






 本文详细介绍了Java中的volatile关键字,包括其如何确保多线程环境中变量的可见性,如何防止JVM指令重排序,以及何时应该使用volatile。同时,文章还探讨了volatile在性能上的考量。
本文详细介绍了Java中的volatile关键字,包括其如何确保多线程环境中变量的可见性,如何防止JVM指令重排序,以及何时应该使用volatile。同时,文章还探讨了volatile在性能上的考量。
原文链接:http://tutorials.jenkov.com/java-concurrency/volatile.html
摘要:这是翻译自一个大概30个小节的关于Java并发编程的入门级教程,原作者Jakob Jenkov,译者Zhenning Lang,转载请注明出处,thanks and have a good time here~~~(希望自己不要留坑)
Java“volatile ”关键字用来将一个 Java 变量标记为“储存在主内存中”(being stored in main memory)。更准确的说,每次读取一个 volatile 变量都是直接从系统的主内存(computer’s main memory)中读取,而并不是从 CPU 的缓存中读取;每次写入一个 volatile 变量都将被直接写入系统主内存,而不是写入 CPU 的缓存中。
实际上,自从 Java 5 开始,volatile 关键字所做的比以上说的内容更多(从主内存中读写),下面将详细介绍这些内容。
1. Java volatile 关键字对于可见性的保证
Java volatile 关键字保证了变量的变化对于不同线程的可见性。这可能听起来有一些抽象,下面将详细的介绍这些内容。
如果在一个多线程的应用程序中,多个线程操作非易变(non-volatile)的变量,那么每个线程在操作变量的过程中,出于性能考虑可能将变量从系统的主内存中拷贝进 CPU 的缓存中。如果你的电脑有多个 CPU,那么每个线程可能会运行在不同的 CPU 上,如下图所示:
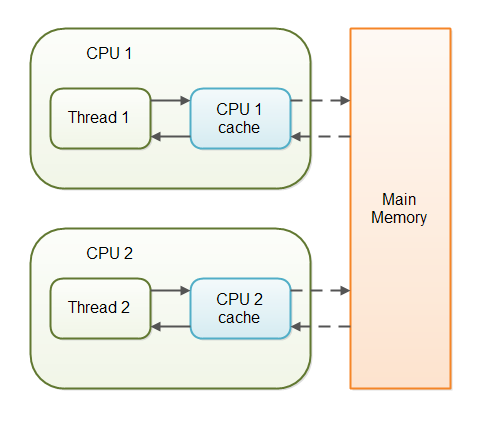
对于 non-volatile 变量来说,Java 虚拟机(JVM)具体何时将数据从主内存读入 CPU 的缓存,或者从 CPU 的缓存写回主内存中,都是不得而知的,这可能导致如下的问题。
假设两个(或多个)线程都可以访问一个共享的对象,这个对象包含了一个计数器 counter:
public class SharedObject {
public int counter = 0;
}
本例中假设只有线程 1 在不断增加 counter 的数值,但是线程 1 和 2 都一直读取 counter 的值。
如果 counter 的声明没有被 volatile 关键字修饰,那么就无法保证 counter 的值何时从缓存写入主内存中,这意味着,在 CPU 缓存和主内存中的 counter 的取值可能不同,如下图所示:
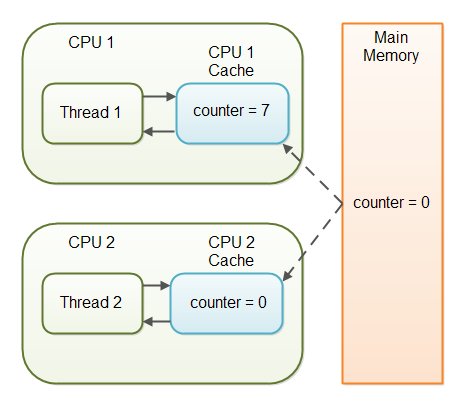
对于这种由于变量没有及时从缓存写入内存,而导致的线程无法跟踪变量的变化的问题叫做“可见性问题”,即一个线程对于变量的更新对于其他线程是不可见的。
通过在 counter 的声明中指定 volatile 关键字,所有对于 counter 的写操作都会强制使其立即存入主内存。同时,所有对于 counter 的读操作都是直接从主内存中读取(跨过缓存)。volatile 关键字的使用方式如下:
public class SharedObject {
public volatile int counter = 0;
}
所以 volatile 关键字保证了一个变量在不同线程间的可见性。
2. Java volatile 关键字的其他保证
从 Java 5 开始 volatile 关键字除了保证变量的读写都直接与主内存打交道外,还存在着如下的其他保障:
如果线程 A 对一个 volatile 变量进行了写入操作,紧接着线程 B 读取这个变量的值,那么线程 A 中在写 volatile 变量之前的所有对于线程 A 可见的变量,都对于线程 B 也是可见的。
对于 volatile 变量的读写指令,都无法被 JVM 进行重新排序(如果 JVM 判断改变指令的顺序可以提高性能同时对代码结果不产生影响,那么 JVM 会对指令进行重新排序)。虽然 volatile 变量的读写指令前后的代码可能会被调整顺序,但是对于 volatile 变量的读写指令并不会与其他的代码被调整的混杂在一起。volatile 变量读写指令之后的代码,将必然在这些读写操作完成之后再被执行。
对于以上两个陈述需要一个更深的解读。
当一个线程写 volatile 变量的值时,不仅仅是该 volatile 变量本身被写入主内存,在这个写操作之前所有被这个线程修改过值的变量都将被强制地从缓存写入主内存中。当一个线程读取 volatile 变量的值时,所有被一同写入主内存的变量值都会被取出。
请看这个例子:
Thread A:
sharedObject.nonVolatile = 123;
sharedObject.counter = sharedObject.counter + 1;
Thread B:
int counter = sharedObject.counter;
int nonVolatile = sharedObject.nonVolatile;
由于线程 A 在写 volatile 变量 sharedObject.counter 之前写入了一个 non-volatile 的变量 sharedObject.nonVolatile,那么在线程 A 对 sharedObject.counter 发生写操作的时候,这两个变量将一并被写入主内存。
由于线程 B 先读取了 volatile 变量 sharedObject.counter,那么变量 sharedObject.counter 和 sharedObject.nonVolatile 将一并被主内存中读入线程 B 所使用的 CPU 的缓存。也就是说,当线程 B 读取 non-volatile 的变量 sharedObject.nonVolatile 时,其值是线程 A 修改过后的值。
程序员可以利用这个扩展的对于可见性的保证来优化线程间的变量可见性。与其将每个变量都声明为 volatile,实际上只有一个或很少的变量需要 volatile 的修饰。下面的例子利用了这种特性:
public class Exchanger {
private Object object = null;
private volatile boolean hasNewObject = false;
public void put(Object newObject) {
while(hasNewObject) {
//wait - do not overwrite existing new object
}
object = newObject;
hasNewObject = true; //volatile write
}
public Object take(){
while(!hasNewObject){ //volatile read
//wait - don't take old object (or null)
}
Object obj = object;
hasNewObject = false; //volatile write
return obj;
}
}
在上例中,线程 A 可能一直通过调用 put() 方法来添加新的对象,而线程 B 一直通过调用 take() 方法来读取 A 所添加的对象。利用 volatile 关键字机制,上面的代码就可以良好运行(而不需要 synchronized ),这是因为线程 A 只是写人,而线程 B 只是读取。
然而,JVM 可能会通过在不影响程序语义的情况下,将 Java 的指令进行重新排序来优化程序的性能,如果 JVM 修改了 put() 和 take() 方法中的指令顺序会发生什么?加入 put() 实际的(修改了指令顺序后的)执行顺序如下:
while(hasNewObject) {
//wait - do not overwrite existing new object
}
hasNewObject = true; //volatile write
object = newObject;
注意到上面的代码中 volatile 变量 hasNewObject 在 object 真正被赋值之前运行。对于 JVM 来说,好像一切都是合法的,因为这两个赋值语句相互独立(可以随意调换顺序)。然而,这种操作将影响变量 object 的可见性。首先,线程 B 可能会观察到 hasNewObject 被设为 true,然而线程 A 还没有真正的给变量 object 赋一个新的值;其次,这种改变使得将变量 object 的修改压入主内存的时间变得不可预期。
所以为了组织上述情况的发生,volatile 关键字保证了对于 volatile 变量的读写操作指令是无法被 JVM 重新排序的。虽然“之前”和“之后”的代码都可能被单独的调整,但 volatile 变量的读写是不会被调整的(译者理解:即以 volatile 变量的读写作为一个分割)。例如:
sharedObject.nonVolatile1 = 123;
sharedObject.nonVolatile2 = 456;
sharedObject.nonVolatile3 = 789;
sharedObject.volatile = true; //a volatile variable
int someValue1 = sharedObject.nonVolatile4;
int someValue2 = sharedObject.nonVolatile5;
int someValue3 = sharedObject.nonVolatile6;
JVM 可能会调整前三条指令的顺序(同时从写这段程序的意图上来说这三条指令希望被保证在第四条语句前执行),也可能会调整后三条指令的顺序,但是绝不会将后面三条指令调整到第四条指令前面,也不会将前三条指令调整到第四条指令后面。
3. volatile 关键字并不总是够用的
即便 volatile 关键字保证了对于 volatile 变量的读写都是直接与主内存打交道的,但仍然存在其解决不了的问题。
在第一个 counter 的例子中只有线程 1 不断的写 counter 值,此时 volatile 关键字足以保证线程 2 时刻获取 counter 的最新值。
实际上,即便多个线程仍然可以同时写共享的 volatile 变量,并保证主内存中的变量值是正确的,但其前提是新计算并写入的变量值不依赖于其历史值。换言之,就是说只要一个线程在写入一个 volatile 变量之前不需要先读取它再计算出新的数值,就不会出现问题。
但是只要这个条件不满足,即变量“未来值”的变化依赖于“历史值”,volatile 关键字就无法保证正确的线程间可见性了。读写之间的微小的时间间隙可能会带来竞争 —— 不同线程读取 volatile 变量的值,生成自己的新值,再写回主内存,这些被写回的值就将相互覆盖。
不同线程同时递增一个计数器就是一个无法使用 volatile 关键字的很好的例子。假设线程 1 读取了共享的值为 0 的 counter 变量,并将其加 1,此时 1 还储存在缓存中并没有写回主内存;就在这个间隙,线程 2 页读取了主内存中 counter 的值,即还是 0,并进行加 1 操作;当线程 1 和 2 将计算结果都存入主内存时,counter 此时的值是 1 而非我们想要的 2,如下图所示:
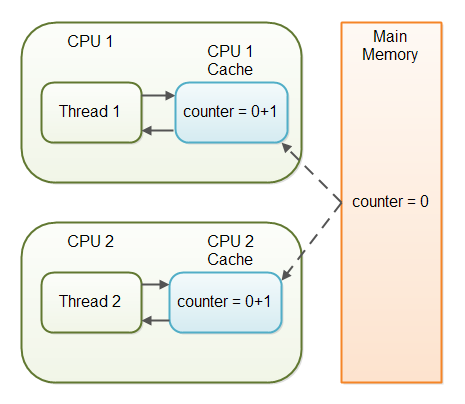
也就是说,这种情况下利用 volatile 关键字,但没能达成线程间同步的目的。
4. volatile 关键字所适用的情况
正如前文所说,如果两个线程同时读写共享变量,使用 volatile 关键字并非总是够用的。由于 volatile 无法锁定读写语句本身,所以需要 synchronized 关键字来保证对于变量读写的原子性。
作为 synchronized 代码段机制的替代,也可以使用 java.util.concurrent 包所提供的的一系列原子数据类型。例如 AtomicLong、AtomicReference 等。
那么 volatile 何时适用呢?
- 第一种情况是假设只有一个线程读写 volatile 变量的值(无论写入的值是否依赖于历史值),而其他的线程只是读取,那么 volatile 机制保证了读线程总是能获取变量的实时值。此时如果不用 volatile 关键字,这是无法被保障的。
- 第二种情况是虽然有多个线程在读写 volatile 变量,但读与写是分离的,即读取 volatile 变量的目的不是为了生成新的值再写入(可能是为了显示或其他目的),而写入的新值又不直接或间接的依赖于历史值。
(译者理解:虽然以上的两种情况好像不用 volatile 关键字程序也可以正常运行,但 volatile 保证了更好的实时性)
其他:volatile 关键字对 32 位和 64 位变量适用。
5. volatile 关键字的性能问题
由于 volatile 变量的读写都要直达主内存,而读写主内存要比读写 CPU 的缓存更加的费时。此外,使用 volatile 关键字也组织了 JVM 通过调整指令顺序的性能优化。因此,只有当你真的需要使用 volatile 关键字来保证变量的可见性时时再去用它。

















 1042
1042

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









