









目录
1、布隆过滤器介绍
1.1 什么是布隆过滤器
布隆过滤器(Bloom Filter)是1970年由布隆提出的。它实际上是一个很长的二进制向量和一系列随机映射函数。布隆过滤器可以用于检索一个元素是否在一个集合中。
如果想要判断一个元素是不是在一个集合里,一般想到的是将所有元素保存起来,然后通过比较确定。链表,树等等数据结构都是这种思路. 但是随着集合中元素的增加,我们需要的存储空间越来越大,检索速度也越来越慢(O(n),O(logn))。不过世界上还有一种叫作散列表(又叫哈希表,Hash table)的数据结构。它可以通过一个Hash函数将一个元素映射成一个位阵列(Bit array)中的一个点。这样一来,我们只要看看这个点是不是1就可以知道集合中有没有它了。这就是布隆过滤器的基本思想。
Hash面临的问题就是冲突。假设Hash函数是良好的,如果我们的位阵列长度为m个点,那么如果我们想将冲突率降低到例如 1%, 这个散列表就只能容纳m / 100个元素。显然这就不叫空间效率了(Space-efficient)了。解决方法也简单,就是使用多个Hash,如果它们有一个说元素不在集合中,那肯定就不在;如果它们都说在,也有可能性是不存在的。
1.2 优缺点
优点:
时间复杂度低,存储空间和插入、查询时间都是常数
保密性强,不存储元素本身
散列函数相互之间没有关系,方便由硬件并行实现
可以表示全集,其它任何数据结构都不能
缺点:
有一定的误判率
删除困难
1.3 应用场景
解决大名鼎鼎的Redis缓存穿透问题
黑名单过滤(邮箱、URL、IP等)
减少不存在的行或列的磁盘查找
1.4 基本原理
首先初始化布隆过滤器的空间,也就是一个二进制数组,可根据预计插入数据量和误判率进行控制;布隆过滤器会根据这两个参数通过特定算法计算二进制数组的长度和要使用的哈希函数数量;误判率越小,数组长度越大,哈希函数越多,空间占用越大,计算耗时越长
添加元素时,通过k个哈希函数分别计算得到hash值,然后对数组长度进行取模得到数组下标的位置,最后将对应数组下标的位置的值置为1
查询元素时,通过k个哈希函数分别计算得到hash值,然后对数组长度进行取模得到数组下标的位置,判断下标位置的值是否都为1,如果全部为1则可能存在(误判),有一个0则肯定不存在
为什么会误判呢?其实很简单,哈希函数再怎么好,哈希冲突也是无法避免的,也就是说可能会存在多个元素计算的hash值是相同的,那么它们取模数组长度后的数组索引也是相同的,例如当张三和张叁的哈希值取模后的数组索引都为6,其实这里只有张三,但此时判断张叁是否存在就会出现误判的情况
删除困难也是此理,有哈希冲突的情况下删除是很痛苦的,误删很可能发生
2、Java内存中使用
布隆过滤器有很多实现和优化,本文使用由 Google 开发著名的 Guava 库就提供了布隆过滤器(Bloom Filter)的实现
2.1 引入依赖
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>29.0-jre</version>
</dependency>2.2 编写测试类
package com.example.learningexpansion.testBloomFilter;
import com.google.common.hash.BloomFilter;
import com.google.common.hash.Funnels;
public class BloomFilterTest {
// 预计插入数据量
private static Integer expectedInsertions = 100_0000;
// 误判率
private static Double fpp = 0.01;
public static void main(String[] args) {
BloomFilter<Integer> bloomFilter = BloomFilter.create(Funnels.integerFunnel(), expectedInsertions, fpp);
for (Integer i = 0; i < expectedInsertions; i++) {
bloomFilter.put(i);
}
int count = 0;
for (int i = expectedInsertions; i < expectedInsertions*2; i++) {
// 返回TRUE代表可能存在
if (bloomFilter.mightContain(i)){
count++;
}
}
System.out.println("误判个数:"+count);
Double result = Double.valueOf(count) / Double.valueOf(expectedInsertions);
System.out.println("误判率:"+result);
}
}2.3 测试效果

再把误判率调整至0.02看下

可以看出误判率跟设置的值很接近,我们可根据不同的业务场景设置不同的参数
2.4 预期插入数量和误判率的关系
把预期插入数量固定为1_000_000,误判率分别为0.01、0.02、0.03,看下位数组大小和哈希函数的个数
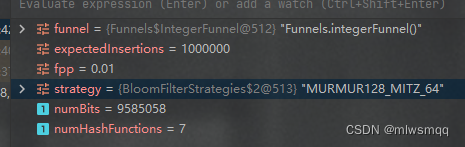
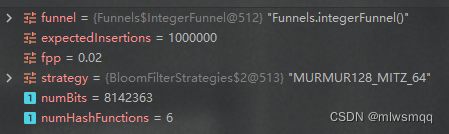
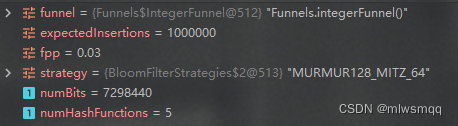
可看出当预期插入数量不变时,误判率越大,位数组越小,哈希函数越少
把误判率固定为0.01,预期插入数量分别为1_000_000,5_000_000,10_000_000,看下位数组大小和哈希函数的个数
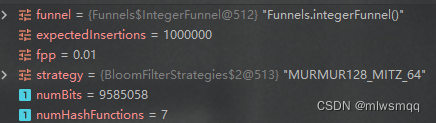
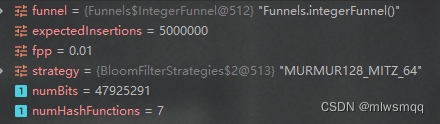
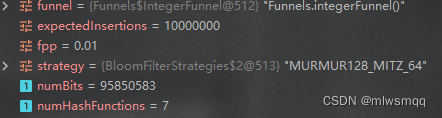
可看出当误判率不变时,预期插入数量越大,位数组越大,但哈希函数数量不变
注意:此结论只适用于Guava库中的布隆过滤器
3、集成Redis使用布隆过滤器
3.1 引入依赖
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson-spring-boot-starter</artifactId>
<version>3.16.0</version>
</dependency>3.2 所需常量类
public class BloomFilterConstant {
public static final String NAME_SECKILL = "seckillBloomFilter";
public static final Long EXPECTED_INSERTIONS_SECKILL = 100_0000L;
public static final Double FALSE_POSITIVERATE_SECKILL = 0.01;
}public class CacheKeyConstant {
// 缓存商品库存KEY
public static final String CACHE_KEY_REVERSE_BY_GOODS_ID = "reserve:{}";
// 缓存消费成功消息KEY
public static final String CACHE_KEY_CONSUME_SUCCESS_MESSAGE_ID = "consumeSuccess:messageId:{}";
// 缓存关闭订单消息消费成功KEY
public static final String CACHE_KEY_CONSUME_SUCCESS_CLOSE_ORDERS = "consumeSuccess:closeOrders:{}";
// 缓存商品价格KEY
public static final String CACHE_KEY_GOODS_PRICE = "price:{}";
}3.3 配置RedissonConfig
创建一个名为seckillBloomFilter的布隆过滤器
package com.seckill.common.conf;
import com.seckill.common.constants.BloomFilterConstant;
import org.redisson.Redisson;
import org.redisson.api.RBloomFilter;
import org.redisson.api.RedissonClient;
import org.redisson.config.Config;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.cache.annotation.EnableCaching;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
/**
* @Auther:admin
* @Date:2022/10/9 18:02
*/
@EnableCaching
@Configuration
public class RedissonConf {
@Value("${spring.redis.host}")
private String host;
@Value("${spring.redis.port}")
private String port;
@Value("${spring.redis.password}")
private String password;
@Bean(destroyMethod = "shutdown")
public RedissonClient redissonClient(){
/**
* 连接哨兵:config.useSentinelServers().setMasterName("myMaster").addSentinelAddress()
* 连接集群:config.useClusterServers().addNodeAddress()
* 连接主从:config.useMasterSlaveServers().setMasterAddress("xxx").addSlaveAddress("xxx")
*/
// 连接单机
Config config = new Config();
config.useSingleServer()
.setAddress("redis://"+host+":"+port)
.setPassword(password);
RedissonClient client = Redisson.create(config);
return client;
}
@Bean(BloomFilterConstant.NAME_SECKILL)
public RBloomFilter<Object> seckillBloomFilter(){
RBloomFilter<Object> bloomFilter = redissonClient().getBloomFilter(BloomFilterConstant.NAME_SECKILL);
bloomFilter.tryInit(BloomFilterConstant.EXPECTED_INSERTIONS_SECKILL, BloomFilterConstant.FALSE_POSITIVERATE_SECKILL);
return bloomFilter;
}
}3.4 布隆过滤器加载初始化数据
利用@PostConstruct注解在项目启动时把要用到的数据添加到布隆过滤器中
@Service
@Slf4j
public class GoodsServiceImpl extends ServiceImpl<GoodsDao, Goods> implements GoodsService{
private static final Snowflake snowflake = IdUtil.getSnowflake(1,1);
@Resource
private GoodsDao goodsDao;
@Resource
private StockService stockService;
@Resource
private RedisTemplate<String, String> redisTemplate;
// 注入指定的布隆过滤器
@Resource
@Qualifier(BloomFilterConstant.NAME_SECKILL)
private RBloomFilter<Object> bloomFilter;
// 初始化布隆过滤器
@PostConstruct
public void initBloomFilter(){
// 把所有的商品信息放进布隆过滤器中
List<Long> ids = getAllGoodsIds();
ids.parallelStream().forEach(item->{
// 商品库存
bloomFilter.add(ConvertCacheKeyUtil.getFormatString(CacheKeyConstant.CACHE_KEY_REVERSE_BY_GOODS_ID,item));
// 商品价格
bloomFilter.add(ConvertCacheKeyUtil.getFormatString(CacheKeyConstant.CACHE_KEY_GOODS_PRICE, item));
});
log.info("***********秒杀布隆过滤器初始化数据成功 当前数量:{} ***********",bloomFilter.count());
}
/*/**
* @description: 获取所有商品ID
[]
* @author:hmz
* @date:2022/10/10 16:04
* @return:java.util.List<java.lang.Long>
*/
@Override
public List<Long> getAllGoodsIds() {
return list().parallelStream().map(Goods::getId).collect(Collectors.toList());
}
}格式化key使用的工具类
import org.slf4j.helpers.FormattingTuple;
import org.slf4j.helpers.MessageFormatter;
public class ConvertCacheKeyUtil {
public static String getFormatString(String message, Object... param) {
FormattingTuple formattingTuple = MessageFormatter.arrayFormat(message, param);
String key = formattingTuple.getMessage();
return key;
}
}
3.5 查询商品库存时防止缓存穿透
先从布隆过滤器中查询,没有直接返回,有再去缓存中查询,在一定程度上可防止缓存穿透
@Service
public class StockServiceImpl extends ServiceImpl<StockDao, Stock> implements StockService {
private static final Snowflake snowflake = IdUtil.getSnowflake(1,1);
@Resource
private StockDao stockDao;
@Resource
private RedisTemplate<String, String> redisTemplate;
@Resource
@Qualifier(BloomFilterConstant.NAME_SECKILL)
private RBloomFilter<Object> bloomFilter;
/*/**
* @description: 根据商品ID查询库存
[goodsId]
* @author:hmz
* @date:2022/9/18 6:55
* @return:java.lang.Long
*/
@Override
public Long getReserveByGoodsId(Long goodsId) {
String key = ConvertCacheKeyUtil.getFormatString(CacheKeyConstant.CACHE_KEY_REVERSE_BY_GOODS_ID,goodsId);
// 判断布隆过滤器中是否存在
boolean contains = bloomFilter.contains(key);
if (!contains){
log.warn("布隆过滤器查询商品库存不存在,商品ID:{}",goodsId);
return null;
}
// 再从缓存获取
String cache = redisTemplate.opsForValue().get(key);
if (StringUtils.isNotBlank(cache)){
return Long.valueOf(cache);
}
// 缓存没有从库里面查询
LambdaQueryWrapper<Stock> wrapper = new LambdaQueryWrapper<Stock>()
.eq(Stock::getGoodsId,goodsId);
Stock stock = getOne(wrapper);
if (Objects.isNull(stock)){
return null;
}
if (Objects.nonNull(stock.getReserve())){
redisTemplate.opsForValue().set(key,stock.getReserve().toString(),10, TimeUnit.MINUTES);
}
return stock.getReserve();
}
}本文中的例子是我个人练习时所写,有不合理的地方欢迎大家指正
希望对大家有所帮助,转载请注明出处!















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









