




NLP学习笔记
第一章 NLP学习笔记–文本表示
第二章 NLP学习笔记–RNN
第三章 NLP学习笔记–LSTM
第四章 NLP学习笔记–GRU
第五章 NLP学习笔记–Seq2Seq
第六章 NLP学习笔记–Attention机制
Gated Recurrent Unit(GRU)是为了进一步简化 LSTM 结构、降低计算成本而提出的一种变体。GRU 保留了门控机制的核心思想,但相比 LSTM,结构更为简洁,参数更少,训练效率更高。
在许多实际任务中,GRU 能在保持类似性能的同时,显著减少训练时间。
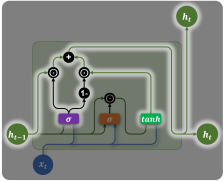
基础结构
与LSTM相比,GRU做出了以下改进:
取消了LSTM中独立的记忆单元,只保留隐藏状态。
通过两个门控结构控制信息流动:更新门(Update Gate)和 重置门(Reset Gate)。
具体结构如下图所示:
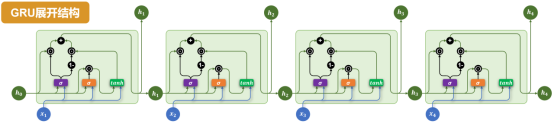
各部分说明如下:
重置门(Reset Gate)
重置门由上一个时间步的隐藏状态和当前时间步的输入计算得到:
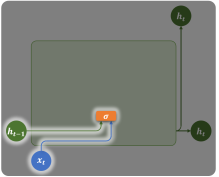
计算公式如下:

重置门会在计算当前时间步信息(候选隐藏状态)时,作用在上一个时间步的隐藏状态,用于控制遗忘多少旧信息,如下图所示:
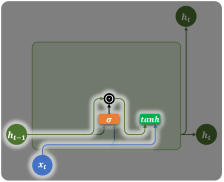
当前时间步的信息(候选隐藏状态)的计算公式为:

更新门(Update Gate)
更新门也由上一时间步的隐藏状态和当前时间步的输入计算得到,如下图所示
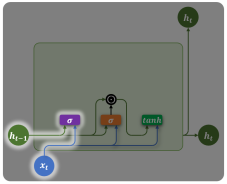
计算公式为

更新门会在计算当前时间步最终的隐藏状态ht时,分别作用在上一时刻的隐藏状态ht−1和当前新计算出的候选隐藏状态ht,用于控制保留多少旧信息,以及引入多少新信息。
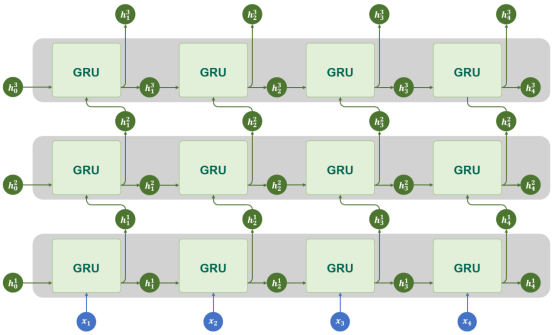
多层结构
GRU同样支持多层结构
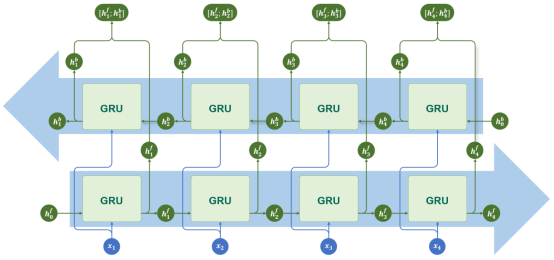
双向结构
GRU同样支持双向结构
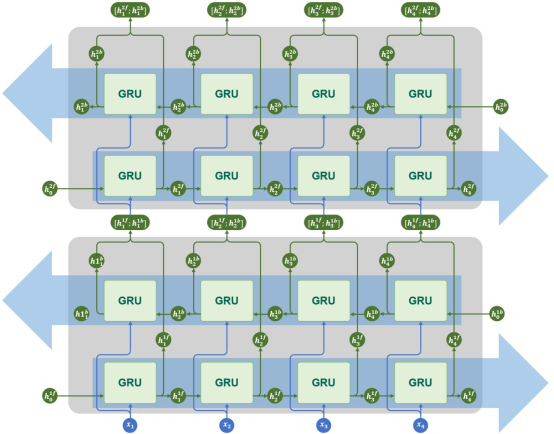
多层+双向结构
GRU同样支持多层结构和双向结构
API使用
torch.nn.GRU 是 PyTorch 中实现门控循环单元(Gated Recurrent Unit, GRU)的模块。它用于对序列数据建模,在自然语言处理(NLP)、时间序列预测等任务中广泛使用。该模块支持单层或多层 GRU,可选择是否使用双向结构(bidirectional)。
torch.nn.GRU与torch.nn.RNN的API几乎完全相同。
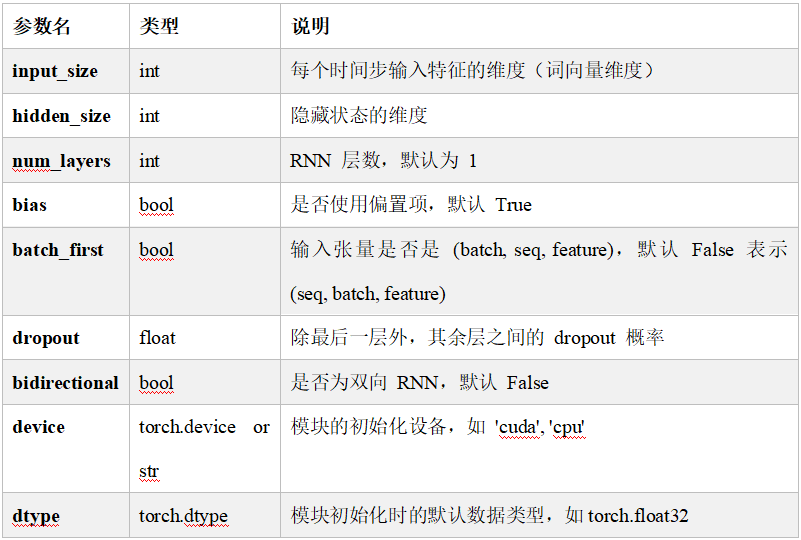
参数说明
构造GRU层所需的参数如下:
torch.nn.GRU(input_size, hidden_size, num_layers=1, bias=True, batch_first=False, dropout=0.0, bidirectional=False, device=None, dtype=None)
各参数含义如下
输入输出
示例代码如下
gru= torch.nn.GRU()
output, h_n = gru(input, h_0)
输入输出内容如下

存在问题
GRU 在简化结构、提高训练效率方面表现优秀,但在超长依赖建模、灵活性和并行计算方面仍存在天然限制。


















 370
370

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









