







美图欣赏:

一.背景
RDD支持两种操作:转化操作和行动操作。RDD 的转化操作是返回一个新的 RDD的操作,比如 map()和 filter(),而行动操作则是向驱动器程序返回结果或把结果写入外部系统的操作。比如 count() 和 first()。
Spark采用惰性计算模式,RDD只有第一次在一个行动操作中用到时,才会真正计算。Spark可以优化整个计算过程。默认情况下,Spark 的 RDD 会在你每次对它们进行行动操作时重新计算。如果想在多个行动操作中重用同一个 RDD,可以使用 RDD.persist() 让 Spark 把这个 RDD 缓存下来。
二.创建RDD的二种方式
1.从集合中创建RDD
val conf = new SparkConf().setAppName("Test").setMaster("local")
val sc = new SparkContext(conf)
//这两个方法都有第二参数是一个默认值2 分片数量(partition的数量)
//scala集合通过makeRDD创建RDD,底层实现也是parallelize
val rdd1 = sc.makeRDD(Array(1,2,3,4,5,6))
//scala集合通过parallelize创建RDD
val rdd2 = sc.parallelize(Array(1,2,3,4,5,6))
2.从外部存储创建RDD
//从外部存储创建RDD
val rdd3 = sc.textFile("hdfs://bigdata111:9000/Jackson.txt")
三.算子案例
1.scala集合通过parallelize创建RDD
scala> val rdd = sc.parallelize(List(1,4,3,2,6,7,4,9))
rdd: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[0] at parallelize at <console>:24
2.sortBy算子
进行排序
scala> rdd.map(_*2).sortBy(x => x)
[Stage 0:> (0 +res2: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[6] at sortBy at <console>:27
3.collect算子
在驱动程序中,以数组的形式返回数据集的所有元素返回一个新的RDD,该RDD由每一个输入元素经过func函数转换后组成
scala> rdd.map(_*2).sortBy(x => x).collect
res3: Array[Int] = Array(2, 4, 6, 8, 8, 12, 14, 18)
4.map算子
返回一个新的RDD,该RDD由每一个输入元素经过func函数转换后组成
scala> rdd.map(_*2)
res4: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[13] at map at <console>:27
5.filter算子
返回一个新的RDD,该RDD由经过func函数计算后返回值为true的输入元素组成
scala> res4.filter(_>10)
res5: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[14] at filter at <console>:29
scala> res5.collect
res6: Array[Int] = Array(12, 14, 18)
6.flatMap算子
类似于map,但是每一个输入元素可以被映射为0或多个输出元素(所以func应该返回一个序列,而不是单一元素)
初级切分
scala> val rdd4 = sc.parallelize(Array("a b c","d f g"))
rdd4: org.apache.spark.rdd.RDD[String] = ParallelCollectionRDD[17] at parallelize at <console>:24
scala> rdd4.flatMap(_.split(" ")).collect
res8: Array[String] = Array(a, b, c, d, f, g)
高级切分
scala> val rdd5 =sc.parallelize(List(List("a b", "b c"),List("e c", "i o")))
rdd5: org.apache.spark.rdd.RDD[List[String]] = ParallelCollectionRDD[23] at parallelize at <console>:24
//第一个_ 代表 拿到多个List("a b", "b c")
//第二个_代表,拿到"a b" 多次循环完
scala> rdd5.flatMap(_.flatMap(_.split(" "))).collect
res11: Array[String] = Array(a, b, b, c, e, c, i, o)
7.to方法
//1 to 18
scala> val rdd6 = sc.parallelize(1 to 18)
rdd6: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[25] at parallelize at <console>:24
scala> rdd6.collect
res12: Array[Int] = Array(1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18)
7.sample算子
sample(withReplacement, fraction, seed)
withReplacement表示是抽出的数据是否放回,true为有放回的抽样,false为无放回的抽样
fraction抽样比例例如30% 即0.3 但是这个值是一个浮动的值不准确
seed用于指定随机数生成器种子 默认参数不传
scala> rdd6.sample(false,0.5).collect
res14: Array[Int] = Array(1, 2, 5, 7, 9, 10, 11, 12, 13, 14, 15, 18)
scala> rdd6.sample(false,0.5).collect
res15: Array[Int] = Array(2, 3, 6, 8, 10, 12, 13, 16, 17)
scala> rdd6.sample(false,0.5).collect
res16: Array[Int] = Array(1, 4, 6, 7, 8, 9, 10, 12, 14, 15, 17, 18)
scala> rdd6.sample(false,0.5).collect
res17: Array[Int] = Array(2, 3, 4, 6, 7, 8, 9, 10, 13, 17)
scala> rdd6.sample(false,0.5).collect
res18: Array[Int] = Array(1, 4, 5, 6, 7, 8, 9, 10, 12, 13, 14, 16, 17, 18)
8.cartesian 算子
笛卡尔积
scala> val rdd11_1 = sc.parallelize(List(("tom",1),("jerry" ,3),("kitty",2)))
rdd11_1: org.apache.spark.rdd.RDD[(String, Int)] = ParallelCollectionRDD[49] at parallelize at <console>:24
scala> val rdd11_2 = sc.parallelize(List(("jerry" ,2),("tom",2),("dog",10)))
rdd11_2: org.apache.spark.rdd.RDD[(String, Int)] = ParallelCollectionRDD[50] at parallelize at <console>:24
scala> val rdd11_3 = rdd11_1 cartesian rdd11_2
rdd11_3: org.apache.spark.rdd.RDD[((String, Int), (String, Int))] = CartesianRDD[51] at cartesian at <console>:28
scala> println(rdd11_3.collect.toBuffer)
ArrayBuffer
(((tom,1),(jerry,2)), ((tom,1),(tom,2)), ((tom,1),(dog,10)),
((jerry,3),(jerry,2)), ((jerry,3),(tom,2)), ((jerry,3),(dog,10)),
((kitty,2),(jerry,2)),((kitty,2),(tom,2)), ((kitty,2),(dog,10)))
9.union 算子
对源RDD和参数RDD求并集后返回一个新的RDD
scala> val rdd11_1 = sc.parallelize(List(("tom",1),("jerry" ,3),("kitty",2)))
rdd11_1: org.apache.spark.rdd.RDD[(String, Int)] = ParallelCollectionRDD[29] at parallelize at <console>:24
scala> val rdd11_2 = sc.parallelize(List(("jerry" ,2),("tom",2),("dog",10)))
rdd11_2: org.apache.spark.rdd.RDD[(String, Int)] = ParallelCollectionRDD[30] at parallelize at <console>:24
scala> val rdd = rdd11_1 union rdd11_2
rdd: org.apache.spark.rdd.RDD[(String, Int)] = UnionRDD[31] at union at <console>:28
scala> rdd.collect
res12: Array[(String, Int)] = Array((tom,1), (jerry,3), (kitty,2), (jerry,2), (tom,2), (dog,10))
10.groupBy 算子
按条件分组
//第一种方法
//groupBy 是按key进行分组的,所以 _1
scala> rdd.groupBy(_._1).collect
res13: Array[(String, Iterable[(String, Int)])] = Array((dog,CompactBuffer((dog,10))), (tom,CompactBuffer((tom,1), (tom,2))), (jerry,CompactBuffer((jerry,3), (jerry,2))), (kitty,CompactBuffer((kitty,2))))
11.groupByKey 算子
在一个(K,V)的RDD上调用,返回一个(K, Iterator[V])的RDD
//第二种方法种方法
//groupByKey
scala> rdd.groupByKey.collect
res15: Array[(String, Iterable[Int])] = Array((dog,CompactBuffer(10)), (tom,CompactBuffer(1, 2)), (jerry,CompactBuffer(3, 2)), (kitty,CompactBuffer(2)))
12.reduceByKeyLocally 算子
def reduceByKeyLocally(func:(V,V)=>V):Map[K,V]
该函数将RDD[K,V]中每个K对应的V值根据映射函数来运算,运算结果映射到一个Map[K,V]中,而不是RDD[K,V].
var rdd1 = sc.makeRDD(Array(("A",0),("A",2),("B",1),("B",2),("C",1)))
rdd1.reduceByKeyLocally((x,y)=>x+y)
//scala.collection.Map[String,Int] = Map(B->3,A->2,C->1)
13.groupByKey 和 reduceByKey 区别(重点)
groupByKey
groupByKey对具有相同键的值进行分组,比如pairRDD={(1,2),(3,2),(1,7)},调用groupByKey的结果为{(1,[2,7]),(3,2)},groupByKey后仍然是pairRDD,只不过k–v中的value值为的Iterator类型。
reduceByKey
合并具有相同键的值,和reduce相同的是它们都接收一个函数,并使用该函数对值进行合并。reduceByKey() 会为数据集中的每个键进行并行的归约操作,每个归约操作会将键相同的值合并起来。因为数据集中可能有大量的键,所以 reduceByKey()没有被实现为向用户程序返回一个值的行动操作。实际上,它会返回一个由各键和对应键归约出来的结果值组成的新的 RDD。仍然是刚才的那个例子,reduceByKey后获得的结果是{(1,9),(3,2)}.
reduceByKey和groupByKey
其实reduceByKey操作可以通过groupByKey和reduce两个操作达到reduceByKey的效果。
14.reduceByKey 算子
在一个(K,V)的RDD上调用,返回一个(K,V)的RDD,使用指定的reduce函数,将相同key的值聚合到一起,与groupByKey类似,reduce任务的个数可以通过第二个可选的参数来设置
reduceByKey方法是聚合类函数
//正常写
rdd.reduceByKey((x,y)=>(x._1+y._1,x._2+y._2))
//简写
rdd.reduceByKey(_+_)
总结:
对比groupBy 算子与reduceByKey算子,reduceByKey方法的时间效率更优
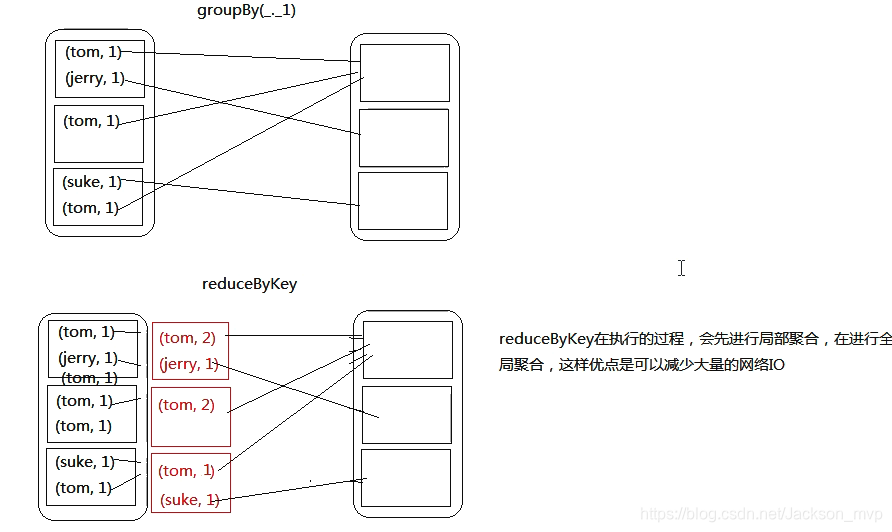
15.cogroup算子
在类型为(K,V)和(K,W)的RDD上调用,返回一个(K,(Iterable,Iterable))类型的RDD
cogroup 和 groupBykey的区别
cogroup不需要对数据先进行合并就以进行分组 得到的结果是 同一个key 和不同数据集中的数据集合
groupByKey是需要先进行合并然后在根据相同key进行分组
scala> val rdd11_1 = sc.parallelize(List(("tom",1),("jerry" ,3),("kitty",2)))
rdd11_1: org.apache.spark.rdd.RDD[(String, Int)] = ParallelCollectionRDD[40] at parallelize at <console>:24
scala> val rdd11_2 = sc.parallelize(List(("jerry" ,2),("tom",2),("dog",10)))
rdd11_2: org.apache.spark.rdd.RDD[(String, Int)] = ParallelCollectionRDD[41] at parallelize at <console>:24
scala> (rdd11_1 cogroup rdd11_2).collect
res27: Array[(String, (Iterable[Int], Iterable[Int]))] = Array((tom,(CompactBuffer(1),CompactBuffer(2))), (dog,(CompactBuffer(),CompactBuffer(10))), (jerry,(CompactBuffer(3),CompactBuffer(2))), (kitty,(CompactBuffer(2),CompactBuffer())))
16. intersection 算子
交集
val rdd8 = rdd6 intersection rdd7
println(rdd9.collect.toBuffer)
17.distinct 算子
去重出重复
println(rdd8.distinct.collect.toBuffer)
18.join 算子
相同的key会被合并
scala> val rdd10 = sc.parallelize(List(("tom",1),("jerry" ,3),("kitty",2)))
rdd10: org.apache.spark.rdd.RDD[(String, Int)] = ParallelCollectionRDD[46] at parallelize at <console>:24
scala> val rdd11 = sc.parallelize(List(("jerry" ,2),("tom",2),("dog",10)))
rdd11: org.apache.spark.rdd.RDD[(String, Int)] = ParallelCollectionRDD[47] at parallelize at <console>:24
scala> val rdd12 = rdd10 join rdd11
rdd12: org.apache.spark.rdd.RDD[(String, (Int, Int))] = MapPartitionsRDD[50] at join at <console>:28
scala> rdd12.collect
[Stage 41:> (0 + res44: Array[(String, (Int, Int))] = Array((tom,(1,2)), (jerry,(3,2)))
19.leftOuterJoin 算子
val rdd13 = rdd10 leftOuterJoin rdd11 //以左边为基准没有是null
println(rdd13.collect().toList)
20.rightOuterJoin 算子
val rdd14 = rdd10 rightOuterJoin rdd11//以右边为基准没有是null
println(rdd14.collect().toBuffer)
————保持饥饿,保持学习
Jackson_MVP















 263
263











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











