






1.逻辑回归
逻辑回归是一种线性回归模型,它假设数据服从伯努力分布(二项分布,0-1分布),通过极大似然估计,运用梯度下降方法(牛顿法) 求解,进而达到二分类目的。逻辑回归与线性回归有很多相似之处,去除Sigmoid映射函数的话,逻辑回归算法就是一个线性回归。逻辑回归以线性回归理论作为支持。由于引入了Sigmoid函数,可以处理非线性问题,因此可以轻松处理0/1分布问题。
2.伯努利(Binomial)分布
伯努利分布又称为0-1分布、两点分布,通常对应事物的正反两面(成功与失败,是与否,正面与反面),指的是对于随机变量X有, 参数为p(0
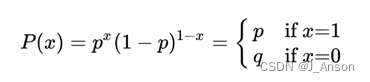
其中上式的x只能取0或者1,1表示事件发生,0表示事件不发生。
3.Sigmoid函数与逻辑回归函数
Sigmoid函数公式如下:
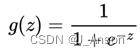
这个公式有很多好的特性,g(z)函数值范围是(0,1)区间,当z取0时,值为0.5;远离0的地方,函数值很快接近0或者1。
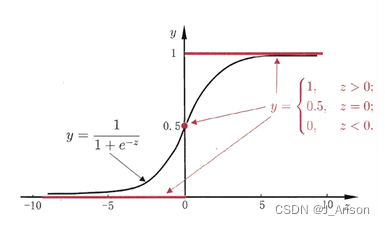
逻辑回归函数形式如下:
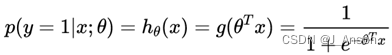
上式也叫逻辑回归预测函数,预测在x,θ确定的情况下,y=1的概率,其中:

若预测y=0的概率,则:
![]()
为了更加方便的表示每个样本的概率,将y=0与y=1进行整合,得到下式:
![]()
4.似然函数
统计学中,似然函数是一种关于统计模型参数的函数。给定输出x时,关于参数θ的似然函数L(θ|x)(在数值上)等于给定参数θ后变量X的概率:L(θ|x)=P(X=x|θ)。简单理解就是,通过给定一支的样本来反推模型参数。也就是寻找参数θ使得样本发生的概率尽可能大。所以对于离散型随机变量而言,假设x的分布率为P(x|θ),样本集D上有m个样本,则D上的似然函数为:

上式右边表示X1到Xm的概率的乘积,我们是寻找参数θ,让模型尽可能准确率高,也就是认为所有事件发生的概率尽可能大,所以就是求当似然函数取最大值时的因变量θ。也就是似然函数一般要构造成凸函数,可导才好求极大值。
5.对数似然函数
代价函数(Cost Function)是整个样本集的平均误差,对所有损失函数值的平均。在逻辑回归中,最常用的代价函数是交叉熵(Cross Entropy)函数,或者说是对数函数,他们本质是一样的。通过上文我们可以得到逻辑回归的似然函数为:
![]()
所以根据该似然函数理论上就能求出参数θ了。但是,乘积的式子很复杂,不便于求解。将似然函数转换为对数似然函数(以e为底)如下:

其中:
![]()
此时,采用数学的方法求极值,可求得最大值对应的参数θ。
6.对数似然损失函数与梯度求导
在机器学习中一般采用梯度下降法进行求解。上面式子求的是最大值,梯度下降求得是最小值,故添加一个负号,m个样本的平均损失函数转换为下面这个式子:

式子中有个m分之一,表示用了m个样本数据作为一组,表示求损失函数的平均值!式子中当真实值y=1,预测概率越接近1,损失值越小与经验一致。真实值y=0时,预测概率越接近0损失越小。下面是借鉴别人的求梯度式子推到。

最后的结果最后那个x变量中的i表示第i个样本,j表示第j个特征。括号内为预测减去真实值。
7.参数更新
利用梯度进行所要求的θ更新,如下式:

其中α为学习率。
8.召回率、精确率
精确率是针对我们预测结果而言的,它表示的是预测为正的样本中有多少是真正的正样本。那么预测为正就有两种可能了,一种就是把正类预测为正类(TP),另一种就是把负类预测为正类(FP),也就是:

召回率是针对我们原来的样本而言的,它表示的是样本中的正例有多少被预测正确了。那也有两种可能,一种是把原来的正类预测成正类(TP),另一种就是把原来的正类预测为负类(FN)。

9.阈值指定与置信区间
预测时,如果不指定概率阈值,则根据sigmoid判断当概率大于等于0.5,判断为y=1。实际根据需要指定不同的阈值,比如概率大于0.9时,才认为预测准确。关于概率阈值具体研究,本文暂不做介绍。置信区间展现的是这个参数的真实值有一定概率落在测量结果的周围的程度。置信水平表示区间估计的把握程度,置信区间的跨度是置信水平的正函数,即要求的把握程度越大,势必得到一个较宽的置信区间,这就相应降低了估计的准确程度。比如,为了更严谨,更有把握预测癌症,完全可以把概率阈值设置为0.98,但是满足这样的区间一般会小了很多,把握是大了,但是能诊断出是否患癌症晚期的病人少了。
10.说明
逻辑回归损失函数并没有采用均方差函数,当模型完全预估错误时(y=1, p=0; 或y=0, p=1),损失是1。预估正确时,损失是0。错误值离正确值的“距离”相对较小,区分度不大。另外,上面的损失函数相对θ并非是凸函数,而是有很多极小值(local minimum)的函数。因此,很多凸优化的算法(如梯度下降)无法收敛到全局最优点。
Logistic Regression 虽然被称为回归,但其实际上是分类模型,并常用于二分类。
Logistic 回归的本质是:假设数据服从这个分布,然后使用极大似然估计做参数的估计。
11.逻辑回归API介绍
sklearn.linear_model.LogisticRegression(solver-'liblinear', penalty='12', C=1.0)
solver可选参数:('liblinear', 'sag', 'saga','newton-cg', 'Ibfgs'),默认:'liblinear':用于优化问题的算法。
对于小数据集来说,“liblinear”是个不错的选择,而“sag”和'saga'对于大型数据集会更快。
对于多类问题,只有'newton-cg','sag','saga'和'lbfgs'可以处理多项损失;olinear”仅限于“one-versus-rest”分类。
penalty:正则化的种类
C:正则化力度
默认将类别数量少的当做正例
LogisticRegression方法相当于 SGDClassifier(loss="log",penalty="")、SGDClassifier实现了一个普通的随机梯度下降学习,而使用LogisticRegression(实现了SAG)。
12.逻辑回归API使用
使用【威斯康星州乳腺癌症数据集】,预测癌症分类,采用逻辑回归分析算法
数据集下载位置:UCI Machine Learning Repository
import joblib
import numpy as np
import pandas as pd
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
cols = ['Sample-code-number', 'Clump-Thickness', 'Uniformity-of-Cell-Size', 'Uniformity-of-Cell-Shape', 'Marginal-Adhesion', 'Single-Epithelial-Cell-Size', 'Bare-Nuclei', 'Bland-Chromatin', 'Normal-Nucleoli', 'Mitoses', 'Class']
bcw = pd.read_csv('./data/breast-cancer-wisconsin-original/breast-cancer-wisconsin.data', names=cols)
bcw = bcw.replace(to_replace='?', value=np.NaN)
bcw = bcw.dropna()
x = bcw.iloc[:, 1:10]
y = bcw['Class']
# 数据分割x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, random_state=10)
# 标准化transfer = StandardScaler()
x_train = transfer.fit_transform(x_train)
x_test = transfer.fit_transform(x_test)
# 逻辑回归estimator = LogisticRegression()
estimator.fit(x_train, y_train)
print("score:\n", estimator.score(x_test, y_test))
# 保存估计器
joblib.dump(value=estimator, filename='./data/breast-cancer-wisconsin-original/bcw.pkl')13.运行结果:














 3853
3853











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









