







目录
网络爬虫排除标准(Robots exclusion protocol)
在爬虫开始之前,我们要先了解我们是如何获得网页响应内容的;哪些东西可爬,哪些不可爬;以及网页的结构是什么。
网络请求工作原理
具体可以看这篇文章
简单来说就是
①浏览器发送请求给服务器。
②服务器收到浏览器发送的请求后,根据请求信息做出相应处理,然后把信息回传给浏览器。
③浏览器收到服务器的响应后,会对响应内容进行渲染,然后把网页呈现出来。
网络爬虫排除标准(Robots exclusion protocol)
一般情况下,服务器不会去太在意小爬虫,但是,对于高频恶意的爬虫,会非常占用服务器的资源,造成服务器卡顿等问题。因此,各大网站都有设置反爬虫措施,但是,有反爬虫机制,就有反反爬虫取抓取数据。
网络上存在着这么个协议,即网络爬虫排除标准协议,简称机器人协议(Robots 协议),去规范爬虫哪些可以抓取,哪些不可以。
查看协议的方法,只需要在主机网址后面加上/robots.txt即可
如淘宝的https://www.taobao.com/robots.txt

User-agent:表示爬虫身份
这里指百度爬虫,'Disallow:/'表示禁止百度爬虫爬取所有内容
User-agent:*表示的是其余爬虫,包括我们自己
它这里虽然没有disallow但是我们打开商品内容,如天猫超市
https://chaoshi.tmall.com/robots.txt

它已经变成了上面👆那样
爬虫只是一项工具,而机器人协议只是一项君子协议,你可以按着办,也可以不按着办,但是你有可能要承担法律的风险
一般而言,涉及用户信息,商业机密等数据都是不可爬的
html基础知识
接着,在爬虫之前,我们需要学习的是html的基础知识,当然,以下内容你不用刻意去记得,只要多练习几次爬虫,你就知道他们有什么用了
简介
概念:HTML 语言是用来告知浏览器如何组织页面的超文本标记语言。它不是一门编程语言,而是一种定义内容结构的语言。你也可以这么理解,它就是用来描述一个网页有什么的。
如果你想看一下它具体是长什么样的,你可以现在鼠标右键,看到底部有个检查,点击后出现的那一对代码,就是html。
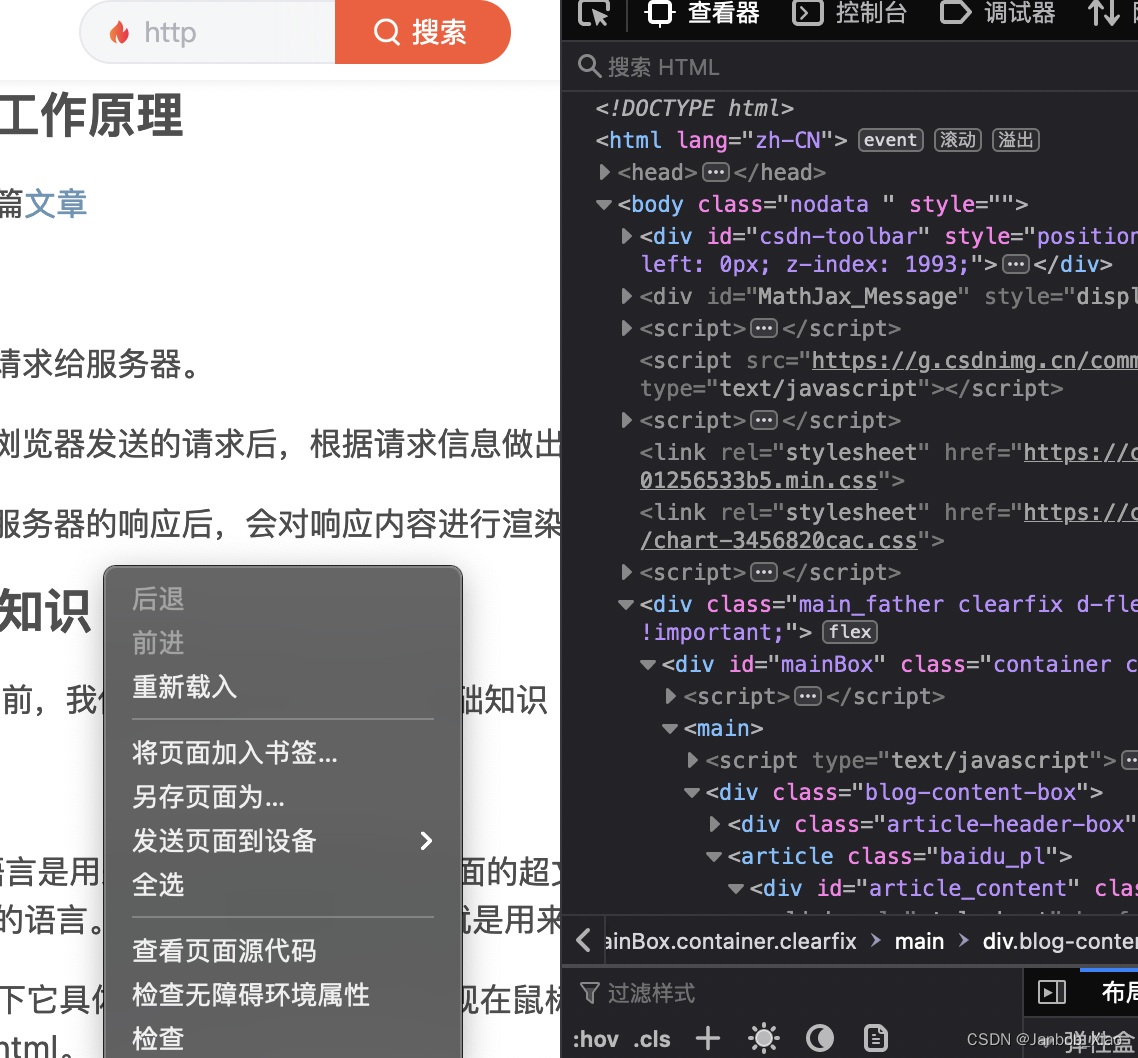
构成
HTML语言由HTML元素组成。
HTML元素的组成
- 开始标签<p>
- 元素内容
- 结束标签</p>
- 属性(可选)
<开始标签(属性)>元素内容<结束标签>
<a href="https://www.feimiao.cn/">www.feimiao.cn</a>如<a>标签,它通常会提供一个超链接在文本上,如上方相当于在www.feimiao.cn这里加了属性href的链接
这里我主要提一下几个需要记住的标签(如果忘记了,这里有标签图鉴)
相关标签
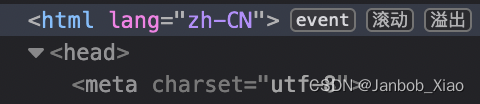
| <head>标签 | <head>描述了文档的各种属性和信息,包括文档的标题、在 Web 中的位置 以及和其他文档的关系等。绝大多数文档头部包含的数据都不会真正作为内 容显示给读者。 |
| <meta>标签 | 它通常在<head>标签里面,它的属性charset里面描述了编码,如我的这篇博客 就是'utf-8',但是也有些html的charset是'gbk'的,如果不去注意,后面解析的时 候会出现乱码现象。 |
 | |
| <p>标签 | <p>内容</p>定义一个段落(内容可不用'') |
 | |
| <br>标签 | 类似\n换行的功能 |
 | |
| <title>标签 | |
| <a>标签 | 实现在'内容'处加上超链接 |
| <body>标签 | 定义了 HTML 文档的主体,一般网页开发者会把想让用户在访问页面时看到的内容 都会写进这里。(爬虫点) |
| <h>标签 | 嵌套元素<h1><h2>....<h6>相当于一个个子标题 |
| <ul>标签 | 无序列表,中间用<li> 如<ul><li>xxx</li></ul> |
| <dd>标签 | <dd> 在定义列表中定义条目的定义部分,类似/t效果。 |
| <dt>标签 | <dt> 标签定义了定义列表中的项目(即术语部分)。 |
| <div>标签 | <div> 标签可以把文档分割为独立的、不同的部分。它可以用作严格的组织工具, 并且不使用任何格式与其关联。如果用 id 或 class 来标记 <div>, 那么该标签的作用会变得更加有效。 |
| id:只能在被赋予的页面使用一次 | |
| class:能在被赋予的页面使用多次 |
html网页的在线模拟可以试一试在这个网站编写代码















 775
775











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









