







* 支撑向量机 Support Vector Machine
可以解决分类问题
也可以解决回归问题
· 先回忆一下逻辑回归的思想:

逻辑回归会找到一个决策边界,在边界的两侧分为不同的分类
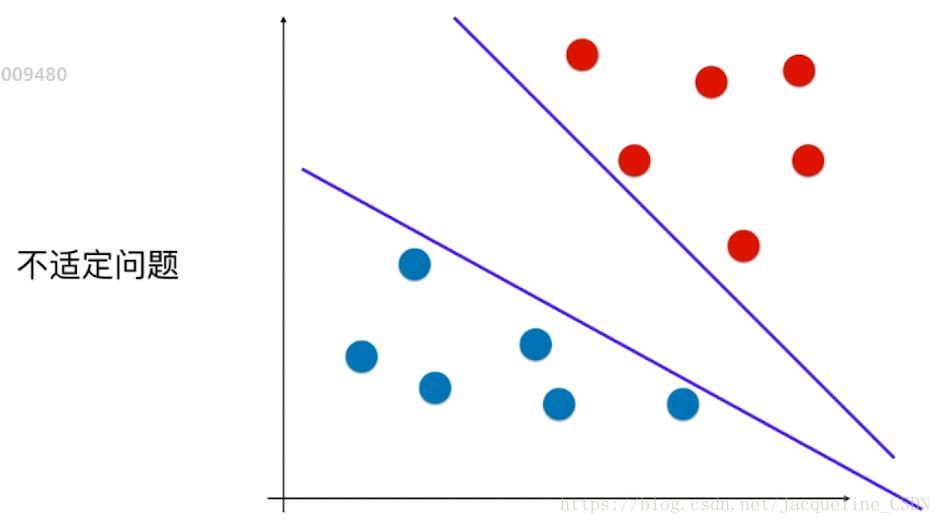
对于一些数据决策边界不唯一的问题,叫做不适定问题
· 逻辑回归算法是如何解决不适定问题的?
先定义了一个概率函数,即
· 支撑向量机解决的思路稍有不同
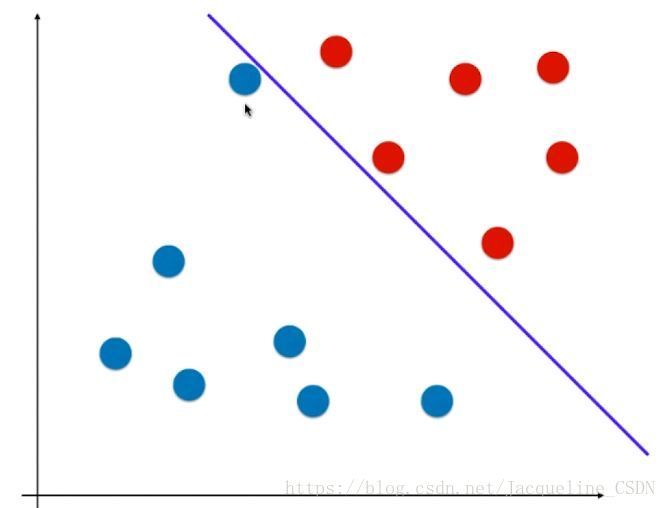
决策边界会非常好的将训练数据集分为两个部分,
但是这个决策边界的泛化能力不好。
因为如果再来一个样本,根据这个决策边界我们会认为它是蓝色类的,但是直观来看,新的样本点应该是红色类的,这样分类错误的原因是因为我们的决策边界离红色点太近了。
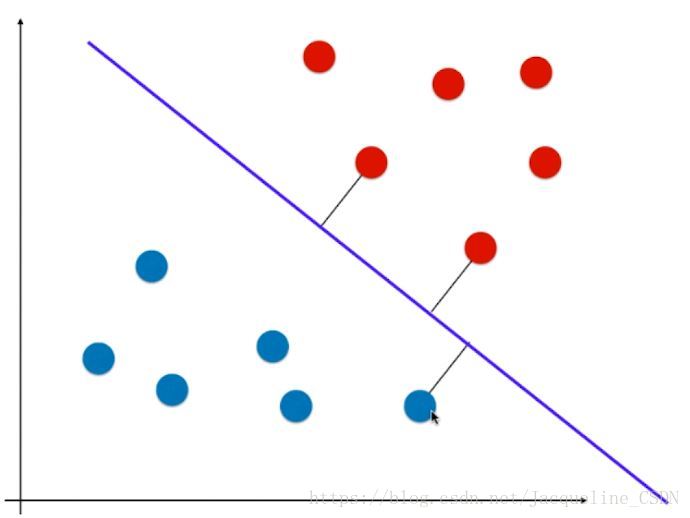
上述的决策边界的泛化能力比较好
因为离决策边界最近的3个点,我们让它离决策边界的距离尽可能远,即让决策边界离红色点尽可能远又离蓝色点尽可能远,同时它还能很好的区分红色和蓝色区域。
总结:
上述的决策边界不仅要很好的区分训练数据,同时考虑到未来,让它的泛化能力比较好,这就是SVM思想,对未来的泛化能力尽可能的好,并没有寄希望于数据的预处理,或者找到模型之后再对模型进行正则化,而是直接放在了算法的内部。这个思想的背后有数学的理论,可以严格证明出对于一个不适定问题,使用SVM找到的决策边界它的泛化能力是好的。SVM也是统计学习中一个非常重要的方法。
· 继续剖析SVM中的决策边界
上图中3个点离决策边界的距离一样
并且这3个点是所有点中离决策边界最近的3个点
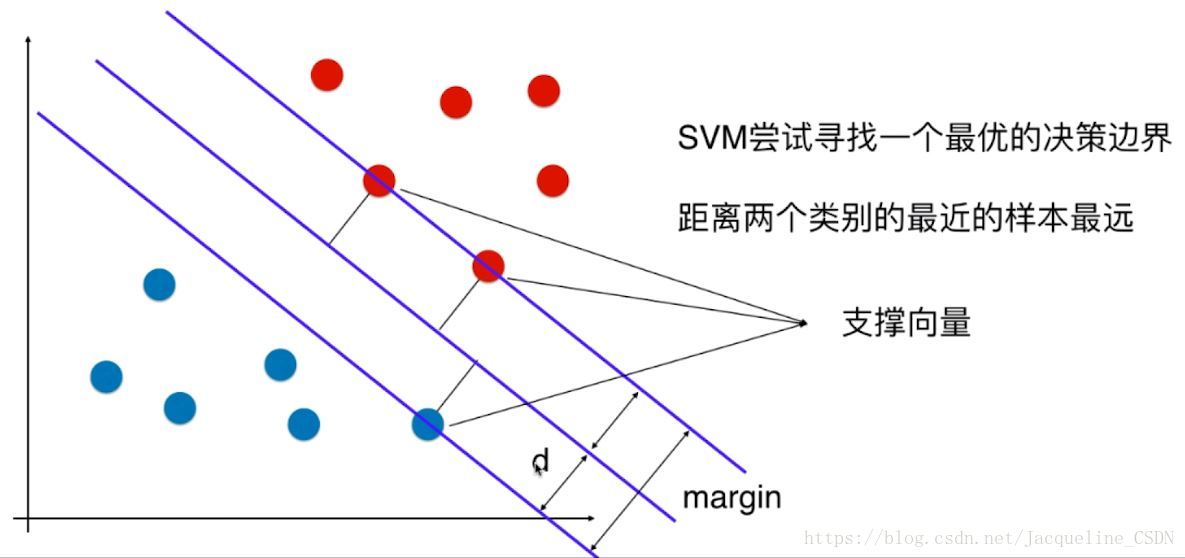
离决策边界最近的数据点又定义出了2根直线,他们与SVM得到的决策边界平行,2根直线定义了一个区域,在两根直线之间将不再有任何的数据点,SVM的决策边界是这个区域中间的那根线。
SVM尝试寻找一个最有的决策边界
距离两个类别的最近的样本最远
上面的支撑向量定义了一个区域,最优的决策边界被这个区域所定义(中间那根线)
因此支撑向量是SVM算法中非常重要的元素
SVM要最大化margin:
线性可分问题(对于样本点来说存在一根直线,或者高维空间中存在一个超平面将这些点划分)—> Hard Margin SVM
真实情况下很多数据线性不可分 —> Soft Margin SVM
* 思路总结:
机器学习算法中,尤其是参数学习算法,一个固定的套路,把我们要解决问题的思想先转化成一个最优化问题,然后最优化目标函数。














 922
922











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









