







1 布隆过滤器的基本原理
1.1 概述
布隆过滤器(Bloom Filter)是1970年由布隆提出的。它实际上是由一个很长的二进制向量(数组)和一系列随机映射函数(hash函数)组成,它不存放数据的明细内容,仅仅标识一个数据是否存在的信息。布隆过滤器可以用于检索一个元素在一个数组或集合中是否存在。
它的优点是空间效率和查询时间都比一般的算法要好,缺点是有一定的误判率(hash冲突导致的)和数据删除困难。
1.2 基本原理
布隆过滤器的基本原理如下所述:
- 数据存储到布隆过滤器:创建一个指定长度的数组,数组元素的初始值均为0。通过一个或多个Hash函数将数据映射成该数组中的一个点或者多个点,并将这些点位的元素值设置为非0。
- 判断某个数据在布隆过滤器中是否存在:通过hash函数计算某个数据在数组上对应的所有点是不是都非0。如果都非0,则该数据可能存在;如果有一个为0,则该数据一定不存在。
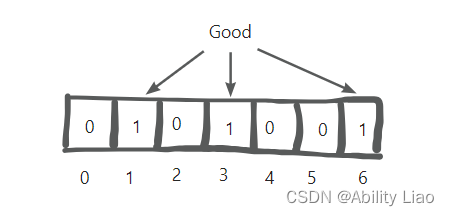
举例:当向过滤器存入 “Good” 时,假设过滤器的 3 个哈希函数输出 1、3、6,则把数组相应位置的元素置为 1。
1.3 误判率推导
1.3.1 误判率推导
首先,我们定义布隆过滤器的三个基本参数:
- 过滤器的 bit 数组长度为 m;
- 过滤器的 hash 函数的个数为 k;
- 过滤器中存入的数据量为 n。
接着进行推导:
- 在存入 1 个数据,并通过 hash 函数进行 1 次映射时,数组的某个 bit 位因为这次操作被置为1 的概率为
;
- 反之,这个 bit 位不会因为这次操作被置为 1 的概率为
;
- 进一步得到,这个 bit 位在经过 k 次 hash 映射后,仍然不被置为 1 的概率为
;
- 进一步得到,在存入 n 个数据后,这个 bit 位仍然不被置为 1 的概率为
;
- 反之,在存入 n 个元素后,这个 bit 位被置为 1 的概率为
;
发生误判的前提是:经过 k 次 hash 映射后,对应的 k 个 bit 位都在此前恰好被置为 1 了。
根据上述结论,我们可以得到误判发生的概率如下:
1.3.2 误判率计算简化
当 时,基于高等数学中等价无穷小的规则和洛必达法则,可以得出以下简化后的误判率公式:
其中
- p - 误判率;
- m - 过滤器的 bit 数组长度;
- k - 过滤器的 hash 函数的个数;
- n - 过滤器中存入的数据量。
由公式可知,当其他条件一定时,
(1)过滤器的 bit 数组长度(m)越大,误判率越低;
(2)hash 函数的个数(k)过大或过小时,误判率将变高;
(3)过滤器中存入的数据量(n)越大,误判率越高;
因此在实际使用时,过滤器的 bit 数组长度应尽可能设置大一点,并远大于过滤器中可能存入的数据量;同时hash 函数的个数不宜设置过大或过小(可根据下述公式进行测算)。
1.3.3 计算hash函数个数
当m和n一定时,计算误判率最低时的hash 函数个数(k值)。计算时,先对上述公式两边取对数,再对等式两边进行取导。因为随着k值的变大,误判率会先减低后升高,因此当误判率最低时,该点的导数值为0,依次将最终获取到k值。具体的计算步骤如下所示(注意复合函数的求导和求导的运算规则)。
假设
(1)先两边取对数
(2)再对等式两边进行取导
(3)误判率最低时,导数值 为0,因此
继而得
(4)最终得到k值,如下所示:
2 布隆过滤器的使用
下面是对布隆过滤器的简单使用。采用的过滤器是guava中对布隆过滤器的实现。
2.1 依赖
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>28.1-jre</version>
</dependency>2.2 源码解析
guava中实现的布隆过滤器的主要方法如下:
- 创建布隆过滤器:BloomFilter#create
- 往过滤器中插入数据: BloomFilter#put
- 判断数据在过滤器中是否存在:BloomFilter#mightContain
2.2.1 创建布隆过滤器
创建布隆过滤器:BloomFilter#create 源码如下所示。
public static <T> BloomFilter<T> create(
Funnel<? super T> funnel, long expectedInsertions, double fpp) {
return create(funnel, expectedInsertions, fpp, BloomFilterStrategies.MURMUR128_MITZ_64);
}
static <T> BloomFilter<T> create(
Funnel<? super T> funnel, long expectedInsertions, double fpp, Strategy strategy) {
// ...
if (expectedInsertions == 0) {
expectedInsertions = 1;
}
// 计算bit数组长度
long numBits = optimalNumOfBits(expectedInsertions, fpp);
// 计算hash函数个数
int numHashFunctions = optimalNumOfHashFunctions(expectedInsertions, numBits);
try {
// 创建布隆过滤器
return new BloomFilter<T>(new LockFreeBitArray(numBits), numHashFunctions, funnel, strategy);
} catch (IllegalArgumentException e) {
throw new IllegalArgumentException("Could not create BloomFilter of " + numBits + " bits", e);
}
}由计算bit数组长度函数可知,expectedInsertions(n) 和 fpp(p)越大,bit数组的size越大。源码如下所示。
static long optimalNumOfBits(long n, double p) {
if (p == 0) {
p = Double.MIN_VALUE;
}
return (long) (-n * Math.log(p) / (Math.log(2) * Math.log(2)));
}由计算bit数组长度函数和计算hash函数可知,hash函数的个数只与fpp(p)有关,fpp(p)越大,hash函数的个数越大。源码如下所示。
static int optimalNumOfHashFunctions(long n, long m) {
return Math.max(1, (int) Math.round((double) m / n * Math.log(2)));
}以下为创建bit数组的源码,通过源码可知,创建的是一个long类型的数组,元素初始值均为0。
LockFreeBitArray(long bits) {
checkArgument(bits > 0, "data length is zero!");
this.data =
new AtomicLongArray(Ints.checkedCast(LongMath.divide(bits, 64, RoundingMode.CEILING)));
this.bitCount = LongAddables.create();
}
public AtomicLongArray(int length) {
array = new long[length];
}2.2.2 往过滤器中插入数据
往过滤器中插入数据: BloomFilter#put 的源码如下所示。
public <T> boolean put(
T object, Funnel<? super T> funnel, int numHashFunctions, LockFreeBitArray bits) {
long bitSize = bits.bitSize();
byte[] bytes = Hashing.murmur3_128().hashObject(object, funnel).getBytesInternal();
long hash1 = lowerEight(bytes);
long hash2 = upperEight(bytes);
boolean bitsChanged = false;
long combinedHash = hash1;
for (int i = 0; i < numHashFunctions; i++) {
// Make the combined hash positive and indexable
bitsChanged |= bits.set((combinedHash & Long.MAX_VALUE) % bitSize);
combinedHash += hash2;
}
return bitsChanged;
}
// 向bit数组中设置值
boolean set(long bitIndex) {
if (get(bitIndex)) {
return false;
}
int longIndex = (int) (bitIndex >>> LONG_ADDRESSABLE_BITS);
long mask = 1L << bitIndex; // only cares about low 6 bits of bitIndex
long oldValue;
long newValue;
do {
oldValue = data.get(longIndex);
newValue = oldValue | mask;
if (oldValue == newValue) {
return false;
}
} while (!data.compareAndSet(longIndex, oldValue, newValue));
// We turned the bit on, so increment bitCount.
bitCount.increment();
return true;
}由源码可知,当向过滤器中插入数据时,实际上会往bit数组中与hash函数个数同等数量的位置设置非0值,以此表示该数据存在于过滤器中。
2.2.3 判断数据是否存在
判断数据在过滤器中是否存在:BloomFilter#mightContain 的源码如下所示。
public <T> boolean mightContain(
T object, Funnel<? super T> funnel, int numHashFunctions, LockFreeBitArray bits) {
long bitSize = bits.bitSize();
byte[] bytes = Hashing.murmur3_128().hashObject(object, funnel).getBytesInternal();
long hash1 = lowerEight(bytes);
long hash2 = upperEight(bytes);
long combinedHash = hash1;
for (int i = 0; i < numHashFunctions; i++) {
// Make the combined hash positive and indexable
if (!bits.get((combinedHash & Long.MAX_VALUE) % bitSize)) {
return false;
}
combinedHash += hash2;
}
return true;
}
// 判断数组对应位置的值是否非0
boolean get(long bitIndex) {
return (data.get((int) (bitIndex >>> LONG_ADDRESSABLE_BITS)) & (1L << bitIndex)) != 0;
}由源码可知,判断数据是否存在时,会判断某个数在数组中对应的所有点位是否都不为0。如果都不为0,则该数据(可能)已存在;否则该数据一定不存在。
2.3 使用示例
下面是布隆过滤器的简单应用。
import com.google.common.base.Charsets;
import com.google.common.collect.Lists;
import com.google.common.hash.BloomFilter;
import com.google.common.hash.Funnels;
import java.util.List;
public class BloomFilterDemo {
public static void main(String[] args) {
// 过滤器中存储数据
int total = 1000000;
List<String> baseList = Lists.newArrayList();
for (int i = 0; i < total; i++) {
baseList.add("" + i);
}
// 待匹配的数据
// 布隆过滤器应该匹配到的数据量:1000000
List<String> inputList = Lists.newArrayList();
for (int i = 0; i < total + 10000; i++) {
inputList.add("" + i);
}
// (1)条件:expectedInsertions:100w,fpp:3%
// 结果:numBits:约729w(数组size:约729w/64),numHashFunctions:5
System.out.println("expectedInsertions:100w,fpp:3%,匹配到的数量 " + bloomFilterCheck(baseList, inputList, baseList.size(), 0.03));
// (2)条件:expectedInsertions:100w,fpp:0.0001%
// 结果:numBits:约2875w(数组size:约2875w/64),numHashFunctions:20
System.out.println("expectedInsertions:100w,fpp:0.0001%,匹配到的数量 " + bloomFilterCheck(baseList, inputList, baseList.size(), 0.000001));
// (3)条件:expectedInsertions:1000w,fpp:3%
// 结果:numBits:约7298w(数组size:约7298w/64),numHashFunctions:5
System.out.println("expectedInsertions:1000w,fpp:3%,匹配到的数量 " + bloomFilterCheck(baseList, inputList, baseList.size() * 10, 0.03));
}
/**
* 布隆过滤器
*
* @param baseList 过滤器中存储的数据
* @param inputList 待匹配的数据
* @param expectedInsertions 可能插入到过滤器中的总数据量
* @param fpp 误判率
* @return 在布隆过滤器中可能存在数据量
*/
private static int bloomFilterCheck(List<String> baseList, List<String> inputList, int expectedInsertions, double fpp) {
// 创建布隆过滤器
BloomFilter<String> bf = BloomFilter.create(Funnels.stringFunnel(Charsets.UTF_8), expectedInsertions, fpp);
// 初始化数据到过滤器中
for (String string : baseList) {
// 在对应索引位置存储非0的hash值
bf.put(string);
}
// 判断值是否存在过滤器中
int count = 0;
for (String string : inputList) {
if (bf.mightContain(string)) {
count++;
}
}
return count;
}
}运行结果
expectedInsertions:100w,fpp:3%,匹配到的数量 1000309
expectedInsertions:100w,fpp:0.0001%,匹配到的数量 1000000
expectedInsertions:1000w,fpp:3%,匹配到的数量 1000000结论:
expectedInsertions 和 fpp 决定了布隆过滤器的大小(数组大小),fpp 决定了哈希函数的个数。而布隆过滤器的大小和哈希函数的个数共同决定了布隆过滤器的误判率。
因此使用此过滤器时,需要经过一定的测算,设置相对合理的expectedInsertions 和 fpp值,从而降低误判率。
3 参考文献
(1) 什么是布隆过滤器?如何使用?














 1233
1233











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









