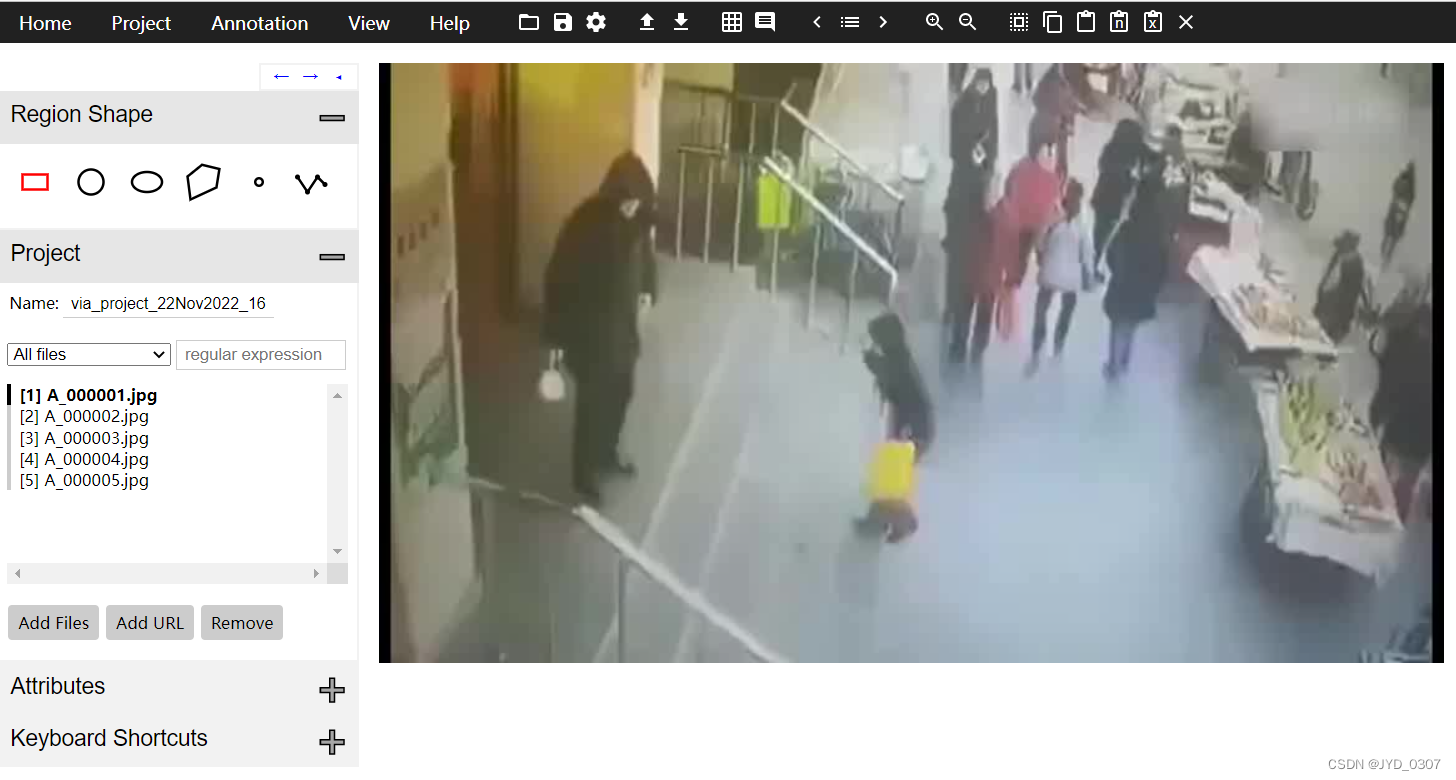
4.2 导入图片
点击下图显示的 Add Files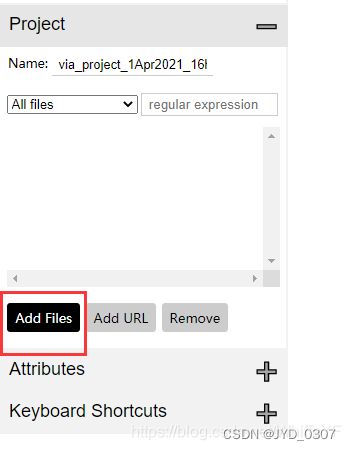
选中原始图图片,即original中保存的图片
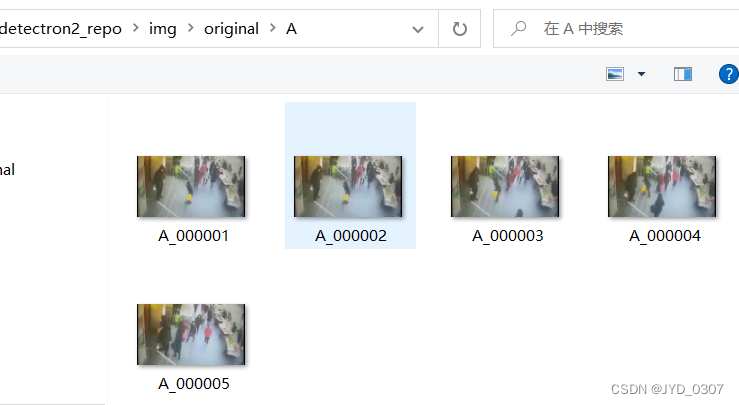
导入图片后的样子
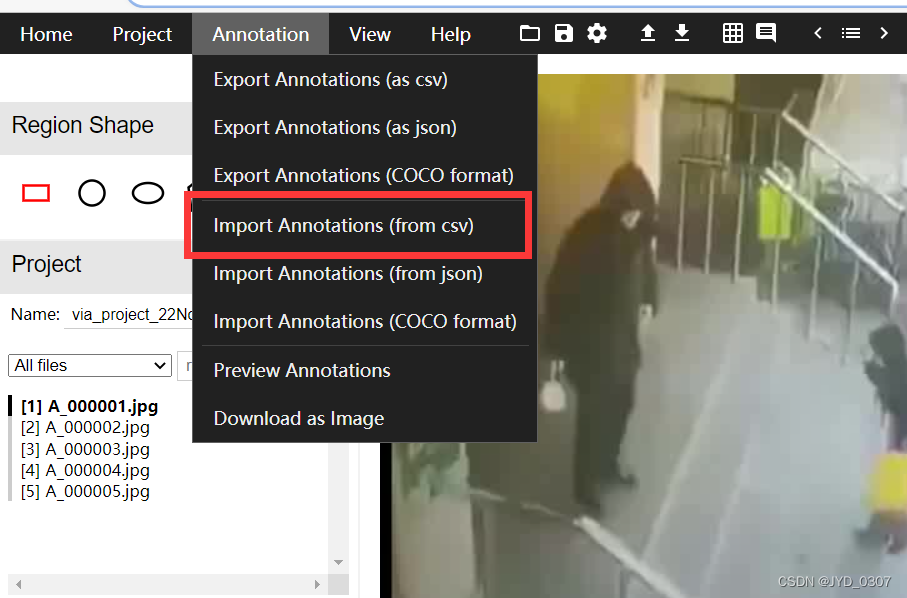
4.3 导入detection.csv
在Annotation中选择 Import Annotations (from csv),在这里把detection.csv添加
导入detection.csv后的效果
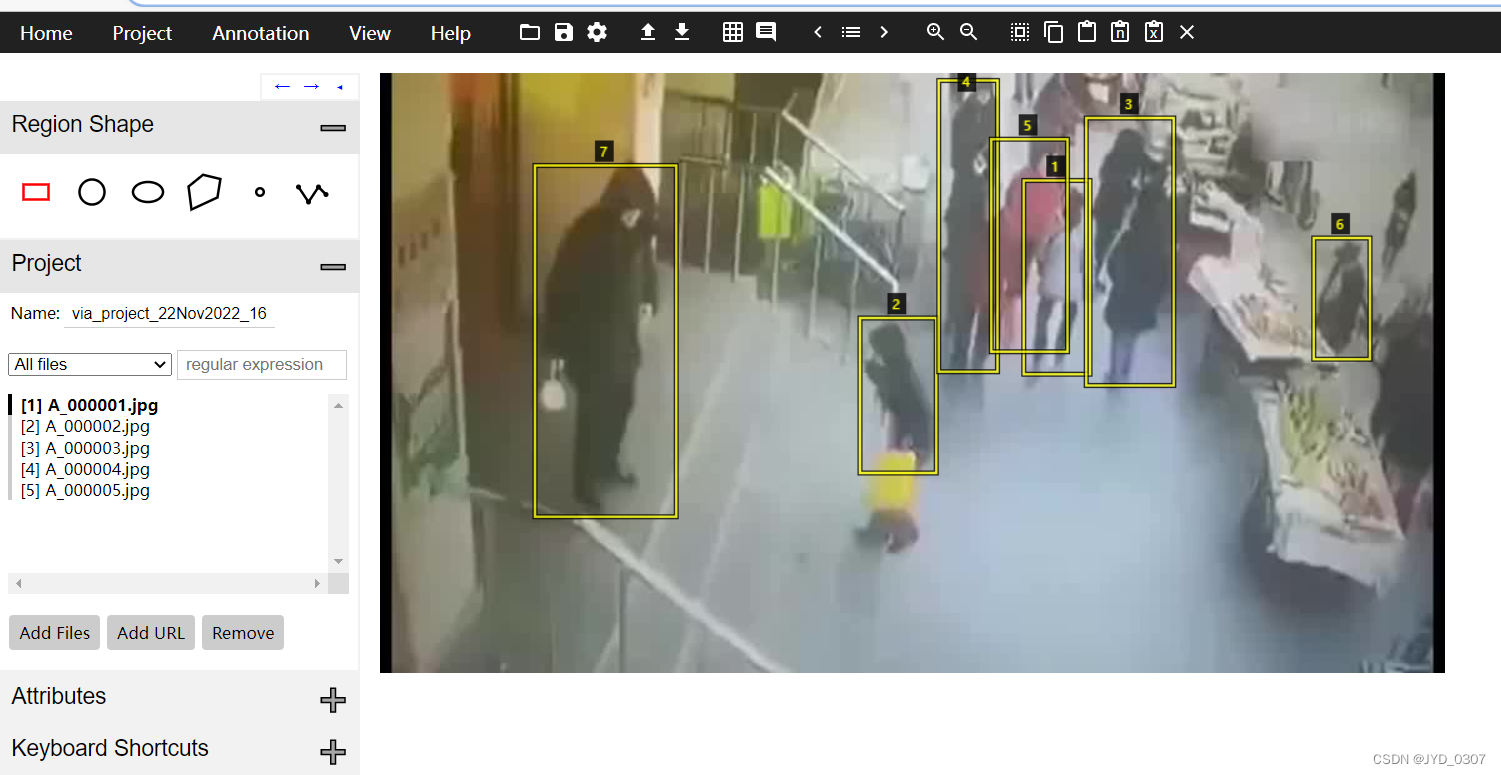
保存标注:

4.4、快捷键
标注快捷键:
下一张:N
上一张:P
空格可以将页面往下翻
五、数据集文件
5.1、数据集文件总览

5.2、annotations
5.2.1 ava_train_v2.2.csv
A,1,0.395,0.230,0.545,0.933,1,0
A,2,0.395,0.235,0.543,0.898,1,0
A,3,0.455,0.237,0.601,0.613,1,0
A,4,0.455,0.232,0.608,0.608,1,0
A,5,0.455,0.230,0.602,0.613,1,0
5.2.2 ava_val_v2.2.csv
B,1,0.455,0.227,0.601,0.613,1,0
B,2,0.455,0.227,0.601,0.611,1,0
B,3,0.455,0.225,0.601,0.611,1,0
B,4,0.455,0.230,0.602,0.616,1,0
B,5,0.455,0.227,0.604,0.611,1,0
5.2.3 ava_val_excluded_timestamps_v2.2.csv
这是空文件
2.2.4 ava_action_list_v2.2_for_activitynet_2019.pbtxt
item {
name: "stand"
id: 1
}
5.2.5 ava_detection_train_boxes_and_labels_include_negative_v2.2.csv
A,1,0.395,0.230,0.545,0.933,1,0.996382
A,2,0.395,0.235,0.543,0.898,1,0.996382
A,3,0.455,0.237,0.601,0.613,1,0.996382
A,4,0.455,0.232,0.608,0.608,1,0.996382
A,5,0.455,0.230,0.602,0.613,1,0.996382
5.2.6 ava_detection_val_boxes_and_labels.csv
B,1,0.455,0.227,0.601,0.613,,0.995518
B,2,0.455,0.227,0.601,0.611,,0.995518
B,3,0.455,0.225,0.601,0.611,,0.995518
B,4,0.455,0.230,0.602,0.616,,0.995518
B,5,0.455,0.227,0.604,0.611,,0.995518
5.3 frame_lists
5.3.1 train.csv
original_vido_id video_id frame_id path labels
A 0 0 A/A_000001.jpg ""
A 0 1 A/A_000002.jpg ""
A 0 2 A/A_000003.jpg ""
A 0 3 A/A_000004.jpg ""
A 0 4 A/A_000005.jpg ""
A 0 5 A/A_000006.jpg ""
A 0 6 A/A_000007.jpg ""
A 0 7 A/A_000008.jpg ""
A 0 8 A/A_000009.jpg ""
A 0 9 A/A_000010.jpg ""
A 0 10 A/A_000011.jpg ""
A 0 11 A/A_000012.jpg ""
A 0 12 A/A_000013.jpg ""
A 0 13 A/A_000014.jpg ""
A 0 14 A/A_000015.jpg ""
A 0 15 A/A_000016.jpg ""
A 0 16 A/A_000017.jpg ""
A 0 17 A/A_000018.jpg ""
A 0 18 A/A_000019.jpg ""
A 0 19 A/A_000020.jpg ""
A 0 20 A/A_000021.jpg ""
A 0 21 A/A_000022.jpg ""
A 0 22 A/A_000023.jpg ""
A 0 23 A/A_000024.jpg ""
A 0 24 A/A_000025.jpg ""
A 0 25 A/A_000026.jpg ""
A 0 26 A/A_000027.jpg ""
A 0 27 A/A_000028.jpg ""
A 0 28 A/A_000029.jpg ""
A 0 29 A/A_000030.jpg ""
A 0 30 A/A_000031.jpg ""
A 0 31 A/A_000032.jpg ""
A 0 32 A/A_000033.jpg ""
A 0 33 A/A_000034.jpg ""
A 0 34 A/A_000035.jpg ""
A 0 35 A/A_000036.jpg ""
A 0 36 A/A_000037.jpg ""
A 0 37 A/A_000038.jpg ""
A 0 38 A/A_000039.jpg ""
A 0 39 A/A_000040.jpg ""
A 0 40 A/A_000041.jpg ""
A 0 41 A/A_000042.jpg ""
A 0 42 A/A_000043.jpg ""
A 0 43 A/A_000044.jpg ""
A 0 44 A/A_000045.jpg ""
A 0 45 A/A_000046.jpg ""
A 0 46 A/A_000047.jpg ""
A 0 47 A/A_000048.jpg ""
A 0 48 A/A_000049.jpg ""
A 0 49 A/A_000050.jpg ""
A 0 50 A/A_000051.jpg ""
A 0 51 A/A_000052.jpg ""
A 0 52 A/A_000053.jpg ""
A 0 53 A/A_000054.jpg ""
A 0 54 A/A_000055.jpg ""
A 0 55 A/A_000056.jpg ""
A 0 56 A/A_000057.jpg ""
A 0 57 A/A_000058.jpg ""
A 0 58 A/A_000059.jpg ""
A 0 59 A/A_000060.jpg ""
A 0 60 A/A_000061.jpg ""
A 0 61 A/A_000062.jpg ""
A 0 62 A/A_000063.jpg ""
A 0 63 A/A_000064.jpg ""
A 0 64 A/A_000065.jpg ""
A 0 65 A/A_000066.jpg ""
A 0 66 A/A_000067.jpg ""
A 0 67 A/A_000068.jpg ""
A 0 68 A/A_000069.jpg ""
A 0 69 A/A_000070.jpg ""
A 0 70 A/A_000071.jpg ""
A 0 71 A/A_000072.jpg ""
A 0 72 A/A_000073.jpg ""
A 0 73 A/A_000074.jpg ""
A 0 74 A/A_000075.jpg ""
A 0 75 A/A_000076.jpg ""
A 0 76 A/A_000077.jpg ""
A 0 77 A/A_000078.jpg ""
A 0 78 A/A_000079.jpg ""
A 0 79 A/A_000080.jpg ""
A 0 80 A/A_000081.jpg ""
A 0 81 A/A_000082.jpg ""
A 0 82 A/A_000083.jpg ""
A 0 83 A/A_000084.jpg ""
A 0 84 A/A_000085.jpg ""
A 0 85 A/A_000086.jpg ""
A 0 86 A/A_000087.jpg ""
A 0 87 A/A_000088.jpg ""
A 0 88 A/A_000089.jpg ""
A 0 89 A/A_000090.jpg ""
5.3.2 val.csv
originBl_vido_id video_id frBme_id pBth lBbels
B 1 0 B/B_000001.jpg ""
B 1 1 B/B_000002.jpg ""
B 1 2 B/B_000003.jpg ""
B 1 3 B/B_000004.jpg ""
B 1 4 B/B_000005.jpg ""
B 1 5 B/B_000006.jpg ""
B 1 6 B/B_000007.jpg ""
B 1 7 B/B_000008.jpg ""
B 1 8 B/B_000009.jpg ""
B 1 9 B/B_000010.jpg ""
B 1 10 B/B_000011.jpg ""
B 1 11 B/B_000012.jpg ""
B 1 12 B/B_000013.jpg ""
B 1 13 B/B_000014.jpg ""
B 1 14 B/B_000015.jpg ""
B 1 15 B/B_000016.jpg ""
B 1 16 B/B_000017.jpg ""
B 1 17 B/B_000018.jpg ""
B 1 18 B/B_000019.jpg ""
B 1 19 B/B_000020.jpg ""
B 1 20 B/B_000021.jpg ""
B 1 21 B/B_000022.jpg ""
B 1 22 B/B_000023.jpg ""
B 1 23 B/B_000024.jpg ""
B 1 24 B/B_000025.jpg ""
B 1 25 B/B_000026.jpg ""
B 1 26 B/B_000027.jpg ""
B 1 27 B/B_000028.jpg ""
B 1 28 B/B_000029.jpg ""
B 1 29 B/B_000030.jpg ""
B 1 30 B/B_000031.jpg ""
B 1 31 B/B_000032.jpg ""
B 1 32 B/B_000033.jpg ""
B 1 33 B/B_000034.jpg ""
B 1 34 B/B_000035.jpg ""
B 1 35 B/B_000036.jpg ""
B 1 36 B/B_000037.jpg ""
B 1 37 B/B_000038.jpg ""
B 1 38 B/B_000039.jpg ""
B 1 39 B/B_000040.jpg ""
B 1 40 B/B_000041.jpg ""
B 1 41 B/B_000042.jpg ""
B 1 42 B/B_000043.jpg ""
B 1 43 B/B_000044.jpg ""
B 1 44 B/B_000045.jpg ""
B 1 45 B/B_000046.jpg ""
B 1 46 B/B_000047.jpg ""
B 1 47 B/B_000048.jpg ""
B 1 48 B/B_000049.jpg ""
B 1 49 B/B_000050.jpg ""
B 1 50 B/B_000051.jpg ""
B 1 51 B/B_000052.jpg ""
B 1 52 B/B_000053.jpg ""
B 1 53 B/B_000054.jpg ""
B 1 54 B/B_000055.jpg ""
B 1 55 B/B_000056.jpg ""
B 1 56 B/B_000057.jpg ""
B 1 57 B/B_000058.jpg ""
B 1 58 B/B_000059.jpg ""
B 1 59 B/B_000060.jpg ""
B 1 60 B/B_000061.jpg ""
B 1 61 B/B_000062.jpg ""
B 1 62 B/B_000063.jpg ""
B 1 63 B/B_000064.jpg ""
B 1 64 B/B_000065.jpg ""
B 1 65 B/B_000066.jpg ""
B 1 66 B/B_000067.jpg ""
B 1 67 B/B_000068.jpg ""
B 1 68 B/B_000069.jpg ""
B 1 69 B/B_000070.jpg ""
B 1 70 B/B_000071.jpg ""
B 1 71 B/B_000072.jpg ""
B 1 72 B/B_000073.jpg ""
B 1 73 B/B_000074.jpg ""
B 1 74 B/B_000075.jpg ""
B 1 75 B/B_000076.jpg ""
B 1 76 B/B_000077.jpg ""
B 1 77 B/B_000078.jpg ""
B 1 78 B/B_000079.jpg ""
B 1 79 B/B_000080.jpg ""
B 1 80 B/B_000081.jpg ""
B 1 81 B/B_000082.jpg ""
B 1 82 B/B_000083.jpg ""
B 1 83 B/B_000084.jpg ""
B 1 84 B/B_000085.jpg ""
B 1 85 B/B_000086.jpg ""
B 1 86 B/B_000087.jpg ""
B 1 87 B/B_000088.jpg ""
B 1 88 B/B_000089.jpg ""
B 1 89 B/B_000090.jpg ""
5.4 frames
这里的存放我们在第一部分切割的图片,1秒切割30张的那个文件:
六、slowfast 训练自己的数据集
在以上部分,我们把需要准备的东西都准备好了,下一步就是在slowfast修改训练所需要的代码。
6.1 预训练模型
最好使用预训练模型,这样可以缩短训练的一个时间,我用的预训练模型如下图
预训练模型
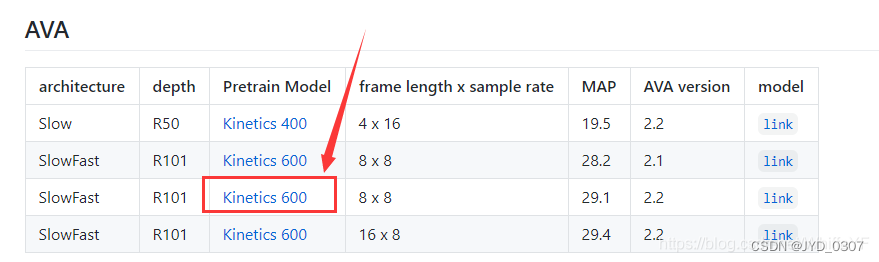
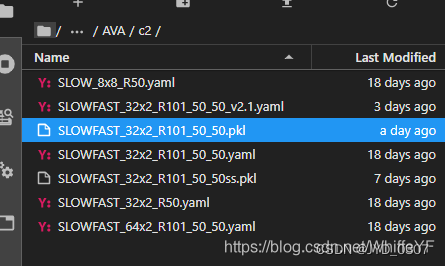
下载下来后,放在文件夹/SlowFast/configs/AVA/c2/下面,如下图:
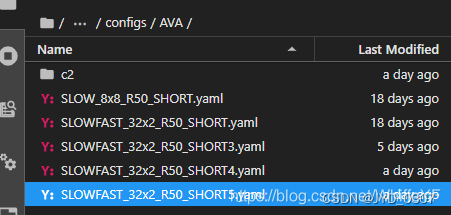
6.2 配置文件
在/SlowFast/configs/AVA/下创建一个新的yaml文件:SLOWFAST_32x2_R50_SHORT5.yaml,如下图:
SLOWFAST_32x2_R50_SHORT5.yaml代码如下:
TRAIN:
ENABLE: True
DATASET: ava
BATCH_SIZE: 2 #64
EVAL_PERIOD: 5
CHECKPOINT_PERIOD: 1
AUTO_RESUME: True
CHECKPOINT_FILE_PATH: '/home/jing/Downloads/file_recv/SLOWFAST_32x2_R101_50_50111.pkl' #path to pretrain model
CHECKPOINT_TYPE: caffe2
DATA:
NUM_FRAMES: 32
SAMPLING_RATE: 2
TRAIN_JITTER_SCALES: [256, 320]
TRAIN_CROP_SIZE: 224
TEST_CROP_SIZE: 224
INPUT_CHANNEL_NUM: [3, 3]
PATH_TO_DATA_DIR: '/home/jing/mySelfSlowFast/myCustomava'
DETECTION:
ENABLE: True
ALIGNED: True
AVA:
FULL_TEST_ON_VAL: True
FRAME_DIR: '/home/jing/mySelfSlowFast/myCustomava/frames'
FRAME_LIST_DIR: '/home/jing/mySelfSlowFast/myCustomava/frames_lists'
ANNOTATION_DIR: '/home/jing/mySelfSlowFast/myCustomava/annotations'
DETECTION_SCORE_THRESH: 0.8
TRAIN_PREDICT_BOX_LISTS: [
"ava_train_v2.2.csv",
"person_box_67091280_iou90/ava_detection_train_boxes_and_labels_include_negative_v2.2.csv",
]
TEST_PREDICT_BOX_LISTS: ["person_box_67091280_iou90/ava_detection_val_boxes_and_labels.csv"]
SLOWFAST:
ALPHA: 4
BETA_INV: 8
FUSION_CONV_CHANNEL_RATIO: 2
FUSION_KERNEL_SZ: 7
RESNET:
ZERO_INIT_FINAL_BN: True
WIDTH_PER_GROUP: 64
NUM_GROUPS: 1
DEPTH: 50
TRANS_FUNC: bottleneck_transform
STRIDE_1X1: False
NUM_BLOCK_TEMP_KERNEL: [[3, 3], [4, 4], [6, 6], [3, 3]]
SPATIAL_DILATIONS: [[1, 1], [1, 1], [1, 1], [2, 2]]
SPATIAL_STRIDES: [[1, 1], [2, 2], [2, 2], [1, 1]]
NONLOCAL:
LOCATION: [[[], []], [[], []], [[], []], [[], []]]
GROUP: [[1, 1], [1, 1], [1, 1], [1, 1]]
INSTANTIATION: dot_product
POOL: [[[1, 2, 2], [1, 2, 2]], [[1, 2, 2], [1, 2, 2]], [[1, 2, 2], [1, 2, 2]], [[1, 2, 2], [1, 2, 2]]]
BN:
USE_PRECISE_STATS: False
NUM_BATCHES_PRECISE: 200
SOLVER:
BASE_LR: 0.1
LR_POLICY: steps_with_relative_lrs
STEPS: [0, 10, 15, 20]
LRS: [1, 0.1, 0.01, 0.001]
MAX_EPOCH: 20
MOMENTUM: 0.9
WEIGHT_DECAY: 1e-7
WARMUP_EPOCHS: 5.0
WARMUP_START_LR: 0.000125
OPTIMIZING_METHOD: sgd
MODEL:
NUM_CLASSES: 2
ARCH: slowfast
MODEL_NAME: SlowFast
LOSS_FUNC: bce
DROPOUT_RATE: 0.5
HEAD_ACT: sigmoid
TEST:
ENABLE: False
DATASET: ava
BATCH_SIZE: 8
DATA_LOADER:
NUM_WORKERS: 2
PIN_MEMORY: True
NUM_GPUS: 1
NUM_SHARDS: 1
RNG_SEED: 0
OUTPUT_DIR: .
有几个需要注意的地方:
1,TRAIN:CHECKPOINT_FILE_PATH 就是我们下载的与训练模型的位置
2,DATA:PATH_TO_DATA_DIR 就是我们第二部分制作的数据集文件
3,AVA: 下面的路径也是对应第二部分数据集文件对应的地方
4,MODEL:NUM_CLASSES: 1 这里是最需要主义的,这里classes必需为1,因为我们只有stand这一个分类。
6.3、训练过程
将SlowFast项目中的run_net.py中读取的yaml路径修改为我们自己的路径,就可以运行了。
最后,拿到训练好的权重去检测自己的视频,检测参考原文章:
【SlowFast复现】SlowFast Networks for Video Recognition复现代码 使用自己的视频进行demo检测















 304
304











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









