







看到一篇不错的文章,分享一下,转发于彻底掌握SQL窗口函数
一、简介
窗口函数是编写高效且易于理解的SQL代码的关键。了解这些函数的工作原理和使用时机,将为解决报表问题带来新的方法。
本文的目标是以易于理解的方式逐步解释SQL中的窗口函数,使你不必仅仅依靠记忆语法来了解它们。
以下是我们将涵盖的内容:
-
对于如何看待窗口函数的解释。
-
逐渐增加难度的多个示例。
-
查看一个具体的实际案例,将所学知识应用到实践中。
-
回顾我们所学到的内容。
我们的数据集很简单,是2023年两个地区的六行收入数据。

二、窗口函数是子分组
如果我们使用这个数据集,对每个地区的收入进行GROUP BY求和,结果只会剩下两行,每个地区一行,然后是收入的总和:

我希望你将窗口函数视为类似于这样的方式,但聚合并不是减少行数,而是在“后台”运行,并将值添加到现有行中。
首先,举个例子:
SELECT
id,
date,
region,
revenue,
SUM(revenue) OVER () as total_revenue
FROM
sales
请注意,我们没有使用任何GROUP BY,数据集保持不变。然而,我们还是能够获得所有收入的总和。在我们更深入地了解它的工作原理之前,让我们先快速了解一下全部语法,然后再开始积累知识。
三、窗口函数语法
语法如下:
SUM([some_column]) OVER (PARTITION BY [some_columns] ORDER BY [some_columns])
将每个部分拆开来看,我们就会发现这些内容:
-
聚合或窗口函数:
SUM、AVG、MAX、RANK、FIRST_VALUE。 -
OVER关键字表示这是一个窗口函数。 -
PARTITION BY部分用于定义分组。 -
ORDER BY部分定义了是否是运行函数(我们稍后会介绍)。
暂时不必急着解释这些字符串的含义,当我们讲解示例时,它们会变得清晰。现在只需知道我们将使用OVER关键字来定义窗口函数。正如我们在第一个示例中看到的那样,这是唯一的要求。
四、逐步建立、加深我们的理解
接下来,我们将在函数中应用一个分组,这才是真正有用的东西。保留初始计算是为了向大家展示我们可以同时运行多个窗口函数,这意味着我们可以在同一个查询中同时进行不同的聚合,而无需使用子查询。
SELECT
id,
date,
region,
revenue,
SUM(revenue) OVER (PARTITION BY region) as region_total,
SUM(revenue) OVER () as total_revenue
FROM sales

如前所述,我们使用PARTITION BY来定义由聚合函数使用的分组(窗口)。因此,在数据集保持不变的情况下,我们可以得到:
-
每个地区的总收入。
-
整个数据集的总收入。
我们也不局限于单个组。与GROUP BY类似,我们也可以根据地区和季度对数据进行分区,例如:
SELECT
id,
date,
region,
revenue,
SUM(revenue) OVER (PARTITION BY
region,
date_trunc('quarter', date)
) AS region_quarterly_revenue
FROM sales

从图中我们可以看到,同一地区和季度仅有的两个数据点被分组在一起!
到目前为止,希望你清楚地了解到,我们可以将其视为在原地执行GROUP BY操作,而不会减少数据集中的行数。当然,我们并不总是希望这样,但是经常会看到查询中有人对数据进行分组,然后将其与原始数据集连接起来,使本来可以使用单个窗口函数的操作变得复杂起来。
继续讲解ORDER BY关键字。这个关键字定义了一个运行窗口函数。你可能在生活中听说过运行求和(Running Sum),但如果没有听说过,我们将从举例开始,以便一切都清楚明了。
SELECT
id,
date,
region,
revenue,
SUM(revenue) OVER (ORDER BY id) as running_total
FROM sales

这里发生的是,我们逐行逐行地将收入与之前的所有值相加。这是按照id列的顺序进行的,但也可以是任何其他列。
这个具体的例子并不是特别有用,因为我们是在随机的几个月份和两个地区之间求和,但是根据我们所学到的知识,我们现在可以找到每个地区的累计收入。我们可以通过在每个组内应用滚动求和来实现这一点。
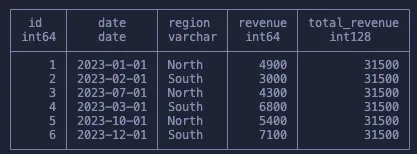
SELECT
id,
date,
region,
revenue,
SUM(revenue) OVER (PARTITION BY region ORDER BY date) as running_total
FROM sales
请花点时间确保你理解这里发生了什么:
-
对于每个地区,我们逐月累加收入。
-
一旦对该地区完成累加,我们就转到下一个地区,从头开始,并再次逐月累加。
值得注意的是,在编写这些滚动函数时,我们有其他行的“上下文”。也就是说,要获得某一点的运行总和,我们必须知道前几行的前值。当我们知道可以手动选择要聚合的前/后多少行时,这一点就变得更加明显了。
SELECT
id,
date,
region,
revenue,
SUM(revenue) OVER (ORDER BY id ROWS BETWEEN 1 PRECEDING AND 2 FOLLOWING)
AS useless_sum
FROM
sales

在这个查询中,我们指定要查看每一行后面的一行和前面的两行,这意味着我们可以得到这个范围的总和!根据你要解决的问题,这可能会非常强大,因为它可以让你完全控制如何对数据进行分组。
最后,在我们进入一个更复杂的示例之前,想要提到的最后一个函数是RANK函数。这个函数在面试中经常被问到,它背后的逻辑与我们迄今为止所学到的所有知识都是一样的。
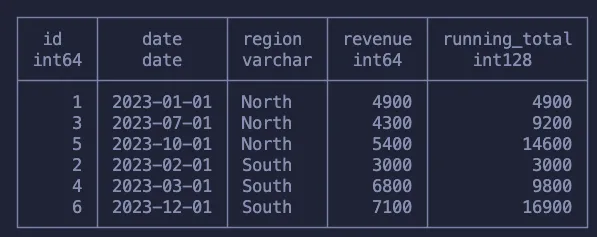
SELECT
*,
RANK() OVER (PARTITION BY region ORDER BY revenue DESC) as rank,
RANK() OVER (ORDER BY revenue DESC) as overall_rank
FROM
sales
ORDER BY region, revenue DESC
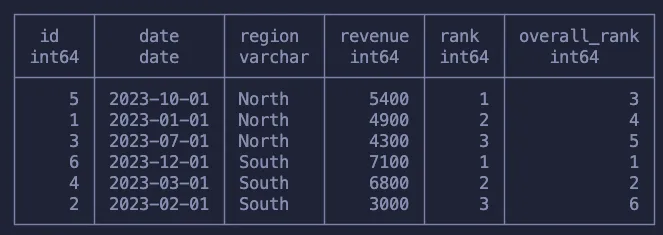
与之前一样,我们使用ORDER BY来指定我们将逐行遍历的顺序,并使用PARTITION BY来指定子组。
第一列对每个地区内的每一行进行排名,这意味着数据集中将有多个“排名第一”的行。第二列计算的是数据集中所有行的排名。
五、前向填充缺失数据
这是一个时不时会出现的问题,要在SQL上解决这个问题,需要大量使用窗口函数。为了解释这个概念,我们将使用一个包含时间戳和温度测量值的不同数据集。我们的目标是用最后一次测量的值填充缺少温度测量值的行。
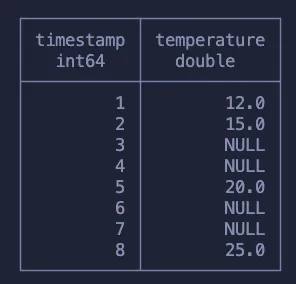
以下是我们期望最终得到的结果:

在开始之前,需要提一下,如果你使用的是Pandas,可以通过运行df.ffill()来简单地解决这个问题,但如果你使用的是SQL,问题就会变得有点棘手。
解决这个问题的第一步是以某种方式将NULL值与前一个非NULL值分组。可能不清楚我们如何做到这一点,但希望大家能清楚的是,这需要一个运行函数。也就是说,它是一个会“逐行遍历”的函数,知道我们何时遇到NULL值和非NULL值。
解决方案是使用COUNT函数,更具体地说,就是计算温度测量值的数量。在以下的查询中,同时运行了一个普通的累加计数和一个针对温度值的计数。
SELECT
*,
COUNT() OVER (ORDER BY timestamp) as normal_count,
COUNT(temperature) OVER (ORDER BY timestamp) as group_count
from sensor

-
在第一次计算中,我们简单地、逐行递增地计算了每一行。
-
在第二次计算中,我们计算了我们遇到的每个温度值的数量,但不计算NULL值。
normal_count列对我们来说是无用的,只是想展示一下运行COUNT的样子。然而,我们的第二个计算,即group_count计算,使我们离解决问题更近了一步!
请注意,这种计数方式确保了在NULL值开始之前的第一个值被计入,然后,每当函数遇到一个NULL值时,不会发生任何操作。这确保了我们用停止测量时的相同计数“标记”了每个后续的NULL值。
接下来,我们现在需要将被标记的第一个值复制到同一组中的所有其他行中。这意味着对于第2组,所有的值都应填充为15.0。
在这里,我们正在使用PARTITION BY进行简单的窗口聚合,当然,这个问题有不止一个答案。
SELECT
*,
FIRST_VALUE(temperature) OVER (PARTITION BY group_count) as filled_v1,
MAX(temperature) OVER (PARTITION BY group_count) as filled_v2
FROM (
SELECT
*,
COUNT(temperature) OVER (ORDER BY timestamp) as group_count
from sensor
) as grouped
ORDER BY timestamp ASC

我们可以使用FIRST_VALUE或MAX来实现我们的目标。唯一的目标是获取第一个非NULL值。由于我们知道每个组都包含一个非NULL值和一堆NULL值,所以这两个函数都可以使用!
这个示例是练习窗口函数的好方法。如果你想尝试类似的挑战,可以尝试添加两个传感器,然后用该传感器的上一个读数向前填充数值。类似于这样的情况:

到目前为止,我们已经了解了关于如何在SQL中使用窗口函数的所有知识,让我们快速回顾一下吧!
六、回顾时间
这是我们学到的内容:
-
我们使用
OVER关键字来编写窗口函数。 -
我们使用
PARTITION BY来指定子组(窗口)。 -
如果我们只提供了
OVER()关键字,我们的窗口就是整个数据集。 -
当我们想要运行一个连续的函数时,我们使用
ORDER BY,这意味着我们的计算将逐行进行。 -
窗口函数在我们想要对数据进行分组聚合,但又想保持数据集的原样时非常有用。
希望这有助于你理解窗口函数的工作原理,并将其应用到你需要解决的问题中。















 451
451











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









