







前言
因为最近在学习以及手写淘宝分布式文件系统引擎,在这记录一下学习的整个过程,也把淘宝分布式文件系统引擎这一内容做一个模块持续更新直到把这个内容完成,在这过程中会涉及到文件系统,存储,哈希映射等等一些概念,希望这些总结也能对你有所帮助,因为自己也是第一次写这方面内容如果文中有出现一些错误或者是有不同理解的地方也欢迎提出来,谢谢(*^_^*)!!
完整的源码在下面这个链接哟
github源码
文件系统的基本概念
文件系统: 是一种把数据组织成文件和目录的一种存储方式,提供一些接口对于文件进行各种操作,还有对于文件权限进行控制访问,对于程序员来说就可以简单地把它看成提供各种接口的一种东西,方便我们对数据文件进行操作,我们先来看个小图。

对文件系统在现实中的理解:(中间人)
像我们平时写代码,利用read(),write()(这些接口在Linux系统下这个又叫系统调用)这些都是依靠文件系统提供的API来访问文件,其实文件绝大部分都存储在磁盘上,可以理解成存储设备是一个明星而文件系统是经纪人,你如果要找明星拍广告的话直接和经纪人说好,然后由经纪人和明星交谈,而不是直接和明星谈。
如果我们在windows上可以直接对文件进行删除和修改操作,像对界面操作(对文件右键删除或打开)让用户和界面进行交互,也可以是命令像Linux中的vi这些都是利用文件系统中的系统工具来实现对文件的操作,本质上都是通过文件系统来访问和操作文件。
存储的基本单位
- 硬盘的最小存储单位(Sector),一般每个扇区存储512字节(0.5KB)
如果你要向磁盘中写数据或者读数据必须分至少一个扇区给你,你就算写一个字节也会分一个扇区给你,读数据的话至少扫描 一个扇区(如果编程的话就另当别论了) - 越接近圆心扇区数量越少
类似光盘,只是磁盘是两边都有数据
文件存储的基本单位
对于我们程序员来说更在意的还是对于文件的存储
- 块是文件存储的最小单位,“块”的大小,最常见的是4KB,即连续8个扇区组成一个block,对于文件的操作也是一个块一个块的进行操作

我们可以利用stat来获取一下文件的具体信息
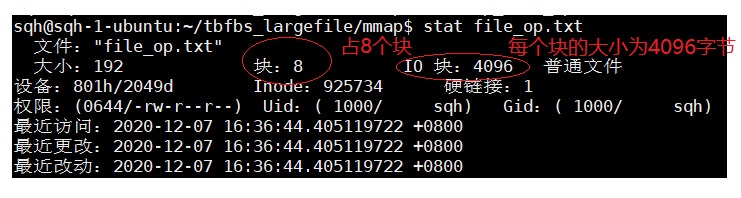
有没有考虑过为什么文件和块的大小会分这么大?
这是因为如果我们分配小了那么如果我们今后写文件的话要频繁的换存储位置,这样效率就很低了,如果分配这么大那么以后还有很多内容可以写就可以不用频繁换位置了,对于浪费的话这也是不可避免的
文件的结构
Ext*格式化分区 - 操作系统自动将硬盘分成三个区域。
- 目录项区 - 存放目录下子目录或者文件的列表信息
- 数据区 - 存放文件数据
- inode区(inode table) - 存放inode所包含的信息(文件inode元信息的集合))
一个文件由两个部分组成:块文件数据+Inode元信息
文件会被分成几个块,而对于inode区又被分为一个一个小块,inode作为主键,用户在利用路径进行文件的访问其实本质上也是利用其inode编号(相对于我们的身份证)来检索。
inode补充信息
①inode - "索引节点",储存文件的元信息,比如文件的创建者、文件的创建日期、文件的大小等等。每个inode都有一个号码(inode编号) 操作系统用inode号码来识别不同的文件。ls -i 查看inode编号 ②inode节点大小 - 一般是128字节或256字节。 inode节点的总数,格式化时就给定,一般是每1KB或每2KB就设置一个inode。 一块1GB的硬盘中,每1KB就设置一个inode,那么inode table的大小就会达到128MB,占整块硬盘的12.8%。
为什么有时候明明我们的硬盘还有空间但是创建文件会一直失败?
那可能的原因是我们建了很多小文件把系统一开始初始化的inode节点给用完了
系统读取文件三部曲

在我的理解中,像/demo/demo.txt,是先到根目录然后查看其对应的子目录项(同样是通过inode编号),找到demo这个目录再利用demo的Inode编号拿到demo目录的子目录项找到demo.txt的Inode编号然后去元信息区找到demo.txt的Inode元信息,然后文件系统利用驱动找到demo.txt对应存储位置,进行操作
可以把目录看作文件,找到目录的Inode编号,然后去Inode元信息区找到对应存储位置,和文件不同的是目录对应存储的是它的子目录项















 359
359











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









