







今年6月底CMU和谷歌新提出了一个预训练模型,在效果和算力上都远远超过18年年底发表的BERT预训练和模型,也优于今年年初提出的GPT-2预训练模型。但该文章主要从Autoregressive(AR) lanuage modeling 和 Autoencoding(AE) pre-training 这两个角度入手进行比较,并结合他们各自的优点,规避他们的缺点,进而了一种泛化自回归语言建模方法。
在正式谈谈自己关于这篇文章的理解之前,先post一些优秀的专栏和个人对此的评价:
part one:from 机器之心
20项任务全面碾压BERT,CMU全新XLNet预训练模型屠榜(已开源)
BERT 带来的影响还未平复,CMU 与谷歌大脑提出的 XLNet 在 20 个任务上超过了 BERT 的表现,并在 18 个任务上取得了当前最佳效果。令人激动的是,目前 XLNet 已经开放了训练代码和大型预训练模型,这又可以玩一阵了~
2018 年,谷歌发布了基于双向 Transformer 的大规模预训练语言模型 BERT,刷新了 11 项 NLP 任务的最优性能记录,为 NLP 领域带来了极大的惊喜。很快,BERT 就在圈内普及开来,也陆续出现了很多与它相关的新工作。
BERT 带来的震撼还未平息,今年6月底又一全新模型出现:来自卡耐基梅隆大学(CMU)与谷歌大脑(Google Brain)的研究者提出新型预训练语言模型 XLNet,在 SQuAD、GLUE、RACE 等 20 个任务上全面超越 BERT。
而此论文的作者也都是我们熟知的研究者:共同一作为杨植麟(曾经的清华学霸,现在 CMU 读博)与 Zihang Dai(CMU 博士),此外还包括 CMU 教授 Yiming Yang,CMU 语言技术中心的总负责人 Jaime Carbonell,CMU 教授、苹果 AI 负责人 Russ Salakhutdinov,谷歌大脑的创始成员、AutoML 的缔造者之一 Quoc Le。
那么,相比于 BERT,XLNet 有哪些提升呢?
作者表示,BERT 这样基于去噪自编码器的预训练模型可以很好地建模双向语境信息,性能优于基于自回归语言模型的预训练方法。然而,由于需要 mask 一部分输入,BERT 忽略了被 mask 位置之间的依赖关系,因此出现预训练和微调效果的差异(pretrain-finetune discrepancy)。
基于这些优缺点,该研究提出了一种泛化的自回归预训练模型 XLNet。XLNet 可以:1)通过最大化所有可能的因式分解顺序的对数似然,学习双向语境信息;2)用自回归本身的特点克服 BERT 的缺点。此外,XLNet 还融合了当前最优自回归模型 Transformer-XL 的思路。
最终,XLNet 在 20 个任务上超过了 BERT 的表现,并在 18 个任务上取得了当前最佳效果(state-of-the-art),包括机器问答、自然语言推断、情感分析和文档排序。
以前超越 BERT 的模型很多都在它的基础上做一些修改,本质上模型架构和任务都没有太大变化。但是在这篇新论文中,作者从自回归(autoregressive)和自编码(autoencoding)两大范式分析了当前的预训练语言模型,并发现它们虽然各自都有优势,但也都有难以解决的困难。为此,研究者提出 XLNet,并希望结合大阵营的优秀属性。
AR 与 AE 两大阵营
无监督表征学习已经在自然语言处理领域取得了巨大的成功。在这种理念下,很多研究探索了不同的无监督预训练目标,其中,自回归(AR)语言建模和自编码(AE)成为两个最成功的预训练目标。
AR 语言建模旨在利用自回归模型估计文本语料库的概率分布。由于 AR 语言模型仅被训练用于编码单向语境(前向或后向),因而在深度双向语境建模中效果不佳。而下游语言理解任务通常需要双向语境信息。这导致 AR 语言建模无法实现有效预训练。
相反,基于 AE 的预训练模型不会进行明确的密度估计,而是从残缺的输入中重建原始数据。一个著名的例子就是 BERT。给出输入 token 序列,BERT 将一部分 token 替换为特殊符号 [MASK],随后训练模型从残缺版本恢复原始的 token。由于密度估计不是目标的一部分,BERT 允许使用双向语境进行重建。
但是,模型微调时的真实数据缺少 BERT 在预训练期间使用的 [MASK] 等人工符号,这导致预训练和微调之间存在差异。此外,由于输入中预测的 token 是被 mask 的,因此 BERT 无法像自回归语言建模那样使用乘积法则(product rule)对联合概率进行建模。
换言之,给定未 mask 的 token,BERT 假设预测的 token 之间彼此独立,这被过度简化为自然语言中普遍存在的高阶、长期依赖关系。
两大阵营间需要新的 XLNet
现有的语言预训练目标各有优劣,这篇新研究提出了一种泛化自回归方法 XLNet,既集合了 AR 和 AE 方法的优势,又避免了二者的缺陷。
首先,XLNet 不使用传统 AR 模型中固定的前向或后向因式分解顺序,而是最大化所有可能因式分解顺序的期望对数似然。由于对因式分解顺序的排列操作,每个位置的语境都包含来自左侧和右侧的 token。因此,每个位置都能学习来自所有位置的语境信息,即捕捉双向语境。
其次,作为一个泛化 AR 语言模型,XLNet 不依赖残缺数据。因此,XLNet 不会有 BERT 的预训练-微调差异。同时,自回归目标提供一种自然的方式,来利用乘法法则对预测 token 的联合概率执行因式分解(factorize),这消除了 BERT 中的独立性假设。
除了提出一个新的预训练目标,XLNet 还改进了预训练的架构设计。
受到 AR 语言建模领域最新进展的启发,XLNet 将 Transformer-XL 的分割循环机制(segment recurrence mechanism)和相对编码范式(relative encoding)整合到预训练中,实验表明,这种做法提高了性能,尤其是在那些包含较长文本序列的任务中。
简单地使用 Transformer(-XL) 架构进行基于排列的(permutation-based)语言建模是不成功的,因为因式分解顺序是任意的、训练目标是模糊的。因此,研究人员提出,对 Transformer(-XL) 网络的参数化方式进行修改,移除模糊性。
目标:排列语言建模(Permutation Language Modeling)
从上面的比较可以得出,AR 语言建模和 BERT 拥有其自身独特的优势。我们自然要问,是否存在一种预训练目标函数可以取二者之长,同时又克服二者的缺点呢?
研究者借鉴了无序 NADE 中的想法,提出了一种序列语言建模目标,它不仅可以保留 AR 模型的优点,同时也允许模型捕获双向语境。具体来说,一个长度为 T 的序列 x 拥有 T! 种不同的排序方式,可以执行有效的自回归因式分解。从直觉上来看,如果模型参数在所有因式分解顺序中共享,那么预计模型将学习从两边的所有位置上收集信息。
为了提供一个完整的概览图,研究者展示了一个在给定相同输入序列 x(但因式分解顺序不同)时预测 token x_3 的示例,如下图所示:

模型架构:对目标感知表征的双流自注意力
对于参数化,标准 Transformer 架构存在两个互相矛盾的要求:1)预测 token 应该仅使用位置
而不是内容
,不然该目标函数就变得不重要了;2)为了预测另一个 token
,其中 j>t, 应该编码内容
,以提供完整的上下文信息。为了解决这一矛盾,该研究提出使用两个隐藏表征的集合,而不是只用其中一个。
这两个隐藏表征即内容表征 和 Query 表征
,下图 2 的 a、b 分别展示了这两种表征的学习。其中内容表征与 Transforme 的隐藏状态类似,它将同时编码输入本身的内容及上下文信息。Query 表征仅能获取上下文信息及当前的位置,它并不能获取当前位置的内容。

图 2:(a)内容流注意力,与标准自注意力相同;(b)Query 流注意力,没有获取内容 的信息;(c)利用双流注意力的排列语言建模概览图。
由于目标函数适用于 AR 框架,研究者整合了当前最佳的 AR 语言模型——Transformer-XL 到预训练框架中,并将其体现在方法名字中。具体来说,他们借鉴了 Transformer-XL 中的两项重要技术——相对位置编码范式和分割循环机制。现在,结合双流注意力和 Transformer-XL 的改进,上面图 2(c) 展示了最终的排列语言建模架构。
实验结果
和 BERT 相同,研究者使用了 BooksCorpus 和英文维基百科作为预训练数据,文本量达到 13GB。此外,论文还使用了 Giga 5(16GB 文本),ClueWeb 2012-B 和 Common Crawl 数据集进行预训练。他们在后两个数据集上使用了启发式搜索过滤掉较短或低质量的文本,最终分别剩余 19 GB 和 78 GB 文本。
这项工作中的最大模型 XLNet-Large 拥有与 BERT-Large 相同的架构超参数,因此模型大小也相似。研究者在 512 块 TPU v3 上借助 Adam 优化器对 XLNet-Large 训练 500K 步,学习率线性下降,batch 大小为 2048,训练时间为 2.5 天。

表 2:单模型的 XLNet 在 SQuAD1.1 数据集上的表现分别比人类和当前最好模型超过了 7.6EM 和 2.5EM。

表 3:在一些文本分类数据集的测试集上与当前最优的误差率进行对比。所有的 BERT 和 XLNet 结果都通过同样模型大小的 24 层架构(相当于 BERT-Large)获得。

表 4:GLUE 的对比,∗表示使用集合,†表示多任务行的单任务结果。所有结果都基于同样模型大小的 24 层架构获得。表格最高一行是与 BERT 的直接对比,最低一行是和公开排行榜上最佳效果的对比。

表 5:在 ClueWeb09-B 测试集(一项文档排名任务)上对比 XLNet 和当前最优方法的性能。† 表示该研究所做的实现。

表 6:控制变量测试。其中 BERT 在 RACE 上的结果来自论文 [39]。研究者使用 BERT 的官方实现在其他数据集上运行,且它具备与 XLNet 相同的超参数搜索空间。K 是控制优化难度的超参数。所有模型都在相同数据上预训练而成。
part two: 从算力和时间消耗方面来考虑近两年这些屠榜的预训练模型
XLNet训练成本6万美元,顶5个BERT,大模型「身价」惊人 作者:思源、张倩
数据、算法和计算力是推动人工智能发展的三大要素。随着高性能 GPU、TPU 的出现,人们似乎正在将算力的利用推向极致。
去年 10 月,「最强 NLP 预训练模型」Bert 问世,横扫 11 项 NLP 任务记录。但仅仅过了 8 个月,这一「最强」模型就遭到 XLNet 的碾压,后者在 20 项任务上超越前者,又一次刷新 NLP 预训练模型的各项记录。
但除了「最强」之外,这些模型似乎也是「最贵」的。
早在 Bert 问世之时,深度好奇 CTO 吕正东就曾表示:「BERT 是一个 google 风格的暴力模型,暴力模型的好处是验证概念上简单模型的有效性,从而粉碎大家对于奇技淫巧的迷恋;但暴力模型通常出现的一个坏处是'there is no new physics',我相信不少人对 BERT 都有那种『我也曾经多多少少想过类似的事情』的感觉,虽然也仅仅是想过而已。」
无一例外,碾压 Bert 的 XLNet 也没有走出「暴力美学」的范畴,普通研究者看了其训练成本之后,只能说声「打扰了……」
那么,令普通研究者望而却步的计算力到底有多贵?机器之心从原论文出发统计了大模型的训练成本,下面让我们仔细算一算这笔账。
1. 语言模型
- BERT:1.2 万美元
- GPT-2:4.3 万美元
- XLNet:6.1 万美元
2. 高分辨率 GAN
- BigGAN:2.5 万美元
- StyleGAN:0.3 万美元

计算力到底有多贵?
目前训练神经网络主要还是使用 GPU 或 TPU,先不说英伟达的各种高端 GPU 有多贵,云计算上的高性能计算也不便宜。我们以谷歌云为例,Tesla V100 每小时 2.48 美元、Tesla P100 每小时 1.46 美元,谷歌 Colab 免费提供的 Tesla T4 GPU 每小时也要 0.95 美元。
对于大模型来说,最合理的计算资源还是 TPU,因为它能大大降低训练时间,且成本换算下来还比较有优势。TPU 的费用如下图所示:
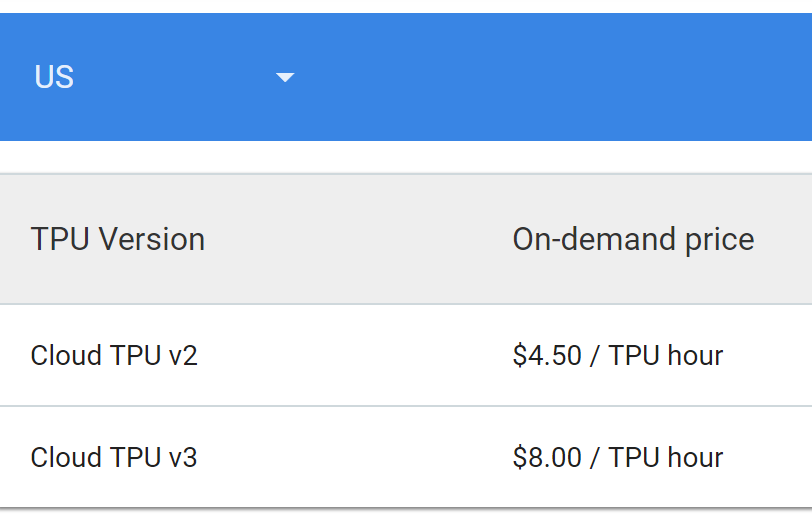
注意这里还有一些换算关系,TPU 数量并不能简单地通过一块两块的方式统计。从大到小可以分为 Pod、Cloud TPU device、TPU Chips 和 Cores。上面的价格是一个 Cloud TPU device 的费用,它包含 4 块 TPU Chip,且每块 TPU Chip 有两个核心(Core)。
TPU v2 和 TPU v3 的计数方式差异主要体现在 Pod 上,一个 Cloud TPU v2 Pod 有 64 个 Cloud TPU,即 512 个 TPU 核心。而一个 Cloud TPU v3 Pod 有 256 个 Cloud TPU,即 2048 个 TPU 核心。一个 Pod 中的所有 TPU 设备都是连在一起的,所以它们天然可以联合做模型训练或推断。
因为论文中描述的 TPU 单位是不同的,我们会最终转化为 Cloud TPU,并统计训练大模型所花费的成本。

一个完整的 Cloud TPU v3 Pod。
为什么说 TPU 性价比高于 GPU
很多读者知道 TPU 性价比高,但不太了解到底高多少。在下图中我们可以看到各种设备训练相同 ResNet-50 所需要的时间,其中红色数字表示芯片数量。

如上图所示,一个 Cloud TPU v3 训练 ResNet 需要 183 分钟,它的价格为 8$/h;8 块 Tesla V100 训练 ResNet 需要 137 分钟,它的价格为 19.84$/h。这样算起来,TPU v3 总共费用需要 24.4 美元,Tesla V100 需要 45.57 美元。不过这样计算也有一丢丢不公平,因为 TPU v3 慢了 47 分钟,时间也是一种成本。
自然语言到视觉,大模型的训练费用越来越高,但具体高到什么程度很少有量化对比。如下在计算不同模型的单次训练费用时,因为调参之类的费用没办法统计,所以我们就忽略了。此外,因为 GPT-2 原论文中没有描述训练配置,论文作者只在 Reddit 中简要描述一段,所以我们以 Reddit 中的数据为准。
BERT
原论文中描述,大型 BERT 模型在 16 个 Cloud TPU 上需要训练 4 天:
Training of BERT_BASE was performed on 4 Cloud TPUs in Pod configuration (16 TPU chips total).13 Training of BERT_LARGE was performed on 16 Cloud TPUs (64 TPU chips total). Each pretraining took 4 days to complete.
现在我们来算一下成本,16 个 Cloud TPU v3 总训练成本为 16×8×24×4=12288 美元。有研究者在 Reddit 中回复作者,他们可以使用更便宜的抢占式(Preemptible)TPU 训练模型,那样成本约为 16×2.4×24×4=3686.4 美元。不过一般的 TPU 优先于抢占式 TPU,如果它们需要计算资源,可以暂停抢占式对资源的调用。
BERT 的作者在 Reddit 上也表示预训练的计算量非常大,Jacob 说:「OpenAI 的 Transformer 有 12 层、768 个隐藏单元,他们使用 8 块 P100 在 8 亿词量的数据集上训练 40 个 Epoch 需要一个月,而 BERT-Large 模型有 24 层、2014 个隐藏单元,它们在有 33 亿词量的数据集上需要训练 40 个 Epoch,因此在 8 块 P100 上可能需要 1 年?16 个 Cloud TPU 已经是非常大的计算力了。」
为了做对比,这里统一用一般的 TPU 价格计算成本,因此 BERT 训练一次大概需要 1.23 万美元。
GPT-2
今年另一个非常受关注的语言模型就是 GPT-2 了,它充分展示了什么才算大模型。我们可以理解为,GPT-2 就是在 GPT 的基础上放大十多倍,它需要的算力应该比 BERT 还大。堆了这么多算力与数据,GPT-2 的效果确实惊人,它根据一个前提就能从容地把故事编下去。
但是在 GPT-2 原论文中,我们没找到关于算力的描述,只找到了疑似论文作者的描述。他表明 GPT-2 用了 64 个 Cloud TPU v3,训练了一周多一点。
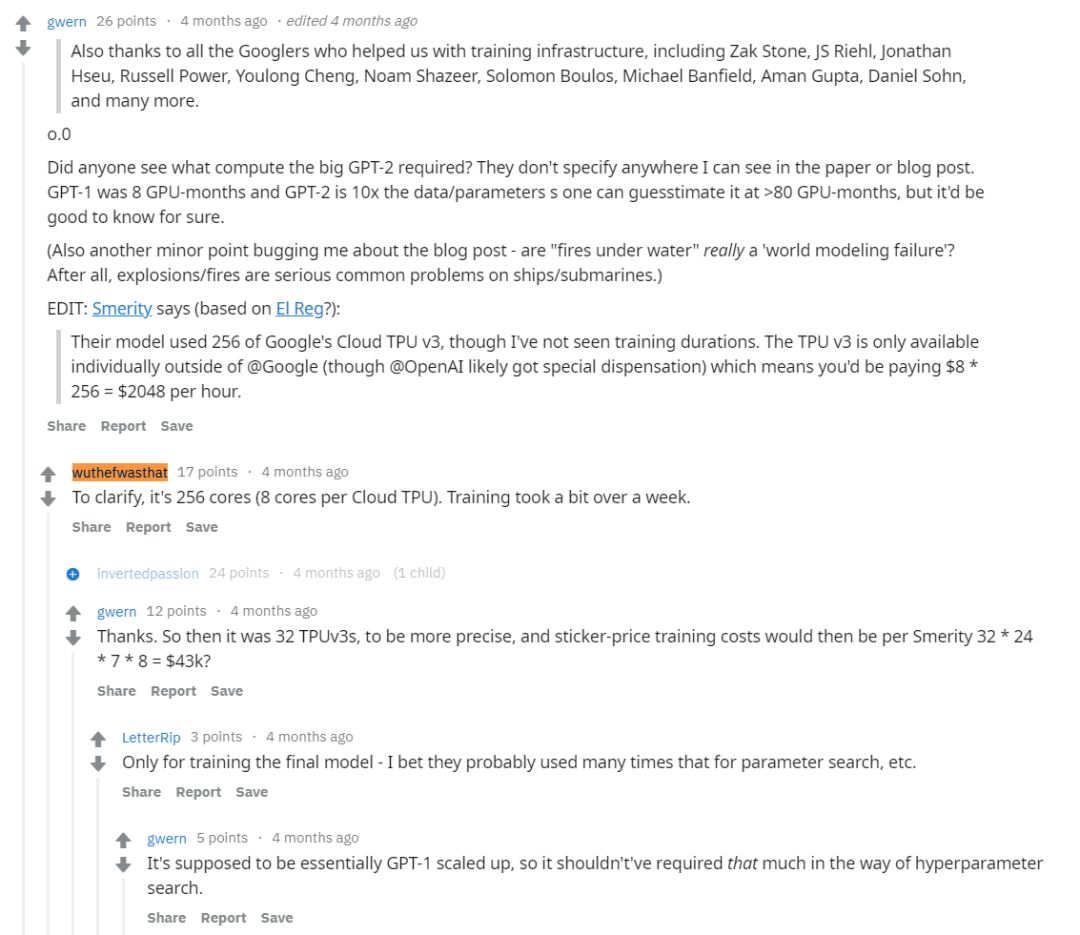
如果按这个数据,那么训练成本为 32×8×24×7=43008 美元,这个成本已经是训练 BERT 的 3 到 4 倍了。
XLNet
2018 年,谷歌发布大规模预训练语言模型 BERT ,为 NLP 领域带来了极大的惊喜。但最近,Quoc V. Le 等研究者提出的 XLNet 在 20 个任务上超过了 BERT 的表现,并在 18 个任务上取得了当前最佳效果。既然效果这么好,那么它的成本会不会也超过 BERT?
在原论文中,作者表示 XLNet 大模型在 128 个 Cloud TPU v3 下需要训练 2 天半:
We train XLNet-Large on 512 TPU v3 chips for 500K steps with an Adam optimizer, linear learning rate decay and a batch size of 2048, which takes about 2.5 days.
这样算起来,128×8×24×2.5=61440 美元,没想到 XLNet 训练一次的费用比 GPT-2 还高,达到了 BERT 的 5 倍。既然成本这么高,以后可以考虑用预训练的 XLNet 代替 BERT 了。
在看了 XLNet 的算力成本之后,有开发者感叹:「谢天谢地我不在 NLP 领域工作,要是让我去说服老板训练一个模型花 6 万多美元,而且还不能保证这个模型一定好用,我觉得我会哭……」
那么问题来了,NLP 算力烧钱,视觉模型就省钱吗?
我们拿视觉领域比较有代表性的大模型 BigGAN 和 StyleGAN 来算一笔账。
BigGAN
视觉模型中,常见高成本任务就是训练高分辨率的 GAN 了。在去年 BigGAN 中,研究者表示他们训练 512×512 像素的图像需要 64 个 Cloud TPU v3,训练 24 到 48 个小时:
We train on a Google TPU v3 Pod, with the number of cores proportional to the resolution: 128 for 128×128, 256 for 256×256, and 512 for 512×512. Training takes between 24 and 48 hours for most models.
如果我们用最大训练时间 48 小时为基准,那么训练成本为 64×8×48=24576 美元。是的,BigGAN 的训练成本也比 BERT 高,大约是它的两倍左右。
StyleGAN
最后,我们统计一下 StyleGAN 的训练成本,因为这篇论文是英伟达提出来的,所以用的是 Tesla V100。该论文使用的 FFHQ 数据集由 1024×1024 的人脸图像组成,模型使用 8 张 Tesla V100 需要训练一星期:
Our training time is approximately one week on an NVIDIA DGX-1 with 8 Tesla V100 GPUs.
这里我们按照谷歌云的价格计算总成本,从而更好地做对比。总体而言,训练成本为 8×2.48×24×7=3333.12 美元。可能因为数据集仅限于人脸,StyleGAN 的成本要比 BigGAN 低很多。
在算完算力这笔账之后,我们可以得出一个结论:以谷歌、Facebook 等巨头为首的大型公司似乎才玩得起这种大模型,这种算力上的碾压是普通研究者无法抗衡的。那么,无法获得这种大规模算力支持的普通研究者路在何方?他们要怎样才能取得研究突破?
在这一问题上,致力于 AI 和游戏研究的纽约大学副教授 Julian Togelius 给出的答案是:不走寻常路(By being weird)。
他解释说,「那些公司虽然规模庞大,但它们也痴迷于保持自己的灵活性。其中一些公司在一定程度上取得了成功,但它们不敢像一个疯疯癫癫的教授一样特立独行。一个只有几个学生和几台电脑的教授永远无法在直接竞争中抗衡 DeepMind 和 FAIR。但我们可以去尝试那些看起来完全讲不通的方法,或者去破解那些没有人想要去尝试解决的问题(因为那些问题看起来不像问题)。」
Julian Togelius 教授还以自己为例,证明了这种做法的有效性。他表示,自己在研究生涯中做的那些有用、有价值的事情往往都是去解决一些别人没有想到要去解决的问题,或者尝试一些原本看起来行不通的方法,最后的结果都出乎自己的预料。
对于 Togelius 教授的观点,有人表示支持,并指出很多创业公司就是靠「不走寻常路」才建立了竞争优势。
但也有人提出了质疑,认为 Julian Togelius 教授提出的观点可能存在很大的「幸存者偏差」。这位质疑者认为,我们不应该不顾别人阻拦就一头扎进某个问题。他认为,我们正在推行一种文化,即鼓励人们去做自己认为对的事情,哪怕所有人都告诉他不要去做。虽然有时候一意孤行会取得成果,但鼓励大家都这么做并不合适,因为只有一小部分人最后会取得成功。ta 还引用了 Yoshua Bengio 在采访时说过的一句话:「光有自信还不够,你可能会因为自信而犯错。」
当然,对于 Togelius 教授的建议,我们要理性看待。无论该建议是否可行,他都为我们做了一个很好的榜样,说明算力不等于一切。
正如有些 reddit 评论者所指出的,那些获得最佳论文奖项的研究多数是用中小级别计算机就能完成的,不需要谷歌级别的算力。因此,普通研究者要取得突破,算力可能从来都不是真正的限制。
参考链接:https://www.reddit.com/r/MachineLearning/comments/c2pfgb/d_how_can_you_do_great_ai_research_when_you_dont/
https://www.reddit.com/r/MachineLearning/comments/c59ikz/r_it_costs_245000_to_train_the_xlnet_model512_tpu/
https://www.reddit.com/r/MachineLearning/comments/9nfqxz/r_bert_pretraining_of_deep_bidirectional/















 451
451











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









