








大模型技术论文不断,每个月总会新增上千篇。本专栏精选论文重点解读,主题还是围绕着行业实践和工程量产。若在阅读过程中有些知识点存在盲区,可以回到如何优雅的谈论大模型重新阅读。另外斯坦福2024人工智能报告解读为通识性读物。若对于如果构建生成级别的AI架构则可以关注AI架构设计。技术宅麻烦死磕LLM背后的基础模型。当然最重要的是订阅跟随“鲁班模锤”。
记得在《重新审视神经网络》这篇文章中提及,任何人都可以构建自己心目中的神经网络。在Transformers、Mamba、KAN之后,长短期记忆 (LSTM) 架构的发明者Sepp Hochreiter和他在NXAI的团队推出了一种称为扩展LSTM (xLSTM) 的新变体。本文为通识版本,后续将会推出细究版本,敬请期待!

xLSTM的背景
LSTM在自然语音处理的领域影响巨大,但它也有局限性。在一些特殊的任务上,比如最临近邻搜索的时候,在记忆细胞的更新方面就颇有压力。来自ELLIS、LIT AI实验室、奥地利林茨NXAI实验室的研究人员希望通过解决LSTM语言模型的局限性来增强LSTM。
改进点有不少,小编认为没有LSTM的基础很难完全看得明白。因此决定初看改进点之后,将一些基本的知识点做回顾,否则只会走马观花。xLSTM的改进点:
-
引入具有适当归一化和稳定技术的指数门控(可以理解为激活函数)。
-
修改LSTM记忆结构,推出两种记忆细胞。第一种是sLSTM,它具有标量记忆、标量更新和新记忆混合的能力,第二种是mLSTM,它拥有矩阵记忆,而且这些记忆可以通过协方差更新且全部具备并行运算
-
将上面的LSTM扩展体结合残差网络设计模式产生xLSTM块,然后将这些块堆叠到xLSTM架构。

和Transformer和状态空间模型相比,指数门控和修改后的记忆结构增强了xLSTM的性能,无论是在性能还是扩展方面表现尚可。这些突破让LSTM长期在大语言模型上的瓶颈得到解决,也许未来可能会成为新的大语言技术巨头。
Transformer只是一种大语言模型的架构,核心还是注意力机制,然而计算的复杂度还是摆在那儿。有不少的竞争者例如Synthesizer、Linformer、Linear Transformer和Performer专注于线性开销的注意力技术。状态空间模型 (SSM) 因其上下文长度的线性也备受关注,S4、DSS、BiGS和Mamba异军突起。具有线性单元和门控机制的循环神经网络 (RNN) 也在挣扎,HGRN和RWKV。xLSTM则利用协方差更新规则、记忆混合和残差堆叠架构进行关键组件的增强,不容小觑。
在xLSTM用于语言建模的实验评估中,xLSTM的功能在形式语言、联想回忆任务和远程竞技场场景上进行了测试。与现有方法的比较揭示了xLSTM 在验证困惑度方面的优越性。
消融研究强调了指数门控和矩阵记忆在xLSTM性能中的重要性。对300B 个token进行的大语言建模验证了xLSTM的有效性,显示了其在处理长上下文、下游任务和多样化文本域方面的鲁棒性。缩放行为分析表明,随着规模的增加,xLSTM与其他模型相比具有良好的性能。随着序列长度的增加,xLSTM架构的时间复杂度为O(N),内存复杂度为O(1),这点比Transformer更加高效。

指数门控
xLSTM论文中引入的指数门控机制是对LSTM中使用的传统sigmoid门控的重大改进。这里要给大家科普一下,模型输出数值一般会经过激活函数,sigmoid是其中的一种,任何输入都会得到0~1期间的数值。一般在LSTM中,0就代表着不通过,1代表允许通过。那么门控的意思大白话就是门阀,它决定着信息的穿透度。
|
|
|
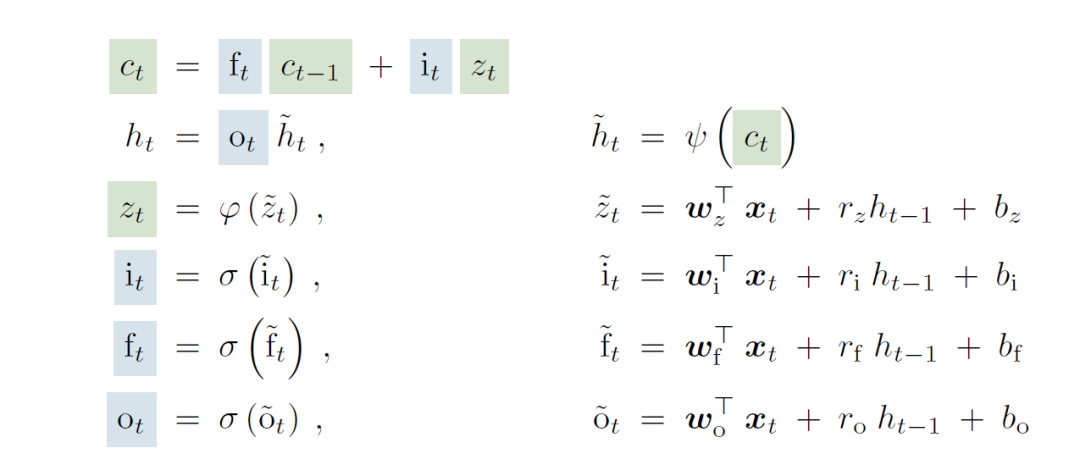
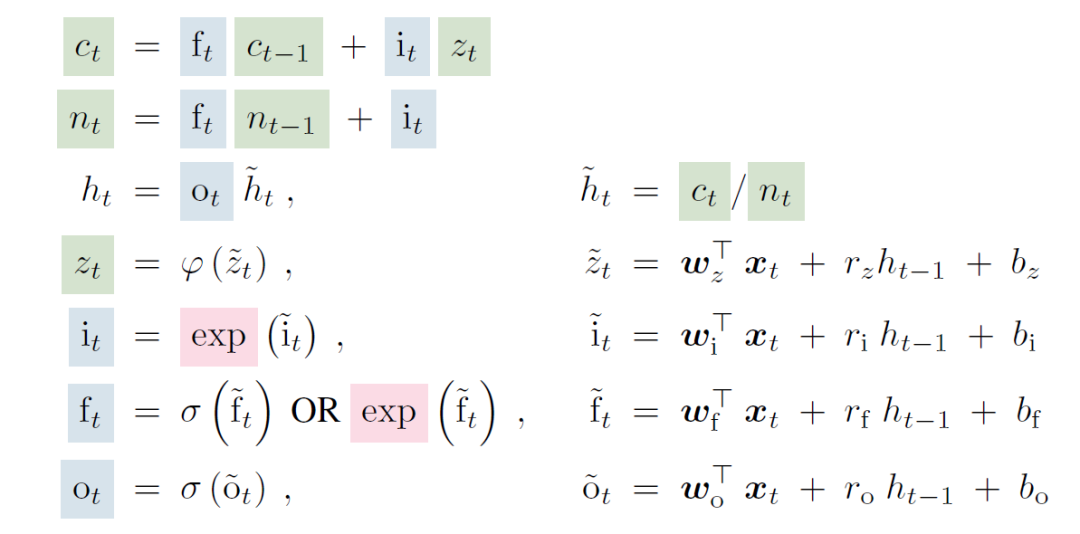
上图就对比了原来LSTM和sLSTM的运算公式,新的里面由σ函数被替代为exp函数。原论文对于替换的解释是由此增强了模型在处理新信息时能有效修改和更新其记忆的能力。
在传统的 LSTM 中,sigmoid函数限制了模型对记忆单元状态进行实质性改变的能力,特别是当门值接近0或1时。这种限制阻碍了LSTM快速适应新数据,并可能导致低效的记忆更新。
xLSTM通过用指数激活函数替换sigmoid激活函数来解决此问题。指数门控允许记忆细胞状态发生更明显的变化,(指数函数的取值范围0~+∞)使模型能够快速整合新信息并相应地调整其记忆。归一化器有助于稳定指数门控并维持输入门和遗忘门之间的平衡。

矩阵记忆
xLSTM论文的另关键贡献是引入了矩阵记忆体(内存,或者称之存储器),它取代了传统 LSTM中使用的标量存储单元。在LSTM中,存储单元由单个标量表示,约束了每个时间步可以存储和处理的信息量。这种局限性可能会阻碍模型捕获和保留复杂依赖关系和长期信息的能力。
xLSTM通过采用矩阵存储器突破这一限制,其中每个存储器单元由矩阵而不是标量表示。从标量内存到矩阵内存的转变显着增强了模型存储和处理丰富的高维信息的能力。
矩阵内存允许xLSTM捕获输入数据中更复杂的关系和依赖关系。它使模型能够更全面地表示上下文和长期依赖性,从而提高需要理解和生成复杂序列的任务的性能。

可并行架构
xLSTM最重要的进步是引入了可并行架构,它解决了传统LSTM的主要限制。在传统的LSTM中,令牌的处理是按顺序执行的,其中每个令牌一次处理一个,这限制了模型利用并行性的能力,并导致训练和推理时间变慢。xLSTM 架构引入了mLSTM(矩阵内存LSTM)和sLSTM(标量 LSTM)块的灵活组合,从而实现令牌的并行处理。
|
|
|
| mLSTM块 | sLSTM块 |
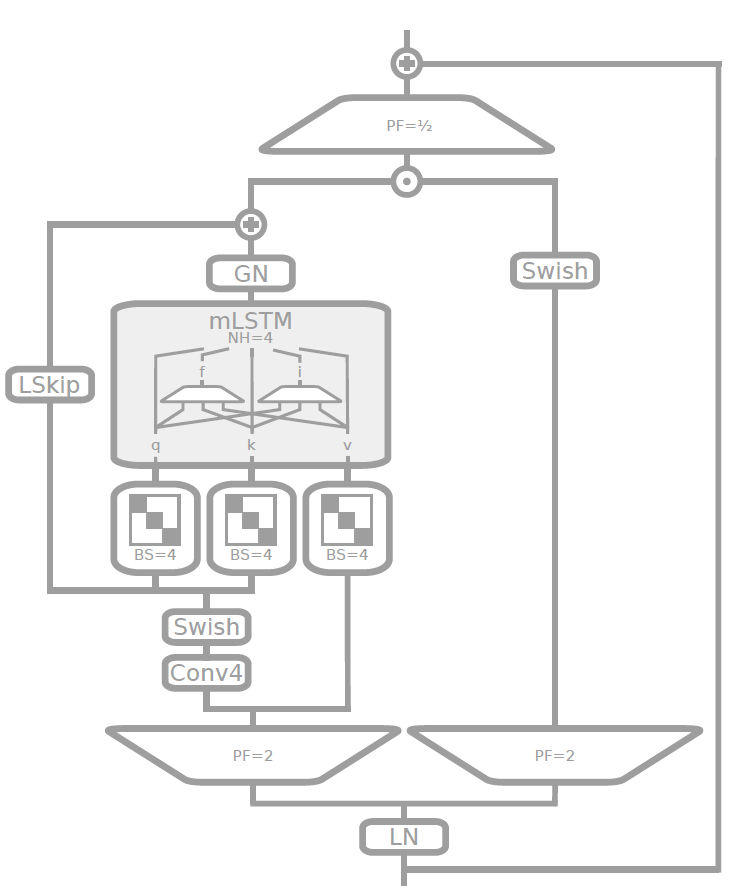
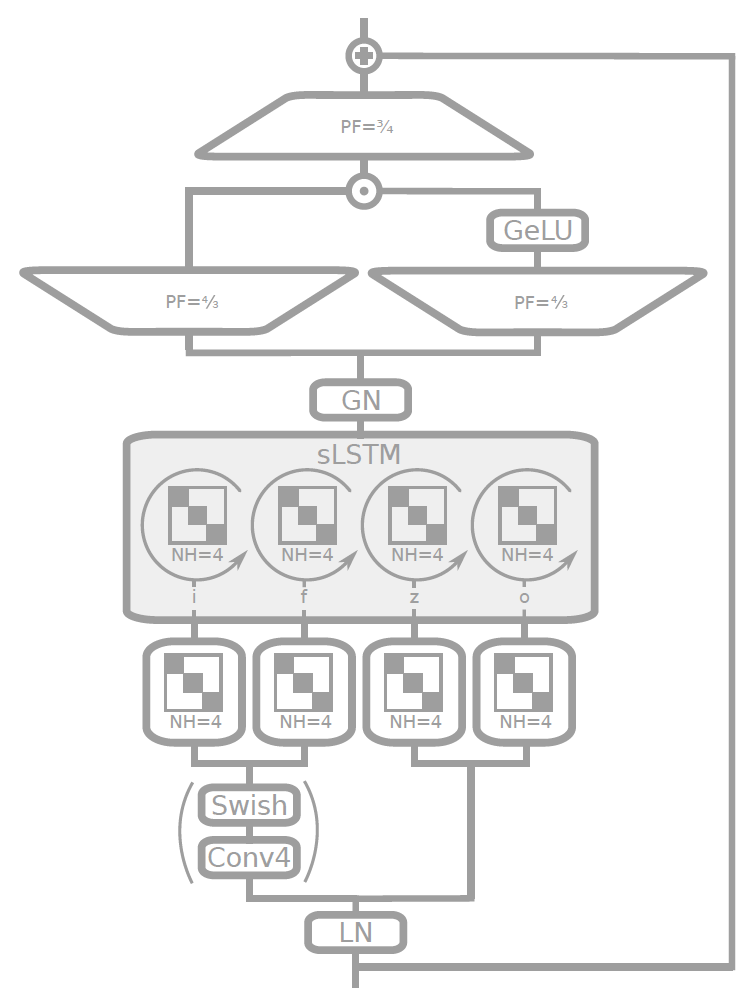
mLSTM被设计为同时对整个令牌序列进行操作,从而实现类似于 Transformer 模型实现的并行性的高效并行计算。主要还是利用矩阵存储机制,使它们能够并行捕获和处理所有令牌的丰富、高维信息。这种并行处理能力显着加快了训练和推理过程,使 xLSTM 比传统 LSTM 的计算效率更高。
另一方面,sLSTM 则被设计为保留了传统LSTM的顺序处理性质,允许模型捕获对于特定任务可能很重要的某些顺序依赖性。在 xLSTM 架构中可以灵活的以不同比例堆叠mLSTM和sLSTM块,提供了并行性和顺序建模之间的平衡,从而能够适应各种语言建模任务。















 2378
2378

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









