







这个专栏围绕着大模型的基本知识点深入浅出,章节之间的联系较为紧密。若在某个环节出现卡点,可以回到大模型必备腔调重新阅读。而最新科技(Mamba,xLSTM,KAN)则提供了大模型领域最新技术跟踪。若对于如果构建生成级别的AI架构则可以关注AI架构设计专栏。技术宅麻烦死磕LLM背后的基础模型。

GPU架构
在继续设计AI平台的架构设计之前,需要对GPU有着深入的理解。那么就伴随着本栏目深入浅出的学习GPU。从更高维度去看GPU,基本的模型如同下图,一般而言GPU会有PCIe的接口和CPU进行连接。换句话说,就是你拿到了一块GPU,在主板上找到对应的槽口插入即可。
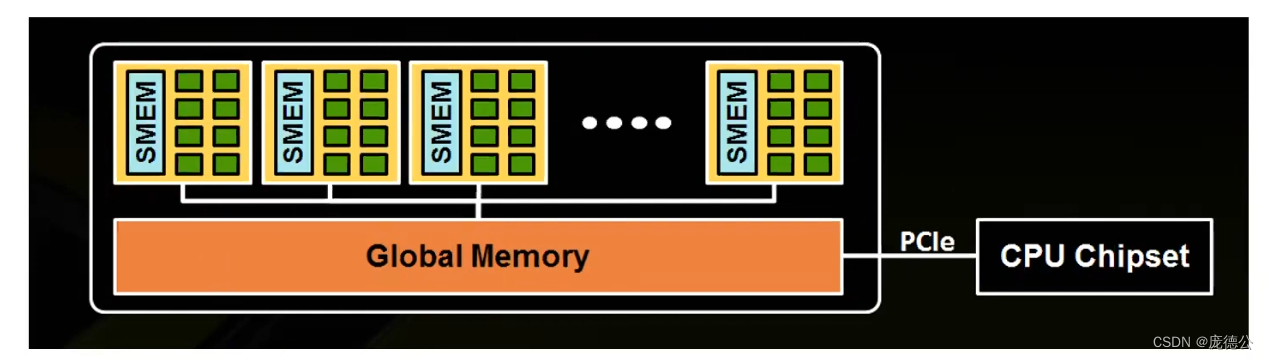
仔细观察上图,GPU卡上也有自己的内存(HBM),然后由很多的SMEM(下文简称SM)的运算单元组成。每个SM其实拥有一定数量的Cuda Core(运算单元),特殊的Tensor Core和更加高速的数据缓存。
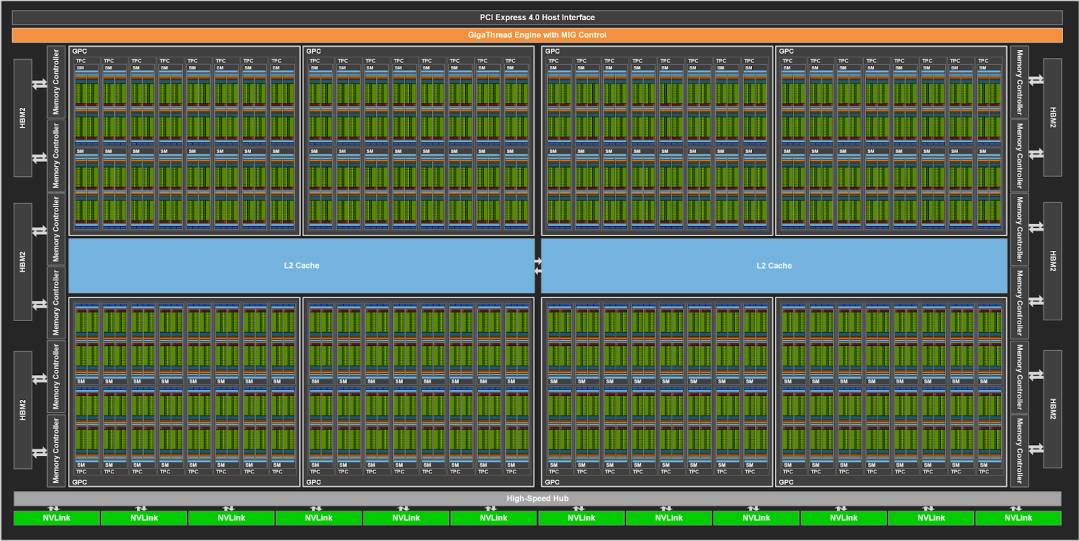
全GPU的GA100有128个SM。而拥有Tensor Core的A100则有108个SM
小知识:利用GPU的算力,则需要有如下步骤:
从CPU存储拷贝数据到GPU存储(内存 -> 显存)
调用kernel去操作保存在GPU存储里的数据(计算)
从GPU存储拷贝数据回CPU存储(显存 -> 内存)
以A100为例顺着思路继续往下看看SM(流式多处理器)架构,每个SM由四个子处理部分组成。每个SM存在全局的L1的指令缓存,每个子部分还可以分别拥有自己的Warp调度器,以及更加快速的缓存L0。如图每个子部分拥有16个INT32的cuda core,16个FP32的cuda core以及8个FP64的cuda core。
SM将32个并行的线程归为一组称为线程集(即 warp),以此为单位进行调度。A100中每个SM具有四个warp调度器和指令分派单元,允许同时有四个warp被分派指令和执行。
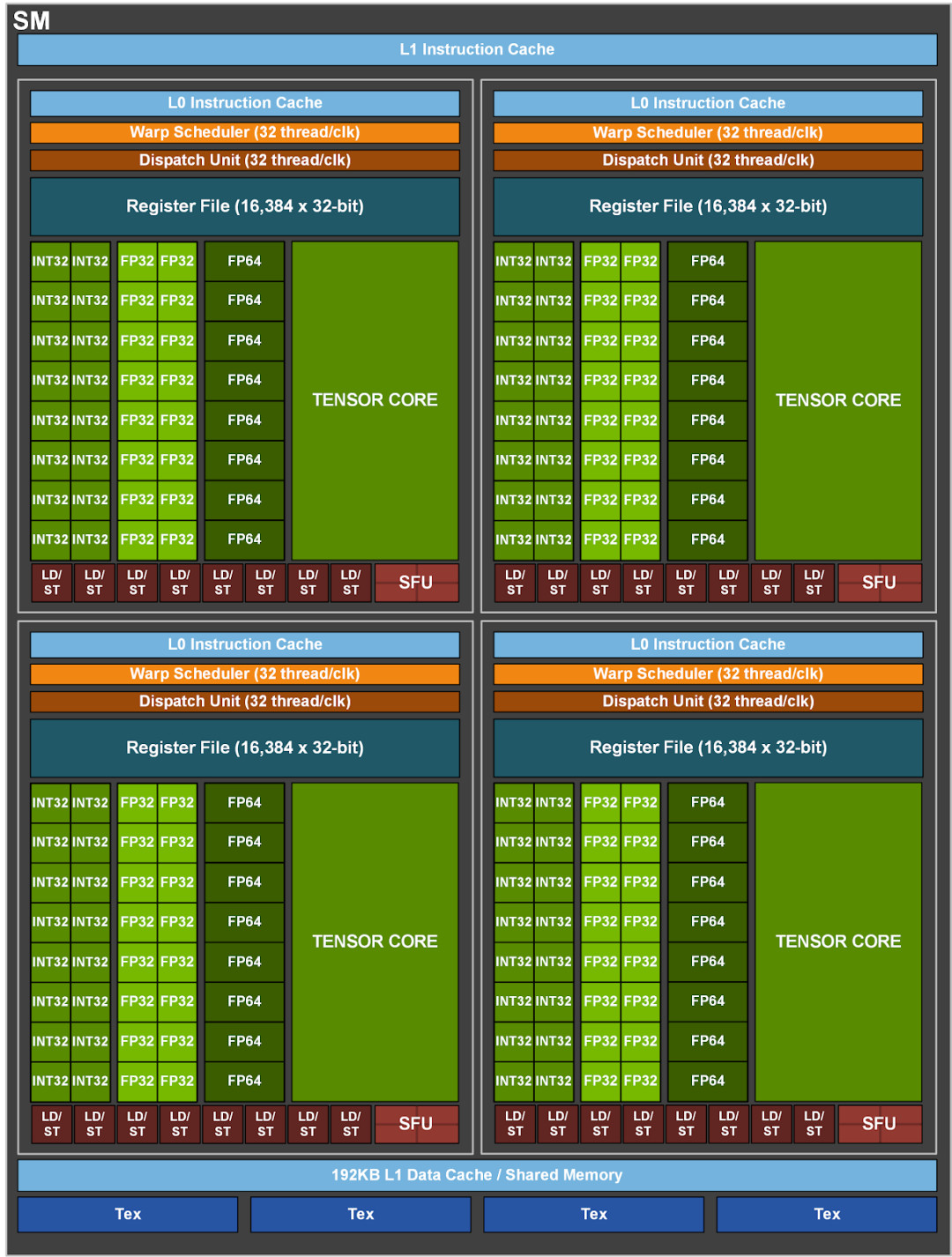
例如有个Warp正在处理标量FP32的乘加运算,因为单个Warp可以调度32个线程,而单个子部分的FP32的cuda core只有16个,因此需要两个周期才能完成所有的运算。不幸的是,不是所有的计算场景都可以凑整,按照经验统计在大模型训练的过程中,GPU的效用一般在0.3左右。

Tensor Core
上图有个关键词Tensor Core,这是专门为了深度学习而引入的特殊的运算单元。一次可以完成矩阵A*B+C的操作。不同版本的GPU的Tensor Core在精度的支持上会存在差异。Ampere这一代还支持2:4的稀疏矩阵。
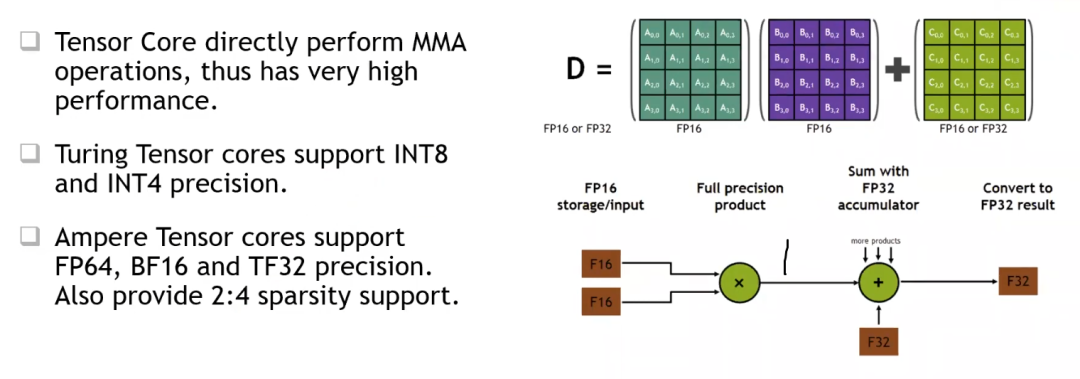

GPU的内存模型
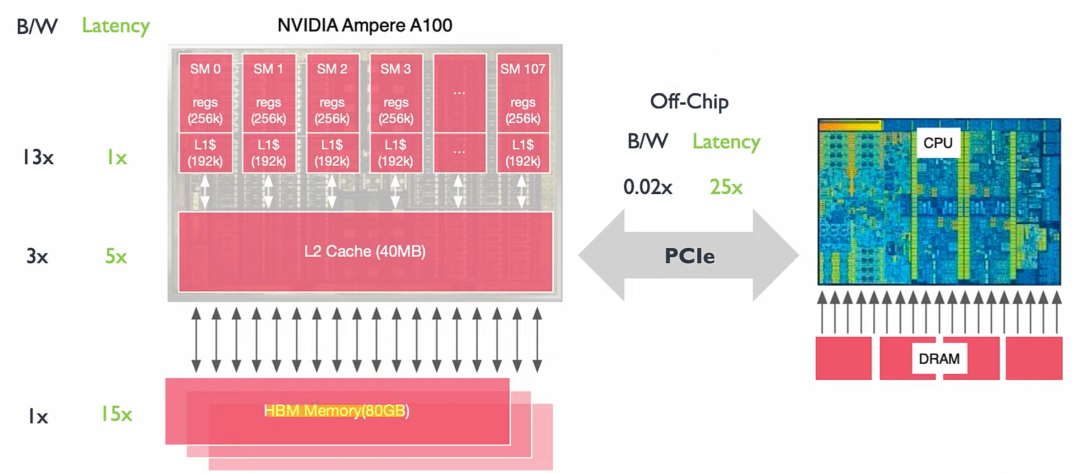
左侧代表GPU卡,右侧代表CPU,两者通过PCIe(主板槽口)连接。
黑色部分代表着不同类型缓存的存储带宽,以GPU全局内存(GMem)为基准,分别标出了各种缓存的倍率,可以看出L1最快。
绿色部分代表不同类型缓存的延迟,这里以L1缓存为基准,分别标出了各种缓存的延迟倍率。可以看出不在GPU的数据读取最慢,延时达到25倍。
单个SM的底部有L1 Cache,这个cache段是允许各个Core都可以访问的段,在L1 Cache中每个SM都有一块专用的共享内存。作为芯片上的L1 Cache他的大小是有限的,但它非常快,肯定比访问GMem快得多。
实际上L1 Cache拥有两个功能,一个是用于SM上Cuda Core之间相互共享内存,另一个则是普通的cache功能。当Cuda Core需要协同工作且彼此交换结果的时候,编译器编译后的指令会将部分结果储存在共享内存。
当用做普通cache功能的时候,当Cuda Core需要访问GMem的数据时,首先会在L1中查找,如果没找到,则回去L2 Cache中寻找,如果L2 Cache也没有,则会从GMem中获取数据。L1访问最快, L2 以及GMem递减。值得一提的是共享内存L1和寄存器可以储存各个Cuda core的计算中间结果。

GPU的互联模式

上图以P100为例,GPU之间利用PCIe(黑色)和NVlink(绿色)混合连接,NVlink实现了显卡之间点对点的高速数据传输。当然在10卡以上的集群模式会更加复杂(后文会详细阐述)。
训练模型的过程中点对点的数据交换速率十分重要,单个A100的GPU可以支持12根互联,每根的速率可以达到50G/s,因此A100的双向带宽高达600G/s。之前美国禁令中的一个约束就是出口GPU的带宽必须小于600G/s。A800应运而生将速率降低至500G/s。
题外话:很多大模型的研发者采用RTX游戏显卡来替代,因为RTX显卡之间的互联速率远低于A系列的显卡,所以在训练效率上不高。然而在部分的推理场景则性价比非凡。















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









