







需注意的点:
1.字符串B中可能含有多个重复的大写字母,则A中此大写字母的个数至少要大于B中的个数。
目前的思路:
先把字符串A中26个字母的个数统计出来,按序存储在一个string型a里面,B同理,存储在string型b里面,然后直接比较a>b,true则包含。
bug1:
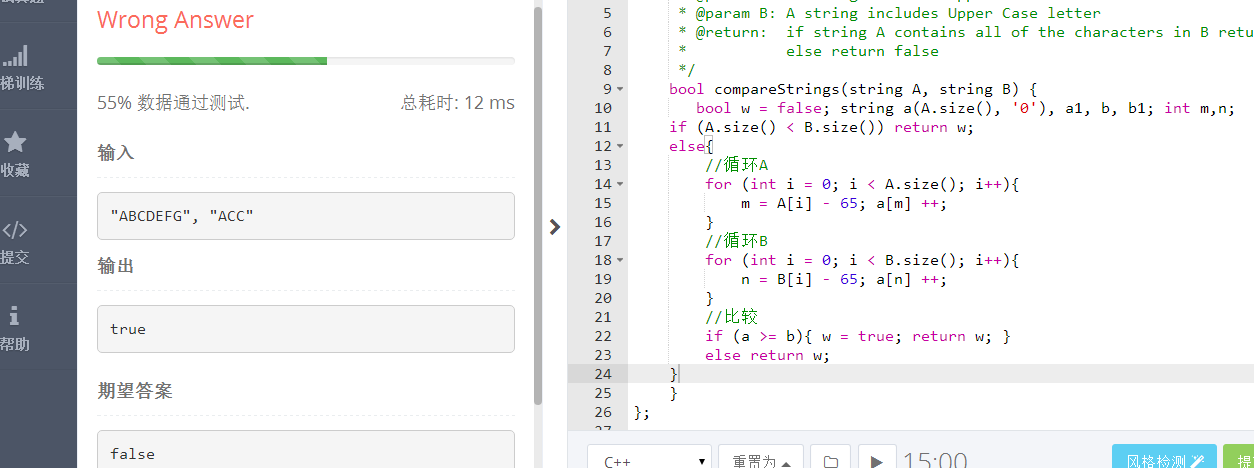
主要错误点:(一些小错点忽略)string a 应该为string a(26,’0’);
bug2:
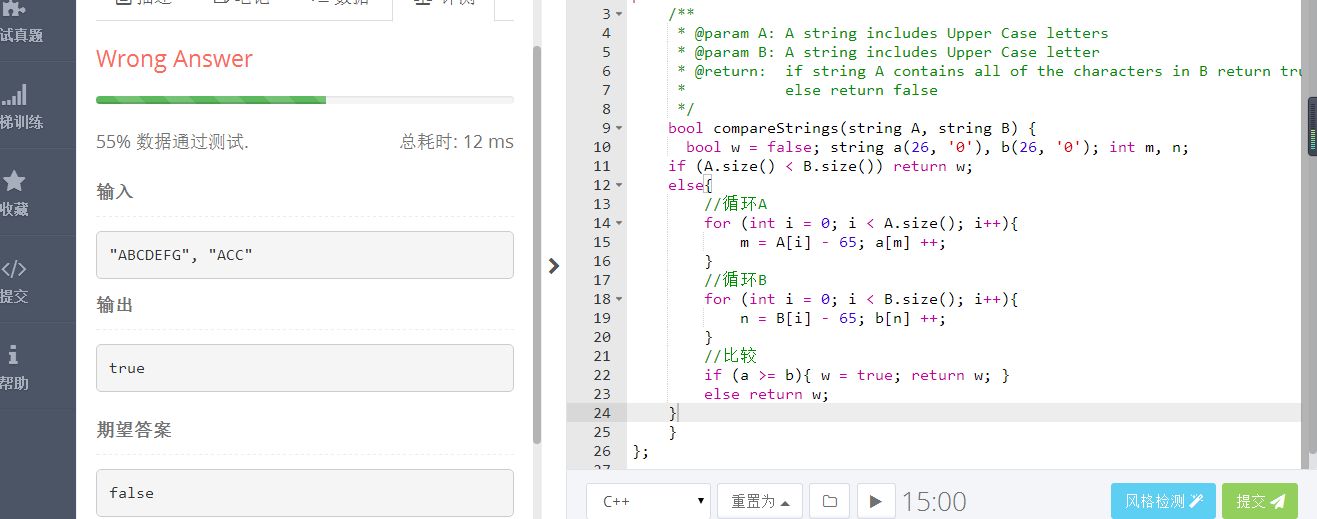
原因是:比如A(“ABCDEFG”),B(“ACC”),则a就是(“111…”)26个1,b就是(”102000…“),就产生了判断错误。
bug3:
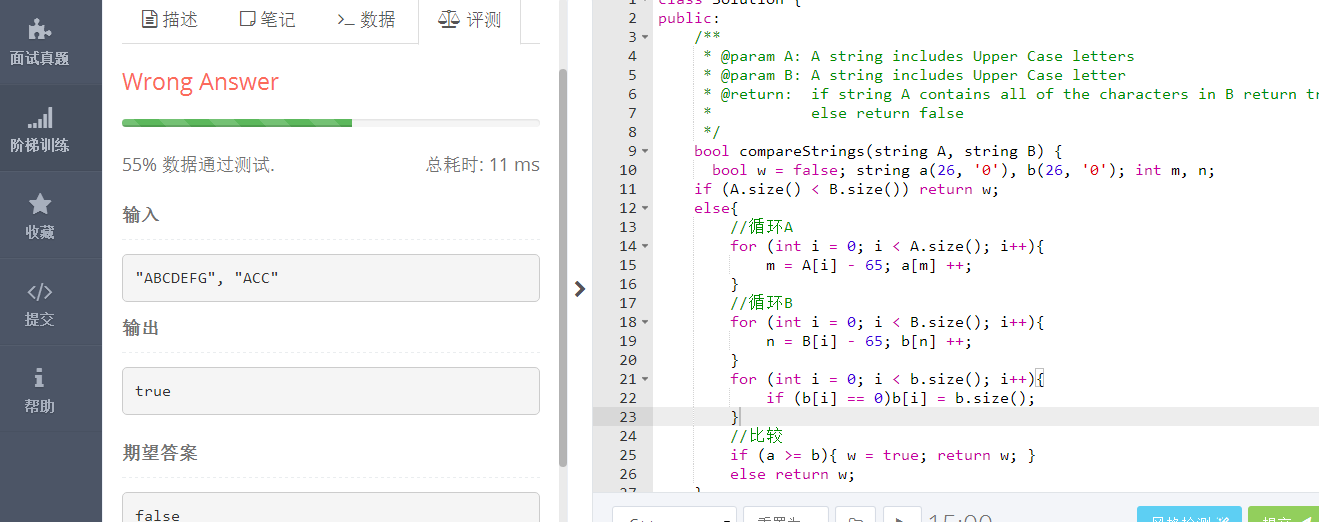
原因:这里主要是
for (int i = 0; i < b.size(); i++){
if (b[i] == 48) b[i] = b.size();
}
中b[i] = b.size();没有执行成功,于是我做了以下小实验:
int main() {
string b("10200");
for (int i = 0; i < b.size(); i++){
if (b[i] == '0') {
b[i] = b.size(); cout << b[i];
}
}
system("Pause");
}输出结果:
改正:b[i] = b.size()+’0’;
bug3:
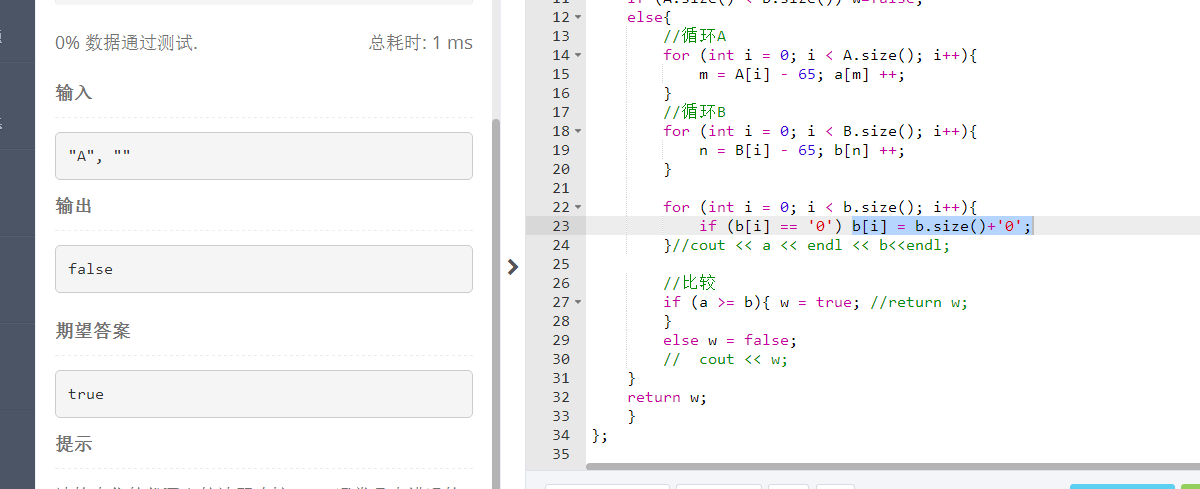
bug4:

bug5:
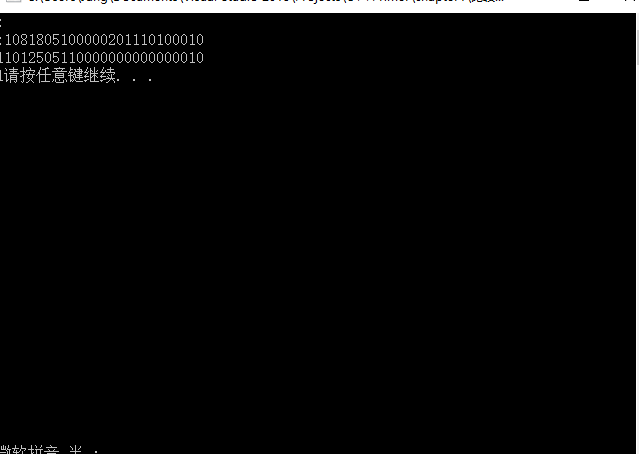
原因:不能超过9,超过以后按Ascii码计算,但是后来我发现这个没关系。
之前的思路的漏洞:
1.B有可能是空字符串
2.A(“ABCDEFG”),B(“ACC”),则a就是(“111…”)26个1,b就是(”102000…“),就产生了判断错误。
改正:
for (int i = 0; i < B.size(); i++)//之前的小bug:i<b.size();
if (b[i] == '0') b[i] = a[i];
}3.A(“ABCDEFG”),B(“BCC”),则a就是(“111…”)26个1,b就是(”002000…“),就产生了判断错误。
所以又改动
for (int i = 0; i < B.size(); i++){
if (a[i]>b[i])a[i] = b[i];
//if (b[i] == '0') b[i] = a[i];
}















 357
357

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









