






更新了
一、窗口函数
1. 概述
MySQL8.0版本之后,加入了窗口函数功能,简化了数据分析工作中查询语句的书写。
窗口函数是数据分析工作中必须掌握的工具,在SQL笔试中也是高频考点
窗口函数是类似于可以返回聚合值的函数,例如SUM(),COUNT(),MAX()。但是窗口函数又与普通的聚合函数不同,它不会对结果进行分组,使得输出中的行数与输入中的行数相同。(输出的结果不会只有聚合函数的一行,而是创建一个新的列/字段,每行数据都有该字段的聚合结果)
2. 基本语法
SELECT SUM() OVER(PARTITION BY ___ ORDER BY___) FROM Table 注意:
- 聚合功能:在上述例子中,我们用了SUM(),但是你也可以用COUNT(), AVG()之类的计算功能
- PARTITION BY:你只需将它看成GROUP BY子句,但是在窗口函数中,你要写PARTITION BY
- ORDER BY:ORDER BY和普通查询语句中的ORDER BY没什么不同。注意,输出的顺序要仔细考虑
3. 窗口函数和聚合函数对比
 数据集
数据集
根据男女求GPA的平均值:
聚合函数写法:
SELECT Gender, AVG(GPA) as avg_gpa FROM students GROUP BY Gender;结果:

结果只有两行,只能返回聚合后的结果。
使用窗口函数:对Gerder进行分组,再求平均值
SELECT *, AVG(GPA) OVER (PARTITION BY Gender) as avg_gpa FROM students;结果:
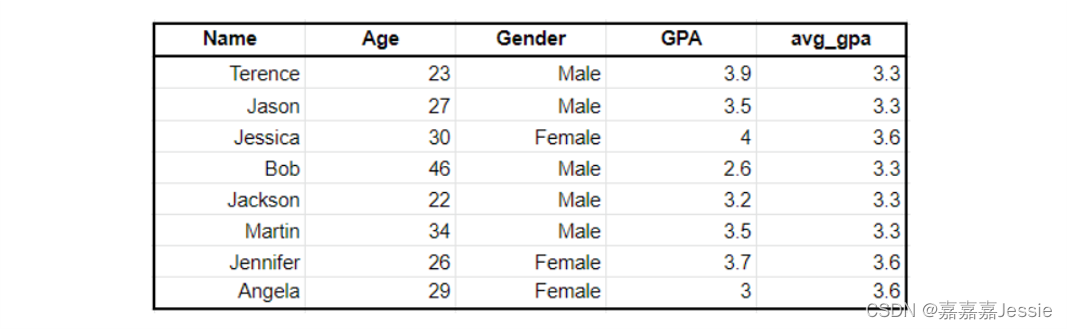
窗口函数结果:不会改变原表的数据,只原来的表上多加了一个字段,并在新字段上显示结果,原来表的数据没有聚合,不会影响原来的数据。
若想得到这样的结果,用我们刚刚提到的聚合函数,然后再将结果join到初始表,但这需要两个步骤。
4. 窗口函数的优点
- 简单
窗口函数更易于使用。在上面的示例中,与使用聚合函数然后合并结果相比,使用窗口函数仅需要多一行就可以获得所需要的结果。
- 快速
这一点与上一点相关,使用窗口函数比使用替代方法要快得多。当你处理成百上千个千兆字节的数据时,这非常有用。
- 多功能性
最重要的是,窗口函数具有多种功能,比如,添加移动平均线,添加行号和滞后数据,等等。
二、窗口函数的基本语法
1. 数据集

2. 窗口函数基本语法
对于窗口的理解: 窗口函数是对表中一组数据进行计算的函数,一组数据跟当前行相关
例如:想计算每三天的销售总金额,就可以使用窗口函数,以当前行为基准,选前一行,后一行,三行一组如下图所示

之所以称之为窗口函数,是因为好像有一个固定大小的窗框划过数据集,滑动一次取一次,对窗口内的数据进行处理。
基本语法:
<window_function> OVER (...)<window_function>: 聚合函数,(`COUNT()`, `SUM()`, `AVG()` 等)rank等排序函数,分析函数等。
OVER(...):窗口函数的窗框通过`OVER(...)` 子句定义,通过`OVER(...)` 定义窗框 (开窗方式和大小)。
注意:over()窗口函数先执行,聚合函数后执行。
三、OVER()基本用法
OVER() 不带参数,意思是所有的数据都在窗口中
SELECT
first_name,
last_name,
salary,
AVG(salary) OVER()
FROM employee;over()所有的数据都在窗口中, avg(salary) 对窗口中的数据求平均工资salary,即对所有人计算平均工资

不改变原表employee的数据,增加一列存储所有人的平均工资(并没有像聚合函数一样只输出一个avg(salary)的聚合解雇)
注意:反引号的使用
在mysql中的sql语句中常常为了避免与系统冲突(关键字/函数名)而给表名加上反引号 `
1. 对over()结果进一步计算
`OVER()`用于将当前行与一个聚合值进行比较,例如,我们可以计算出员工的薪水和平均薪水之间的差。
SELECT
first_name,
last_name,
salary,
AVG(salary) OVER(),
salary - AVG(salary) OVER() as difference -- as后跟别名
FROM employee;结果的最后一列显示了每名员工的工资和平均工资之间的差额,这就是"窗口函数的典型应用场景:将当前行与一组数据的聚合值进行比较"。
嵌套round()函数, `ROUND(price / SUM(price) OVER() , 2)`
SELECT
id,
item,
price,
ROUND(price / SUM(price) OVER() , 2)
FROM purchase
WHERE department_id = 2;
Where 执行的优先级:where子句优先于over()窗口函数,集合函数
先执行where子句,over()窗口函数,聚合函数
注意:别名的使用
-- 错误示范
SELECT
first_name,
last_name,
salary,
AVG(salary) OVER() as `avg_salary`, -- 错误!!!
salary - `avg_salary` OVER() as difference
FROM employee;
首先程序执行才有别名,select中的字段都是同时执行,还没有别名,无法引用
2. over()与count()组合
查询月薪超过4000的员工,并统计所有月薪超过4000的员工数量
select
first_name,
last_name,
salary,
count(id) over()
from employee
where salary>4000;
3. 在一条sql语句中使用两个窗口函数
创建报表,在purchase表基础上,添加平均价格和采购总金额两列
包含如下字段:`id`, `item`, `price`, 平均价格和所有物品总价格
select
id,
item,
price
avg(price) over() as `avg_price`
sum(price) over() as `sum_price`
from purchase;
4. over()的作用范围
department表

select
*,
sum(id) over()
from department
where id <=3;
where先执行,则结果返回6;
如果窗口函数先执行,则结果返回15。

需要注意:先执行 where子句筛选,再执行窗口函数。
在过滤条件where中使用over()
查询部门id为1,2,3三个部门员工的姓名,薪水,和这三个部门员工的平均薪资
SELECT
first_name,
last_name,
salary,
AVG(salary) OVER() as avg
FROM employee
WHERE department_id IN (1, 2, 3);
注意:
SELECT
first_name,
last_name,
salary,
AVG(salary) OVER()
FROM employee
WHERE salary > AVG(salary) OVER();
上面的SQL能否正确执行?
执行上面的SQL时会返回错误信息:3593 - You cannot use the window function 'avg' in this context.', Time: 0.000000s
原因是,窗口函数在WHERE子句之后执行,把窗口函数写在WHERE子句中会导致循环依赖
5. 小结
- 可以使用<window_function> OVER(),对全部查询结果进行聚合计算
- 在WHERE条件执行之后,才会执行窗口函数
- 窗口函数在执行聚合计算的同时还可以保留每行的其它原始信息
- 不能在WHERE子句中使用窗口函数
四、OVER( PARTITION BY )的使用
1. 基本语法
<window_function> OVER (PARTITION BY column1, column2 ... column_n)
`PARTITION BY` 的作用与 `GROUP BY`类似:将数据按照传入的列进行分组,与 `GROUP BY` 的区别是,`PARTITION BY` 不会改变结果的行数。
2. PARTITION BY与GROUP BY区别
① group by是分组函数,partition by是<font color=orange >分析函数</font>
② 在执行顺序上:from > where > group by > having > 窗口函数,而partition by应用在以上关键字之后,可以简单理解为就是在执行完select之后,在所得结果集之上进行partition by分组
③ partition by相比较于group by,能够在保留全部数据的基础上,只对其中某些字段做分组排序(类似excel中的操作),而group by则只保留参与分组的字段和聚合函数的结果(类似excel中的pivot透视表)
3. 例子
数据集:
不同型号火车接班信息表 TRAIN

运营线路表 ROUTE

票价表 TICKET

时刻表 JOURNEY

查询每种类型火车的ID,型号,一等座数量,同型号一等座数量总量
SELECT
id,
model,
first_class_places,
SUM(first_class_places) OVER (PARTITION BY model)
FROM train;

如果用`GROUP BY`实现上面相同的需求,我们需要通过子查询将结果与原始表`JOIN` , 对比起来,使用窗口函数的实现更加简洁。
SELECT
id,
train.model,
first_class_places,
c.sum
FROM
train
JOIN ( SELECT model, SUM( first_class_places ) AS sum FROM train GROUP BY model ) AS c
ON train.model = c.model
4. PARTITION BY 传入多个字段
需求:查询每天,每条线路速的最快车速
查询结果包括如下字段:线路ID,日期,车型,相同线路每天的最快车速
SELECT
journey.id,
journey.date,
train.model,
train.max_speed,
MAX(max_speed) OVER(PARTITION BY route_id, date)
FROM journey
JOIN train
ON journey.train_id = train.id;

五、排序函数
1. 通过窗口函数实现排序
<ranking function> OVER (ORDER BY <order by columns>)
游戏信息表 game

游戏销售表 game_purchase

2. rank()函数(下面的内容待修改)
RANK() OVER (ORDER BY ...)`RANK()`会返回每一行的等级(序号)
`ORDER BY`对行进行排序将数据按升序或降序排列
` RANK()OVER(ORDER BY ...)`是一个函数,与`ORDER BY` 配合返回序号
总结:<font color=orange >有并列不连续</font>
比如:小王 95 1
小李 95 1
小陈 90 3 (因为有并列,且并不连续,为3)
SELECT
name,
platform,
editor_rating,
RANK() OVER(ORDER BY editor_rating) as rank_
FROM game;
3. dense_rank()函数
RANK() 函数返回的序号,可能会出现不连续的情况
如果想在有并列情况发生的时候仍然返回连续序号可以使用 `dense_rank()函数`,总结:<font color=orange >有并列且连续.</font>
比如:小王 95 1
小李 95 1
小陈 90 2 (因为有并列,且连续,为2)
SELECT
name,
platform,
editor_rating,
DENSE_RANK() OVER(ORDER BY editor_rating) as rank_
FROM game;
4. row_number()函数:返回行号
想获取排序之后的序号,也可以通过ROW_NUMBER() 来实现,从名字上就能知道,意思是返回行号。
<font color=orange >这个行号是不重复的!</font>(相同值的rank排序的序号相同,但是row_number返回的是排序后的行号,绝对不同。)
SELECT
name,
platform,
editor_rating,
ROW_NUMBER() OVER(ORDER BY editor_rating) `row_number`
FROM game;
> 小结:
>
> rank() 有并列不连续
>
> dense_rank() 有并列且连续
>
> row_number() 返回唯一的行号
5. 窗口函数中:rank()与order by多字段排序
在列表中查找比较新,且安装包体积较小的游戏(`released` ,`size`)
SELECT
name,
genre,
editor_rating,
RANK() OVER(ORDER BY released DESC, size ASC) `rank`
FROM game;

6. 窗口函数外:使用rank() 与 order by
对比:
SELECT
name,
RANK() OVER (ORDER BY editor_rating) `rank`
FROM game;

SELECT
name,
RANK() OVER (ORDER BY editor_rating) `rank`
FROM game
ORDER BY size DESC;
对比上面的结果,最终的结果是按size排序。
窗口函数先执行,order by后执行。
执行顺序:from > where > group by > having > 窗口函数 > order by
7. NTILE()函数
`NTILE(X)`函数将数据分成X组,并给每组分配一个数字(1,2,3....)
SELECT
name,
genre,
editor_rating,
NTILE(3) OVER (ORDER BY editor_rating DESC)
FROM game;
NTILE(3) OVER (ORDER BY editor_rating DESC) 是根据editor_rating的值排序后分成三个桶,编号为1,2,3
通过 `NTILE(3)` 我们根据`editor_rating` 的高低,将数据分成了三组,并且给每组指定了一个标记
1 这一组是评分最高的
3 这一组是评分较低的
2 这一组属于平均水平
注意:如果所有的数据不能被平均分组,那么有些组的数据会多一条,数据条目多的组会排在前面

8. with 语句 分层查询:查询排名第几的...
求排序第几的,一般都是用rank()、dense_rank()函数等排序函数排序,把序号字段添加到表上,再用with分层查询,select后用where子句找出具体排第几的。(一般用dense_rank()因为有连续。)
例如:查找打分排名第二的游戏
WITH ranking AS (
SELECT
name,
DENSE_RANK() OVER(ORDER BY editor_rating DESC) AS `rank`
FROM game
)
SELECT name
FROM ranking
WHERE `rank` = 2;with 表别名 as ( 第一层select,结果用表别名表示 ) 在上面的结果下再select
9. 小结
最基本的排序函数: `RANK() OVER(ORDER BY column1, column2...)`
通过排序获取序号的函数介绍了如下三个:
- RANK() – 返回排序后的序号 rank ,有并列的情况出现时序号不连续
- DENSE_RANK() – 返回 连续 序号
- ROW_NUMBER() – 返回连续唯一的行号,与排序`ORDER BY` 配合返回的是连续不重复的序号
NTILE(x) – 将数据分组,并为每组添加一个相同的序号
获取排序后,指定位置的数据(第一位,第二位)可以通过如下
WITH ranking AS
(SELECT
RANK() OVER (ORDER BY col2) AS RANK,
col1
FROM table_name)
SELECT col1
FROM ranking
WHERE RANK = place1;














 111
111











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









