







大模型技术论文不断,每个月总会新增上千篇。本专栏精选论文重点解读,主题还是围绕着行业实践和工程量产。若在某个环节出现卡点,可以回到大模型必备腔调或者LLM背后的基础模型新阅读。而最新科技(Mamba,xLSTM,KAN)则提供了大模型领域最新技术跟踪。若对于具身智能感兴趣的请移步具身智能专栏。技术宅麻烦死磕AI架构设计。


FineWeb
FineWeb是一个新发布的开源数据集,它希望通过其广泛收集的英语网络数据来推动语言模型研究发展。FineWeb 由 huggingface 领导的团体研发,提供超过15万亿个Token,这些Token来自2013年至2024年的 CommonCrawl转储。
FineWeb在设计时一丝不苟,使用datatrove进行流水线处理。这个过程针对数据集进行清理和重复数据删除的操作,从而提高其质量和适用性以便利于大语言模型的训练和评估。
FineWeb的主要优势之一在于其性能。通过精心策划和创新的过滤技术,FineWeb在各种基准测试任务中优于C4、Dolma v1.6、The Pile和 SlimPajama 等已建立的数据集。在FineWeb上训练的模型表现出卓越的性能,它已经成为自然语言处理的宝贵资源。
透明度和可重建是FineWeb发展的核心原则。该数据集及其处理管道代码在ODC-By 1.0许可下发布,使研究人员能够轻松复制和构建其发现。FineWeb还进行了广泛的消融和基准测试,以验证其对已建立数据集的有效性,确保其在语言模型研究中的可靠性和有用性。
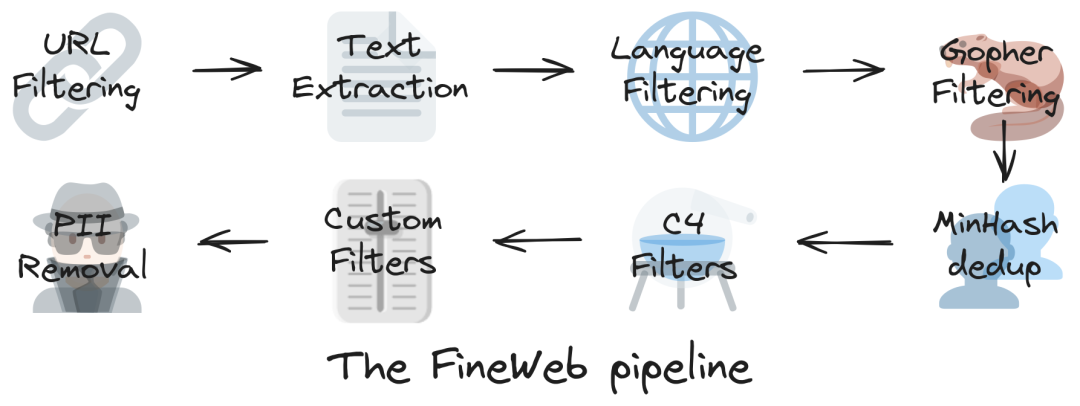
FineWeb利用了URL 过滤、语言检测和质量评估等过滤步骤提高数据集的完整性和丰富性。每个CommonCrawl转储都使用高级MinHash技术单独删除重复数据,进一步提高了数据集的质量和实用性。<小编认为Minio其实也是可以的!>

关联阅读
2024年似乎已经打破了数据集方面的“4 分钟英里”。尽管Redpajama 2提供了高达30T 的Tokens,但大多数在2023年的LLMs都使用高达2.5T 的Tokens进行训练。随后DBRX推出12T的Tokens,Reka Core/Flash/Edge 推出5T的Tokens,Llama 3推出15T的Tokens。现在Huggingface 发布了一个开放数据集,其中包含12年过滤和重复数据删除的CommonCrawl的数据,总共有15T个Tokens。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









