









一次MR作业Task数过多导致的集群阻塞的问题排查
问题背景
集群出现一百多个任务排队,运行中的任务一百多个,bi的同事反馈大量任务延迟一万多秒
以下截图不全

排查问题
- 通过RM页面、spacex的监控、active的RM机器的负载和日志观察,确认ResourceManager目前状态正常
- 通过spacex的app监控发现集群在早上8.45的时候提交大量的任务
- 阻塞的任务基本都跑在root.bi_queue.bi_base 这个队列中,这个队列资源基本满了
大概排查方向确认
- 增加了大量任务导致集群资源不足而阻塞
- 大量任务跑在同个队列中
解决
-
停掉部分长时间运行的任务
-
确认运行中的占用大量资源的任务是否有问题
-
发现
insert overwrite table bi_ucar.ba_kan...o.dt(Stage-2)这个任务耗费资源接近集群一半的资源同事反馈这个任务平时执行都是两三百秒,今天跑了一个多小时没完
查看MR的监控发现触发了大量的MR任务,且
Killed占近一半
-
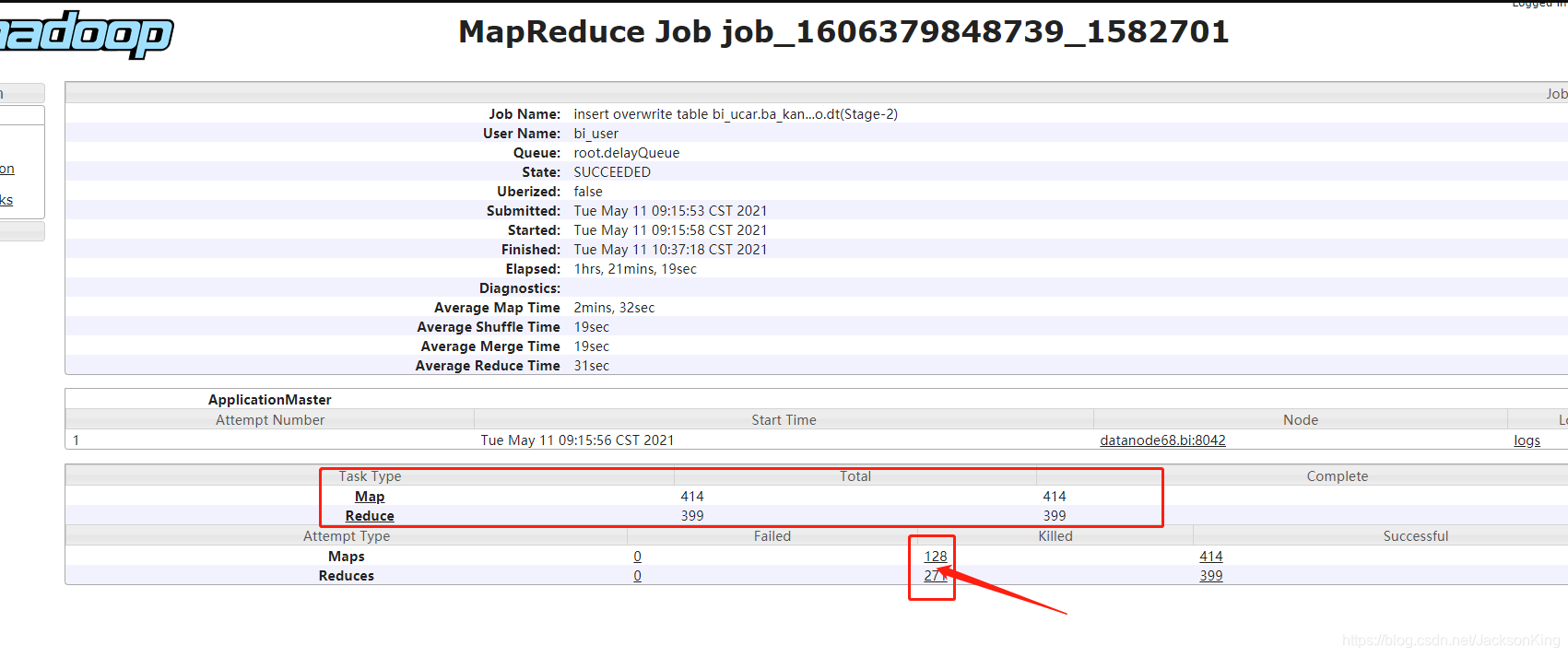
本来想将该作业杀死的,后面发现这个作业已经执行成功了,之后集群陆续恢复正常
分析为什么大量的KILLED的Task的任务会导致集群阻塞?
分析KILLED attempts
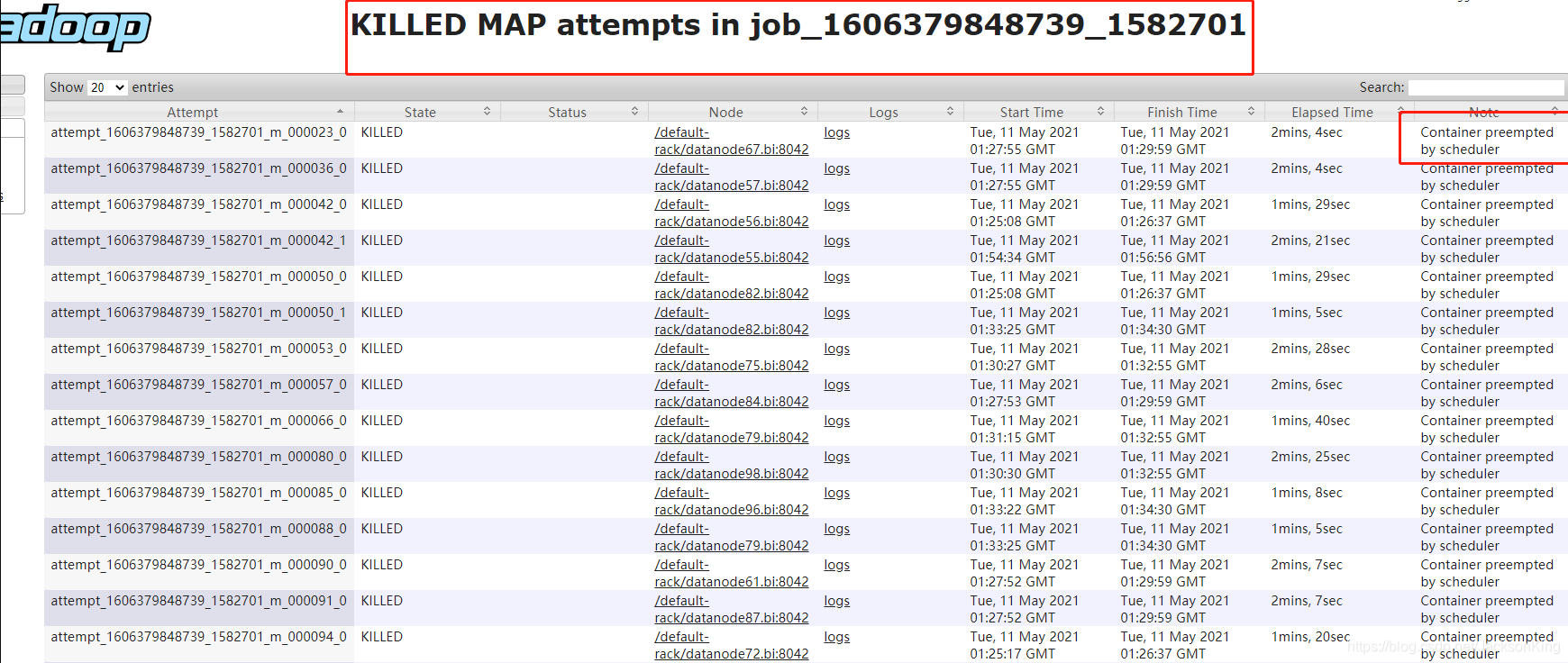
分析KILLED的Map Tasks
查看这个任务KILLED的Map Tasks和ReduceTasks
发现KILLED Map attempts大部分是由于Container preempted by scheduler,这个应该是高优先级队列的作业抢占低优先级队列的作业的资源导致的
分析KILLED的ReduceTasks
查看KILLED REDUCE attempts,发现大量的task的备注是“Reducer preempted to make room for pending map attempts",
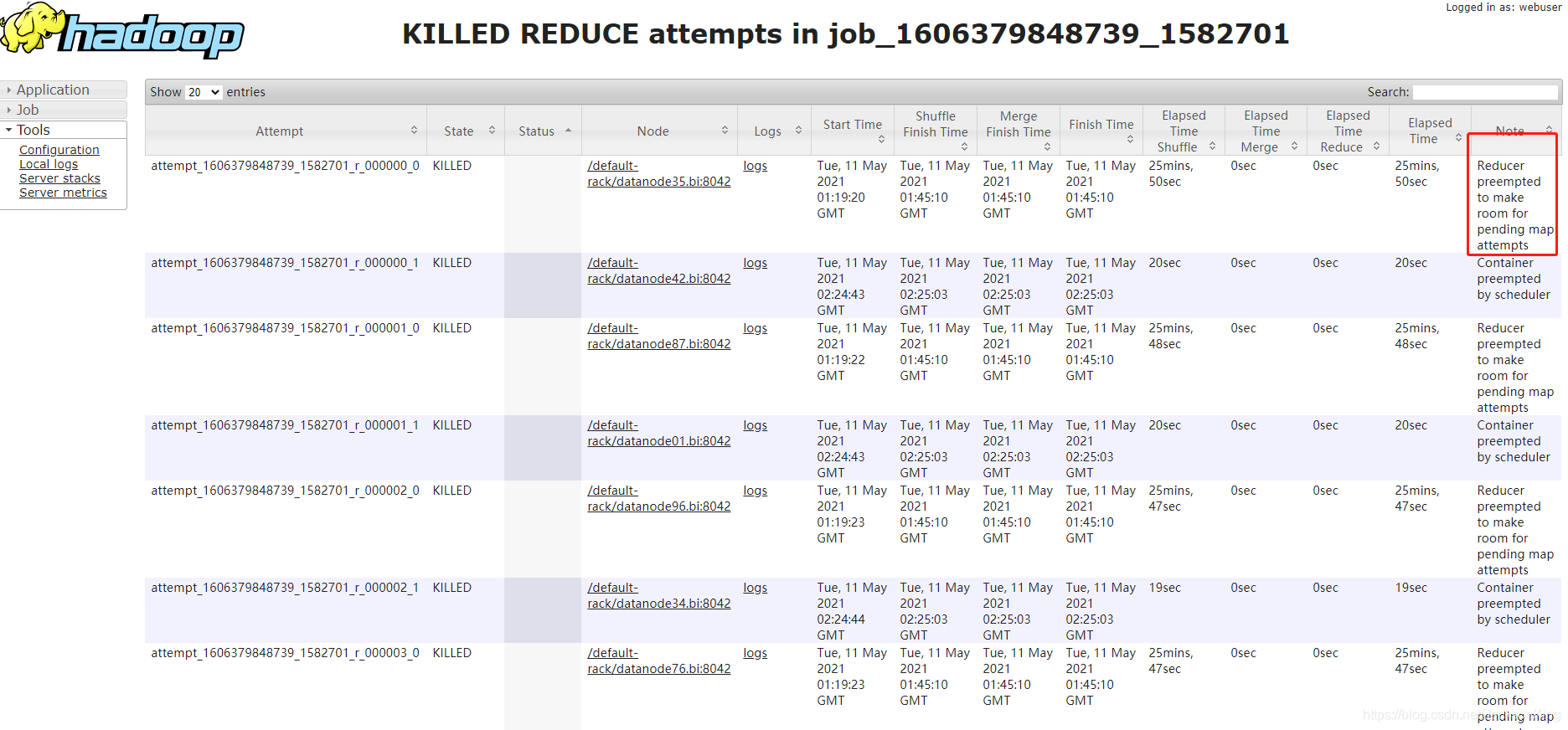
网上查了下,主要是:没跑完的map全在等待资源,而reduce在copy阶段已占用大量资源,由于map一直在等空闲资源,而reduce一直等未完成的map执行完,形成了一个死锁。AppMaster将reduce kill并释放资源。
- 从实际监控来看,出现问题时,没跑完的map全在等待资源,而reduce在copy阶段已占用大量资源,由于map一直在等空闲资源,而reduce一直等未完成的map执行完,形成了一个死锁。AppMaster将reduce kill并释放资源。出现这种情况时,Job运行时间会增加几小时。甚至一直持续无法释放资源。这块需要了解下RMContainerAllocatorRMContainerAllocator原理分析
- ContainerAllocator通过与RM通信,为Job申请资源,同时其维护一个心跳信息,获取新分配的资源和各Container运行情况。
- 在注释中可以看到,map生命周期为
scheduled->assigned->completed,reduce生命周期为pending->scheduled->assigned->completed。只要收到map的请求后,map的状态即变为scheduled状态,reduce根据map完成数和集群资源情况在pending和scheduled状态中变动。Vocabulary Used:
pending -> requests which are NOT yet sent to RM
scheduled -> requests which are sent to RM but not yet assigned
assigned -> requests which are assigned to a container
completed -> request corresponding to which container has completed - ContainerAllocator将所有任务分成三类:
- Failed Map。Priority为5。
- Reduce。Priority为10。
- Map。Priority为20。 Priority越低,该任务优先级越高。即这三种任务同时请求资源时,资源优先分配给Failed Map,其次是Reduce,最后才是Map。
- 源码分析:解决办法
少部分map由于reduce占用过多资源,无法执行,Container中kill相关reduce,腾出资源让map继续执行。这里有个疑问,从源码和配置文件中,如果map出现资源不足的情况,reduce应该会立即释放资源,但为何map等待时间这么久?从log可以看到,container申请资源时间相当长,考虑到使用的是FairScheduler对于此问题,比较好的方案就是尽量错 开大Job的执行时间,另外可适当调大COMPLETED_MAPS_FOR_REDUCE_SLOWSTART值,尽量让map多完成,但这样可能造成job运行时间变长。我找到集群中该参数发现已经设置过;哎!所以看来是需要设置为1了。(主要还是同时段启动的任务太多导致的)

所以最好就是调整参数:mapreduce.job.reduce.slowstart.completedmaps
原文:https://zhuanlan.zhihu.com/p/98688063
总结
大量KILLED的task由于死锁而阻塞
分析下来,也就解释得通了,如果Map的Task资源不足会从ReduceTask抢占资源(因为任务优先级Failed Map(5)<Reduce(10)<Map(20)。但是ReduceTask不是一定要等待全部的MapTask完成他才开始工作,当满足mapreduce.job.reduce.slowstart.completedmaps百分比的task完成后,Reduce的Task就会开始执行,这样Reduce任务就占用了一定的资源,导致MapTask获取不到足够的资源来完成所有的MapTask,Reduce Task又由于在等待MapTask执行完成以读取数据,这样两种任务相互等待而死锁,之后AppMaster将reduce kill并释放资源。出现这种情况时,Job运行时间会增加几小时。甚至一直持续无法释放资源。就是当前我们集群的状态。
后续可以尝试的方法
- 增加
mapreduce.job.reduce.slowstart.completedmaps参数,默认为0.05,即map完成0.05后reduce就开始copy,如果集群资源不够,有可能导致reduce把资源全抢光,可以把这个参数调整到0.8,map完成80%后才开始reduce copy。 - 错开任务执行时间,避免同时大量任务提交















 1011
1011











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









