







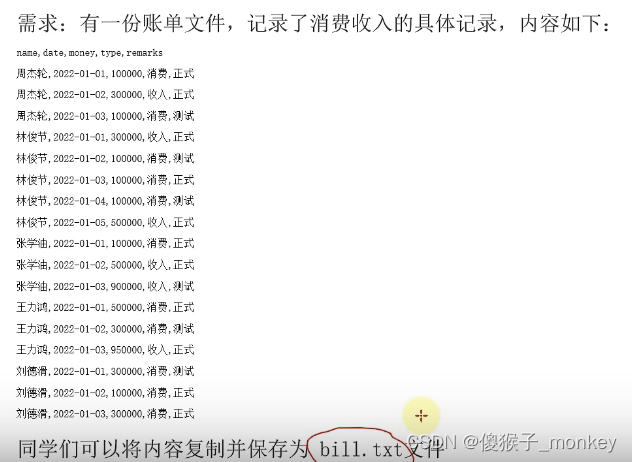

法一:
list1=[]
with open("C:/Users/DELL/Desktop/bill.txt","r",encoding="UTF-8") as f:
result = f.readlines()
# print(f"{result}")
for result1 in result:
# print(f"{result1}")
# print(type(result1))
if result1.split(",")[-1]=="正式\n":
list1.append(str(result1))
# print(f"{list1}")
with open("C:/Users/DELL/Desktop/test.txt","w",encoding="UTF-8") as f1:
for word in list1:
f1.write(word)法二:
fr = open("C:/Users/DELL/Desktop/bill.txt","r",encoding="UTF-8")
fw = open("C:/Users/DELL/Desktop/bill.txt","w",encoding="UTF-8")
for line in fr:
line = line.strip()
if line.split(",")[4]=="测试":
continue
fw.write(line)
fw.write("\n")















 1714
1714











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









