






一、文本表示
文本表示是将自然语言转化为计算机能够理解的数值形式,是绝大多数自然语言处理(NLP)任务的基础步骤。
1.分词(Tokenization)
是将原始文本切分为若干具有独立语义的最小单元(即token)的过程,是所有 NLP 任务的起点。
不同语言由于语言结构、词边界的差异,其分词策略和算法也不尽相同,本节将分别介绍英文与中文中常见的分词方式。
1.1 中文分词
中文的语言结构与英文存在显著差异,我们仍可以借助“分词粒度”的视角,对中文的分词方式进行归类和分析。
1.1.1字符级分词
字符级分词是中文处理中最简单的一种方式,即将文本按照单个汉字进行切分,文本中的每一个汉字都被视为一个独立的 token。
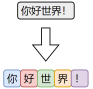
由于汉字本身通常具有独立语义,因此字符级分词在中文中具备天然的可行性。相比英文中的字符分词,中文的字符分词更加“语义友好”。
1.1.2词级分词
词级分词是将中文文本按照完整词语进行切分的传统方法,切分结果更贴近人类阅读习惯。
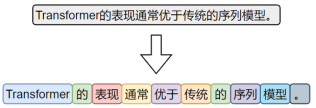
由于中文没有空格等天然词边界,词级分词通常依赖词典、规则或模型来识别词语边界。
1.1.3 子词级分词
虽然中文没有英文中的子词结构(如前缀、后缀、词根等),但子词分词算法(如 BPE)仍可直接应用于中文。它们以汉字为基本单位,通过学习语料中高频的字组合(如“自然”、“语言”、“处理”),自动构建子词词表。这种方式无需人工词典,具有较强的适应能力。
在当前主流的中文大模型(如通义千问、DeepSeek)中,子词分词已成为广泛采用的文本切分策略。
1.1.4 BPE
BPE 是最早被广泛应用的方法,其需要先从语料中学习一个子词词表,基本原理是:首先将所有词语拆分为单个字符,然后迭代地统计语料中出现频率最高的字符对,将其合并为一个新的子词,并加入词表。该过程持续进行,直到达到设定的词表大小。
然后再根据词表对新输入的文本进行分词,其基本原理是:从输入文本的第一个字符开始,优先选择词表中能够匹配的最长子词单元,然后继续处理剩余部分,直到完成整个序列的切分。
子词级分词已经成为现代英文 NLP 模型中的主流方法,如 BERT、GPT等模型均采用了基于子词的分词机制。
2. 分词工具
目前市面上可用于中文分词的工具种类繁多,按照实现方式大致可以分为如下两类:
一类是基于词典或模型的传统方法,主要以“词”为单位进行切分;
另一类是基于子词建模算法(如BPE)的方式,从数据中自动学习高频字组合,构建子词词表。
前者的代表工具包括 jieba、HanLP等,这些工具广泛应用于传统 NLP 任务中。
后者的代表工具包括 Hugging Face Tokenizer、SentencePiece、tiktoken等,常用于大规模预训练语言模型中。
2.1 jieba分词器
2.1.1 分词模式
(1)精确模式(默认)
试图将句子最精确地切开,适合文本分析。
import jieba
text = "C罗是世界上最好的球员"
words_generator = jieba.cut(text) # 返回一个生成器
for word in words_generator:
print(word)
words_list = jieba.lcut(text) # 返回一个列表
print(words_list)
(2)全模式
把句子中所有的可以成词的词语都扫描出来
words_list = jieba.lcut(text, cut_all=True) # 返回一个列表
(3)搜索引擎模式
words_list = jieba.lcut_for_search(text) # 返回一个列表
(4)自定义词典
jieba支持用户自定义词典,以便包含 jieba 词库里没有的词,用于增强特定领域词汇的识别能力。
自定义词典的格式为:一个词占一行,每一行分三部分:词语、词频(可省略,词频决定某个词在分词时的优先级。词频越高被优先切分出来的概率越大)、词性标签(可省略,不影响分词结果),用空格隔开,顺序不可颠倒。例如
C罗
jieba.load_userdict('dict.txt')
words_list = jieba.lcut(text)
print(words_list)
3. 词表示
在分词完成之后,文本被转换为一系列的 token(词、子词或字符)。然而,这些符号本身对计算机而言是不可计算的。因此,为了让模型能够理解和处理文本,必须将这些 token 转换为计算机可以识别和操作的数值形式,这一步就是所谓的词表示(word representation)。
词表示的发展经历了从稀疏的one-hot编码,到稠密的语义化词向量,再到近年来的上下文相关的词表示。不同的词表示方法在表达能力、语义建模、上下文适应性等方面存在显著差异。
3.1 One-hot编码
最早期的词向量表示方式是 One-hot 编码:它将词汇表中的每个词映射为一个稀疏向量,向量的长度等于整个词表的大小。该词在对应的位置为 1,其他位置为 0。
one-hot 虽然实现简单、直观易懂,但它无法体现词与词之间的语义关系,且随着词表规模的扩大,向量维度会迅速膨胀,导致计算效率低下。因此,在实际自然语言处理任务中,one-hot 表示已经很少被直接使用。
3.2 语义化词向量
传统的one-hot表示虽然结构简单,但它无法反映词语之间的语义关系,也无法衡量词与词之间的相似度。为了解决这个问题,研究者提出了Word2Vec模型,它通过对大规模语料的学习,为每个词生成一个具有语义意义的稠密向量表示。这些向量能够在连续空间中表达词与词之间的关系,使得“意思相近”的词在空间中距离更近。
3.2.1 Word2Vec概述
Word2Vec的设计理念源自“分布假设”——即一个词的含义由它周围的词决定。
基于这一假设,Word2Vec构建了一个简洁的神经网络模型,通过学习词与上下文之间的关系,自动为每个词生成一个能够反映语义特征的向量表示。
Word2Vec提供了两种典型的模型结构,用于实现对词向量的学习:
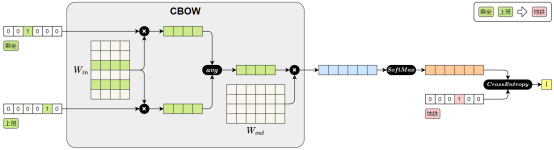
CBOW(Continuous Bag-of-Words)模型
输入是一个词的上下文(即前后若干个词),模型的目标是预测中间的目标词
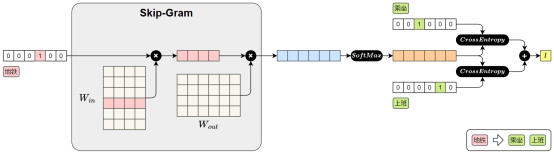
Skip-Gram 模型
3.3 Gensim
3.3.1 使用公开词向量
词向量文件的格式为:第一行记录基本信息,包括两个整数,分别表示总词数和词向量维度。从第二行起,每一行表示一个词及其对应的词向量,格式为:词 + 向量的各个维度值。所有内容通过空格分隔,该格式已成为自然语言处理领域中广泛接受的约定俗成的通用格式。
from gensim.models import KeyedVectors
model_path = 'sgns.weibo.word.bz2'
model = KeyedVectors.load_word2vec_format(model_path)
查看词向量维度
print(model.vector_size)
查看某个词的向量
print(model['地铁'])
查看两个向量的相似度
similarity = model.similarity('地铁', '公交')
print('地铁 vs 公交 相似度:', similarity)
找出与某个词最相似的词
similar_words = model.most_similar(positive=["上班"], topn=5)
print(similar_words)
result = model.most_similar(positive=["爸爸", "女性"], negative=["男性"], topn=3)
print(result)
3.3.2 自行训练词向量
(1)准备语料
Word2Vec的训练语料需要是已分词的文本序列,格式为:
sentences = [['我', '每天','乘坐', '地铁', '上班'], ['我','每天', '乘坐', '公交', '上班']]
(2)训练模型
from gensim.models import Word2Vec
model = Word2Vec(
sentences, # 已分词的句子序列
vector_size=100, # 词向量维度
window=5, # 上下文窗口大小
min_count=2, # 最小词频(低于将被忽略)
sg=1, # 1:Skip-Gram,0:CBOW
workers=4 # 并行训练线程数
)
(3)保存词向量
model.wv.save_word2vec_format('my_vectors.kv')
(4)加载词向量
from gensim.models import KeyedVectors
my_model = KeyedVectors.load_word2vec_format('my_vectors.kv')
4. 完整流程
import jieba
from gensim.models import Word2Vec, KeyedVectors
import pandas as pd
df = pd.read_csv('online_shopping_10_cats.csv', encoding='utf-8', usecols=['review'])
sentences = [[token for token in jieba.lcut(review) if token.strip() != ''] for review in df["review"]]
model = Word2Vec(
sentences, # 已分词的句子序列
vector_size=100, # 词向量维度
window=5, # 上下文窗口大小
min_count=2, # 最小词频(低于将被忽略)
sg=1, # 1 = Skip-Gram,0 = CBOW
workers=4 # 并行训练线程数
)
model.wv.save_word2vec_format('my_vectors.kv')
my_model = KeyedVectors.load_word2vec_format('my_vectors.kv')
print(my_model)
5. 嵌入层
在现代深度学习的 NLP 模型中,大多数任务的输入第一层都是嵌入层。本质上,嵌入层就是一个查找表(lookup table):输入是词在词汇表中的索引;输出是该词对应的向量表示。
嵌入层的参数矩阵可以有两种典型的初始化方式:
随机初始化
模型训练开始时,嵌入向量是随机生成的,模型会通过反向传播逐步学习每个词的表示。
使用预训练词向量初始化
加载训练好的词向量(如 Word2Vec)到嵌入层中作为初始参数,这样可以为模型注入丰富的语言知识,尤其在低资源任务中优势明显。并且,加载预训练词向量后,可选择是否让嵌入层继续参与训练。
下面以PyTorch为例,演示如何使用预训练词向量初始化Embedding层
import torch
import torch.nn as nn
from gensim.models import KeyedVectors
import jieba
#1.加载训练好的文件
my_model = KeyedVectors.load_word2vec_format('../data/word2vec.txt')
print(my_model) # KeyedVectors<vector_size=100, 34576 keys>
#2.构建词表和词向量矩阵
embedding_dim = my_model.vector_size
num_embeddings = len(my_model.vectors)
embeddings_matrix = torch.zeros(num_embeddings,embedding_dim )
for i,key in enumerate(my_model.key_to_index):
embeddings_matrix[i] = torch.tensor(my_model[key])
#3.构建 PyTorch 的嵌入层
embedding = nn.Embedding.from_pretrained(embeddings_matrix, freeze=True)
#4.将词索引转换为向量
text = '我喜欢足球'
words_list = jieba.lcut(text)
index_key = [my_model.key_to_index[word] for word in words_list]
input_tensor = torch.tensor(index_key)
#查询嵌入
embed = embedding(input_tensor)


















 887
887

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









